 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRAS: a Reliability Oriented Metric for Automatic Speech Recognition
Apr 28, 2026Automatic speech recognition systems often produce confident yet incorrect transcriptions under noisy or ambiguous conditions, which can be misleading for both users and downstream applications. Standard evaluation based on Word Error Rate focuses solely on accuracy and fails to capture transcription reliability. We introduce an abstention-aware transcription framework that enables ASR models to explicitly abstain from uncertain segments. To evaluate reliability under abstention, we propose RAS, a reliability-oriented metric that balances transcription informativeness and error aversion, with its trade-off parameter calibrated by human preference. We then train an abstention-aware ASR model through supervised bootstrapping followed by reinforcement learning. Our experiments demonstrate substantial improvements in transcription reliability while maintaining competitive accuracy.
PACER: Blockwise Pre-verification for Speculative Decoding with Adaptive Length
Feb 01, 2026Speculative decoding (SD) is a powerful technique for accelerating the inference process of large language models (LLMs) without sacrificing accuracy. Typically, SD employs a small draft model to generate a fixed number of draft tokens, which are then verified in parallel by the target model. However, our experiments reveal that the optimal draft length varies significantly across different decoding steps. This variation suggests that using a fixed draft length limits the potential for further improvements in decoding speed. To address this challenge, we propose Pacer, a novel approach that dynamically controls draft length using a lightweight, trainable pre-verification layer. This layer pre-verifies draft tokens blockwise before they are sent to the target model, allowing the draft model to stop token generation if the blockwise pre-verification fails. We implement Pacer on multiple SD model pairs and evaluate its performance across various benchmarks. Our results demonstrate that Pacer achieves up to 2.66x Speedup over autoregressive decoding and consistently outperforms standard speculative decoding. Furthermore, when integrated with Ouroboros, Pacer attains up to 3.09x Speedup.
Time-Layer Adaptive Alignment for Speaker Similarity in Flow-Matching Based Zero-Shot TTS
Nov 13, 2025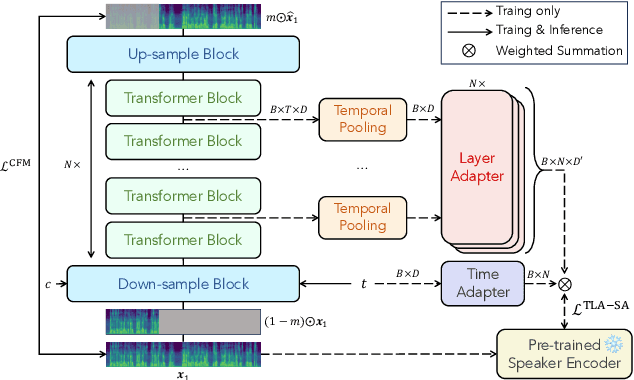

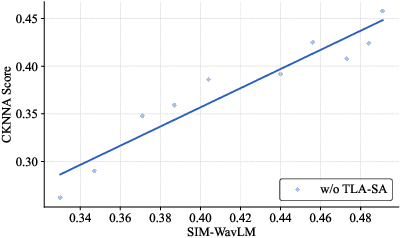

Flow-Matching (FM)-based zero-shot text-to-speech (TTS) systems exhibit high-quality speech synthesis and robust generalization capabilities. However, the speaker representation ability of such systems remains underexplored, primarily due to the lack of explicit speaker-specific supervision in the FM framework. To this end, we conduct an empirical analysis of speaker information distribution and reveal its non-uniform allocation across time steps and network layers, underscoring the need for adaptive speaker alignment. Accordingly, we propose Time-Layer Adaptive Speaker Alignment (TLA-SA), a loss that enhances speaker consistency by jointly leveraging temporal and hierarchical variations in speaker information. Experimental results show that TLA-SA significantly improves speaker similarity compared to baseline systems on both research- and industrial-scale datasets and generalizes effectively across diverse model architectures, including decoder-only language models (LM) and FM-based TTS systems free of LM.
