 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRecent Advances in Discrete Speech Tokens: A Review
Paper and Code
Feb 10, 2025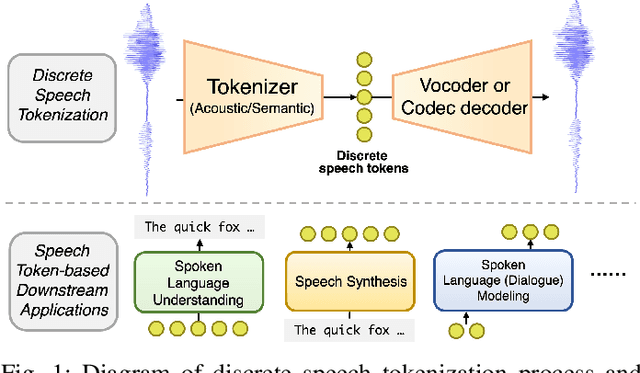
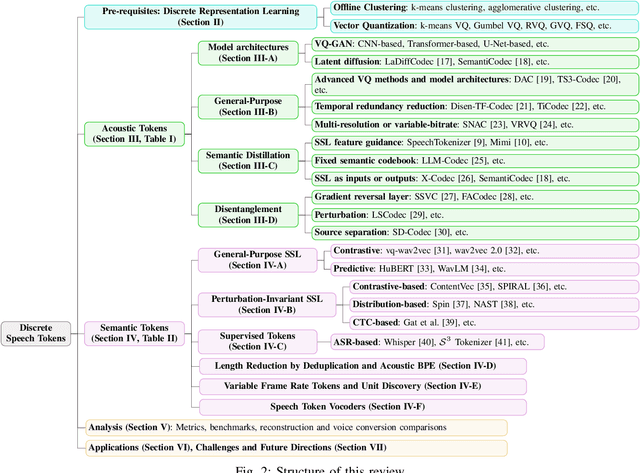
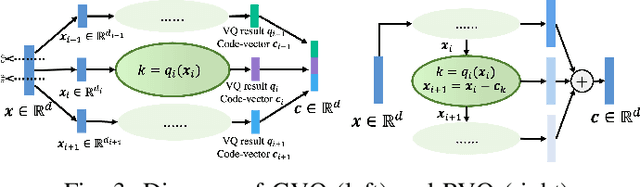
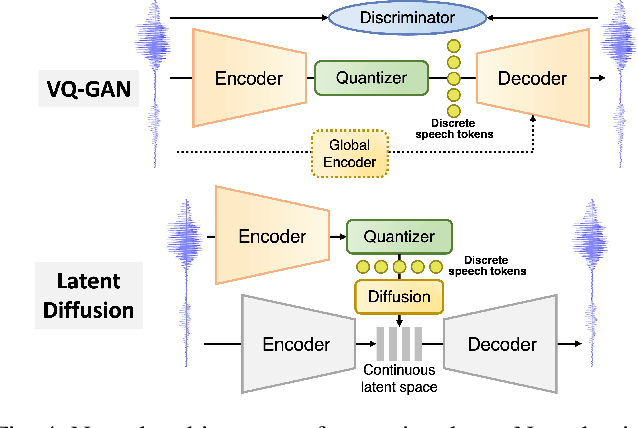
The rapid advancement of speech generation technologies in the era of large language models (LLMs) has established discrete speech tokens as a foundational paradigm for speech representation. These tokens, characterized by their discrete, compact, and concise nature, are not only advantageous for efficient transmission and storage, but also inherently compatible with the language modeling framework, enabling seamless integration of speech into text-dominated LLM architectures. Current research categorizes discrete speech tokens into two principal classes: acoustic tokens and semantic tokens, each of which has evolved into a rich research domain characterized by unique design philosophies and methodological approaches. This survey systematically synthesizes the existing taxonomy and recent innovations in discrete speech tokenization, conducts a critical examination of the strengths and limitations of each paradigm, and presents systematic experimental comparisons across token types. Furthermore, we identify persistent challenges in the field and propose potential research directions, aiming to offer actionable insights to inspire future advancements in the development and application of discrete speech tokens.