 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIs Text All You Need? Text as a Universal Information Bottleneck for Speech LLMs
Jun 08, 2026Large language models (LLMs) provide a powerful reasoning backbone for speech understanding, but integrating continuous acoustic signals into a frozen LLM remains challenging. Existing speech-to-LLM interfaces typically operate at two extremes: either enforcing near-discrete token alignment, which benefits transcription but loses paralinguistic information, or learning unconstrained continuous representations, which can drift away from the LLM's input space and degrade autoregressive decoding. In this work, we propose Convex Gate (C-Gate), a speech-to-LLM bridge that constrains all speech representations to lie within the LLM's input embedding manifold with an architectural convex-hull constraint. Concretely, each frame is represented as a convex combination of token embeddings, ensuring compatibility with the pretrained LLM while preserving continuous expressivity. Across automatic speech recognition (ASR) and emotion recognition, C-Gate achieves strong joint performance, improving LibriSpeech WER by up to 48.7% relative while matching or exceeding single-task emotion accuracy. Beyond performance, our analysis reveals a key insight: information is not carried by discrete token identities, but by time-resolved trajectories in the embedding space. Causal interventions confirm that both the trajectory structure and alignment to the pretrained embedding manifold are critical for performance. These results suggest that geometry, rather than token discreteness, is the fundamental design factor in speech-to-LLM interfaces, and provide a controlled regime for studying multimodal integration in frozen LLMs. We release the checkpoint, per-sample outputs, mechanism dumps, and intervention suite for replication.
Retrospective Harness Optimization: Improving LLM Agents via Self-Preference over Trajectory Rollouts
Jun 04, 2026AI agents rely on a harness of skills, tools, and workflows to solve complex problems. Continually improving this harness is essential for adapting to new tasks. However, existing optimization methods typically require ground-truth validation sets, yet such labeled data is difficult to acquire in practical deployment settings. To address this problem, we introduce Retrospective Harness Optimization (RHO), a self-supervised method that optimizes the agent harness using only past trajectories. Specifically, RHO selects a diverse coreset of challenging tasks from past trajectories and re-solves them in parallel. The agent analyzes these rollouts using self-validation and self-consistency, then generates candidate harness updates and selects the most effective one by its own pairwise self-preference. We evaluate RHO across three diverse domains, spanning software engineering, technical work, and knowledge work. Notably, a single optimization round improves the pass rate on SWE-Bench Pro from 59% to 78% without any external grading. Furthermore, our analysis demonstrates that RHO effectively targets prior failure modes. As a result, the optimized harness alters the agent's behavior patterns and sustains higher accuracy during long-horizon sessions.
DeepRefine: Agent-Compiled Knowledge Refinement via Reinforcement Learning
May 11, 2026Agent-compiled knowledge bases provide persistent external knowledge for large language model (LLM) agents in open-ended, knowledge-intensive downstream tasks. Yet their quality is systematically limited by \emph{incompleteness}, \emph{incorrectness}, and \emph{redundancy}, manifested as missing evidence or cross-document links, low-confidence or imprecise claims, and ambiguous or coreference resolution issues. Such defects compound under iterative use, degrading retrieval fidelity and downstream task performance. We present \textbf{DeepRefine}, a general LLM-based reasoning model for \emph{agent-compiled knowledge refinement} that improves the quality of any pre-constructed knowledge bases with user queries to make it more suitable for the downstream tasks. DeepRefine performs multi-turn interactions with the knowledge base and conducts abductive diagnosis over interaction history, localizes likely defects, and executes targeted refinement actions for incremental knowledge base updates. To optimize refinement policies of DeepRefine without gold references, we introduce a Gain-Beyond-Draft (GBD) reward and train the reasoning process end-to-end via reinforcement learning. Extensive experiments demonstrate consistent downstream gains over strong baselines.
M$^\star$: Every Task Deserves Its Own Memory Harness
Apr 10, 2026Large language model agents rely on specialized memory systems to accumulate and reuse knowledge during extended interactions. Recent architectures typically adopt a fixed memory design tailored to specific domains, such as semantic retrieval for conversations or skills reused for coding. However, a memory system optimized for one purpose frequently fails to transfer to others. To address this limitation, we introduce M$^\star$, a method that automatically discovers task-optimized memory harnesses through executable program evolution. Specifically, M$^\star$ models an agent memory system as a memory program written in Python. This program encapsulates the data Schema, the storage Logic, and the agent workflow Instructions. We optimize these components jointly using a reflective code evolution method; this approach employs a population-based search strategy and analyzes evaluation failures to iteratively refine the candidate programs. We evaluate M$^\star$ on four distinct benchmarks spanning conversation, embodied planning, and expert reasoning. Our results demonstrate that M$^\star$ improves performance over existing fixed-memory baselines robustly across all evaluated tasks. Furthermore, the evolved memory programs exhibit structurally distinct processing mechanisms for each domain. This finding indicates that specializing the memory mechanism for a given task explores a broad design space and provides a superior solution compared to general-purpose memory paradigms.