Towards General Discrete Speech Codec for Complex Acoustic Environments: A Study of Reconstruction and Downstream Task Consistency
May 28, 2025Neural speech codecs excel in reconstructing clean speech signals; however, their efficacy in complex acoustic environments and downstream signal processing tasks remains underexplored. In this study, we introduce a novel benchmark named Environment-Resilient Speech Codec Benchmark (ERSB) to systematically evaluate whether neural speech codecs are environment-resilient. Specifically, we assess two key capabilities: (1) robust reconstruction, which measures the preservation of both speech and non-speech acoustic details, and (2) downstream task consistency, which ensures minimal deviation in downstream signal processing tasks when using reconstructed speech instead of the original. Our comprehensive experiments reveal that complex acoustic environments significantly degrade signal reconstruction and downstream task consistency. This work highlights the limitations of current speech codecs and raises a future direction that improves them for greater environmental resilience.
Recent Advances in Discrete Speech Tokens: A Review
Feb 10, 2025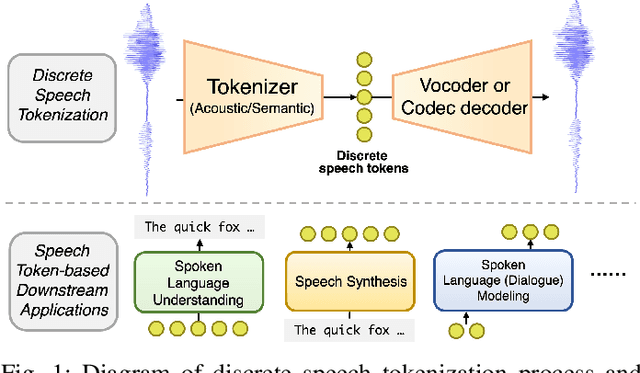
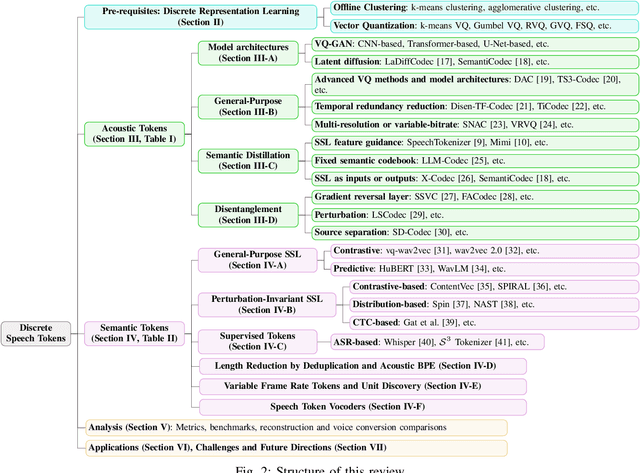
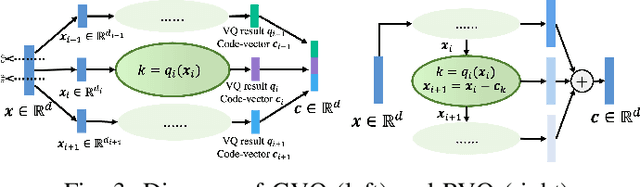
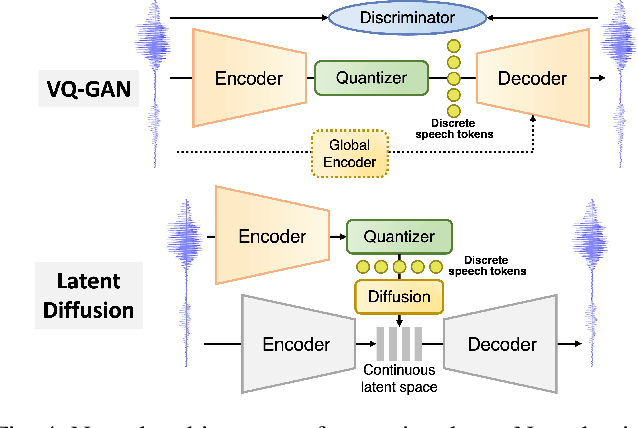
The rapid advancement of speech generation technologies in the era of large language models (LLMs) has established discrete speech tokens as a foundational paradigm for speech representation. These tokens, characterized by their discrete, compact, and concise nature, are not only advantageous for efficient transmission and storage, but also inherently compatible with the language modeling framework, enabling seamless integration of speech into text-dominated LLM architectures. Current research categorizes discrete speech tokens into two principal classes: acoustic tokens and semantic tokens, each of which has evolved into a rich research domain characterized by unique design philosophies and methodological approaches. This survey systematically synthesizes the existing taxonomy and recent innovations in discrete speech tokenization, conducts a critical examination of the strengths and limitations of each paradigm, and presents systematic experimental comparisons across token types. Furthermore, we identify persistent challenges in the field and propose potential research directions, aiming to offer actionable insights to inspire future advancements in the development and application of discrete speech tokens.
AdaEAGLE: Optimizing Speculative Decoding via Explicit Modeling of Adaptive Draft Structures
Dec 25, 2024



Speculative Decoding (SD) is a popular lossless technique for accelerating the inference of Large Language Models (LLMs). We show that the decoding speed of SD frameworks with static draft structures can be significantly improved by incorporating context-aware adaptive draft structures. However, current studies on adaptive draft structures are limited by their performance, modeling approaches, and applicability. In this paper, we introduce AdaEAGLE, the first SD framework that explicitly models adaptive draft structures. AdaEAGLE leverages the Lightweight Draft Length Predictor (LDLP) module to explicitly predict the optimal number of draft tokens during inference to guide the draft model. It achieves comparable speedup results without manual thresholds and allows for deeper, more specialized optimizations. Moreover, together with threshold-based strategies, AdaEAGLE achieves a $1.62\times$ speedup over the vanilla AR decoding and outperforms fixed-length SotA baseline while maintaining output quality.
Why Do Speech Language Models Fail to Generate Semantically Coherent Outputs? A Modality Evolving Perspective
Dec 22, 2024



Although text-based large language models exhibit human-level writing ability and remarkable intelligence, speech language models (SLMs) still struggle to generate semantically coherent outputs. There are several potential reasons for this performance degradation: (A) speech tokens mainly provide phonetic information rather than semantic information, (B) the length of speech sequences is much longer than that of text sequences, and (C) paralinguistic information, such as prosody, introduces additional complexity and variability. In this paper, we explore the influence of three key factors separately by transiting the modality from text to speech in an evolving manner. Our findings reveal that the impact of the three factors varies. Factor A has a relatively minor impact, factor B influences syntactical and semantic modeling more obviously, and factor C exerts the most significant impact, particularly in the basic lexical modeling. Based on these findings, we provide insights into the unique challenges of training SLMs and highlight pathways to develop more effective end-to-end SLMs.
Fast and High-Quality Auto-Regressive Speech Synthesis via Speculative Decoding
Oct 29, 2024



The auto-regressive architecture, like GPTs, is widely used in modern Text-to-Speech (TTS) systems. However, it incurs substantial inference time, particularly due to the challenges in the next-token prediction posed by lengthy sequences of speech tokens. In this work, we introduce VADUSA, one of the first approaches to accelerate auto-regressive TTS through speculative decoding. Our results show that VADUSA not only significantly improves inference speed but also enhances performance by incorporating draft heads to predict future speech content auto-regressively. Furthermore, the inclusion of a tolerance mechanism during sampling accelerates inference without compromising quality. Our approach demonstrates strong generalization across large datasets and various types of speech tokens.