A Decade-Scale Benchmark Evaluating LLMs' Clinical Practice Guidelines Detection and Adherence in Multi-turn Conversations
Mar 26, 2026Clinical practice guidelines (CPGs) play a pivotal role in ensuring evidence-based decision-making and improving patient outcomes. While Large Language Models (LLMs) are increasingly deployed in healthcare scenarios, it is unclear to which extend LLMs could identify and adhere to CPGs during conversations. To address this gap, we introduce CPGBench, an automated framework benchmarking the clinical guideline detection and adherence capabilities of LLMs in multi-turn conversations. We collect 3,418 CPG documents from 9 countries/regions and 2 international organizations published in the last decade spanning across 24 specialties. From these documents, we extract 32,155 clinical recommendations with corresponding publication institute, date, country, specialty, recommendation strength, evidence level, etc. One multi-turn conversation is generated for each recommendation accordingly to evaluate the detection and adherence capabilities of 8 leading LLMs. We find that the 71.1%-89.6% recommendations can be correctly detected, while only 3.6%-29.7% corresponding titles can be correctly referenced, revealing the gap between knowing the guideline contents and where they come from. The adherence rates range from 21.8% to 63.2% in different models, indicating a large gap between knowing the guidelines and being able to apply them. To confirm the validity of our automatic analysis, we further conduct a comprehensive human evaluation involving 56 clinicians from different specialties. To our knowledge, CPGBench is the first benchmark systematically revealing which clinical recommendations LLMs fail to detect or adhere to during conversations. Given that each clinical recommendation may affect a large population and that clinical applications are inherently safety critical, addressing these gaps is crucial for the safe and responsible deployment of LLMs in real world clinical practice.
CARE: Towards Clinical Accountability in Multi-Modal Medical Reasoning with an Evidence-Grounded Agentic Framework
Mar 02, 2026Large visual language models (VLMs) have shown strong multi-modal medical reasoning ability, but most operate as end-to-end black boxes, diverging from clinicians' evidence-based, staged workflows and hindering clinical accountability. Complementarily, expert visual grounding models can accurately localize regions of interest (ROIs), providing explicit, reliable evidence that improves both reasoning accuracy and trust. In this paper, we introduce CARE, advancing Clinical Accountability in multi-modal medical Reasoning with an Evidence-grounded agentic framework. Unlike existing approaches that couple grounding and reasoning within a single generalist model, CARE decomposes the task into coordinated sub-modules to reduce shortcut learning and hallucination: a compact VLM proposes relevant medical entities; an expert entity-referring segmentation model produces pixel-level ROI evidence; and a grounded VLM reasons over the full image augmented by ROI hints. The VLMs are optimized with reinforcement learning with verifiable rewards to align answers with supporting evidence. Furthermore, a VLM coordinator plans tool invocation and reviews evidence-answer consistency, providing agentic control and final verification. Evaluated on standard medical VQA benchmarks, our CARE-Flow (coordinator-free) improves average accuracy by 10.9% over the same size (10B) state-of-the-art (SOTA). With dynamic planning and answer review, our CARE-Coord yields a further gain, outperforming the heavily pre-trained SOTA by 5.2%. Our experiments demonstrate that an agentic framework that emulates clinical workflows, incorporating decoupled specialized models and explicit evidence, yields more accurate and accountable medical AI.
NGDB-Zoo: Towards Efficient and Scalable Neural Graph Databases Training
Feb 25, 2026Neural Graph Databases (NGDBs) facilitate complex logical reasoning over incomplete knowledge structures, yet their training efficiency and expressivity are constrained by rigid query-level batching and structure-exclusive embeddings. We present NGDB-Zoo, a unified framework that resolves these bottlenecks by synergizing operator-level training with semantic augmentation. By decoupling logical operators from query topologies, NGDB-Zoo transforms the training loop into a dynamically scheduled data-flow execution, enabling multi-stream parallelism and achieving a $1.8\times$ - $6.8\times$ throughput compared to baselines. Furthermore, we formalize a decoupled architecture to integrate high-dimensional semantic priors from Pre-trained Text Encoders (PTEs) without triggering I/O stalls or memory overflows. Extensive evaluations on six benchmarks, including massive graphs like ogbl-wikikg2 and ATLAS-Wiki, demonstrate that NGDB-Zoo maintains high GPU utilization across diverse logical patterns and significantly mitigates representation friction in hybrid neuro-symbolic reasoning.
A Unified Neural Codec Language Model for Selective Editable Text to Speech Generation
Jan 18, 2026Neural codec language models achieve impressive zero-shot Text-to-Speech (TTS) by fully imitating the acoustic characteristics of a short speech prompt, including timbre, prosody, and paralinguistic information. However, such holistic imitation limits their ability to isolate and control individual attributes. In this paper, we present a unified codec language model SpeechEdit that extends zero-shot TTS with a selective control mechanism. By default, SpeechEdit reproduces the complete acoustic profile inferred from the speech prompt, but it selectively overrides only the attributes specified by explicit control instructions. To enable controllable modeling, SpeechEdit is trained on our newly constructed LibriEdit dataset, which provides delta (difference-aware) training pairs derived from LibriHeavy. Experimental results show that our approach maintains naturalness and robustness while offering flexible and localized control over desired attributes. Audio samples are available at https://speech-editing.github.io/speech-editing/.
ProImage-Bench: Rubric-Based Evaluation for Professional Image Generation
Dec 13, 2025We study professional image generation, where a model must synthesize information-dense, scientifically precise illustrations from technical descriptions rather than merely produce visually plausible pictures. To quantify the progress, we introduce ProImage-Bench, a rubric-based benchmark that targets biology schematics, engineering/patent drawings, and general scientific diagrams. For 654 figures collected from real textbooks and technical reports, we construct detailed image instructions and a hierarchy of rubrics that decompose correctness into 6,076 criteria and 44,131 binary checks. Rubrics are derived from surrounding text and reference figures using large multimodal models, and are evaluated by an automated LMM-based judge with a principled penalty scheme that aggregates sub-question outcomes into interpretable criterion scores. We benchmark several representative text-to-image models on ProImage-Bench and find that, despite strong open-domain performance, the best base model reaches only 0.791 rubric accuracy and 0.553 criterion score overall, revealing substantial gaps in fine-grained scientific fidelity. Finally, we show that the same rubrics provide actionable supervision: feeding failed checks back into an editing model for iterative refinement boosts a strong generator from 0.653 to 0.865 in rubric accuracy and from 0.388 to 0.697 in criterion score. ProImage-Bench thus offers both a rigorous diagnostic for professional image generation and a scalable signal for improving specification-faithful scientific illustrations.
Towards Responsible Evaluation for Text-to-Speech
Oct 08, 2025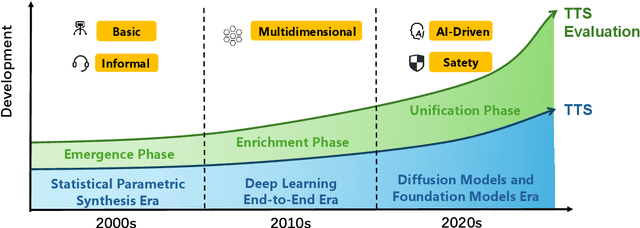


Recent advances in text-to-speech (TTS) technology have enabled systems to produce human-indistinguishable speech, bringing benefits across accessibility, content creation, and human-computer interaction. However, current evaluation practices are increasingly inadequate for capturing the full range of capabilities, limitations, and societal implications. This position paper introduces the concept of Responsible Evaluation and argues that it is essential and urgent for the next phase of TTS development, structured through three progressive levels: (1) ensuring the faithful and accurate reflection of a model's true capabilities, with more robust, discriminative, and comprehensive objective and subjective scoring methodologies; (2) enabling comparability, standardization, and transferability through standardized benchmarks, transparent reporting, and transferable evaluation metrics; and (3) assessing and mitigating ethical risks associated with forgery, misuse, privacy violations, and security vulnerabilities. Through this concept, we critically examine current evaluation practices, identify systemic shortcomings, and propose actionable recommendations. We hope this concept of Responsible Evaluation will foster more trustworthy and reliable TTS technology and guide its development toward ethically sound and societally beneficial applications.