LSCodec: Low-Bitrate and Speaker-Decoupled Discrete Speech Codec
Oct 21, 2024Although discrete speech tokens have exhibited strong potential for language model-based speech generation, their high bitrates and redundant timbre information restrict the development of such models. In this work, we propose LSCodec, a discrete speech codec that has both low bitrate and speaker decoupling ability. LSCodec adopts a three-stage unsupervised training framework with a speaker perturbation technique. A continuous information bottleneck is first established, followed by vector quantization that produces a discrete speaker-decoupled space. A discrete token vocoder finally refines acoustic details from LSCodec. By reconstruction experiments, LSCodec demonstrates superior intelligibility and audio quality with only a single codebook and smaller vocabulary size than baselines. The 25Hz version of LSCodec also achieves the lowest bitrate (0.25kbps) of codecs so far with decent quality. Voice conversion evaluations prove the satisfactory speaker disentanglement of LSCodec, and ablation study further verifies the effectiveness of the proposed training framework.
vec2wav 2.0: Advancing Voice Conversion via Discrete Token Vocoders
Sep 03, 2024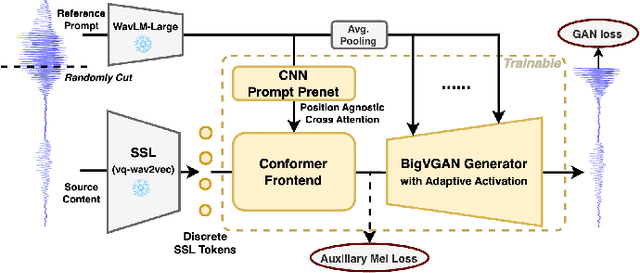
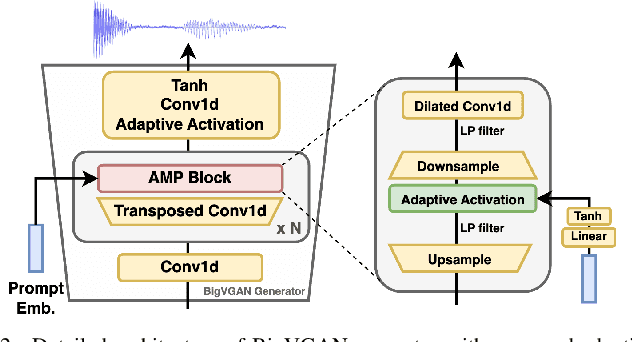
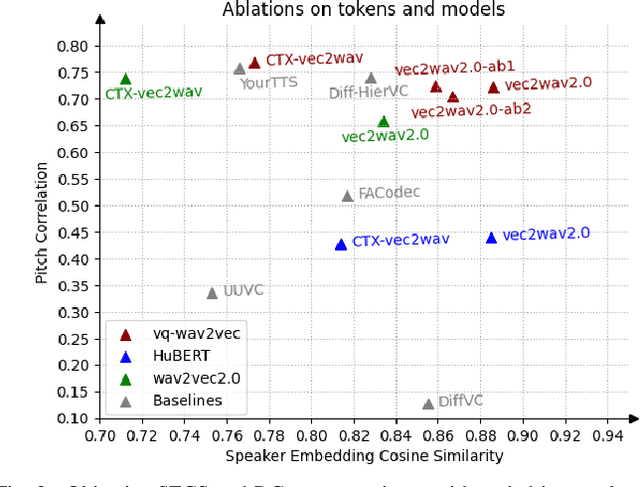
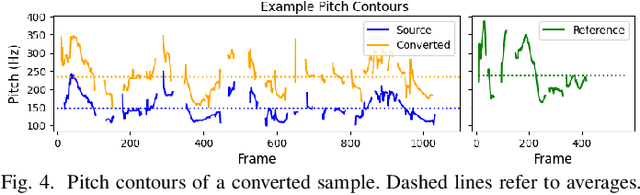
We propose a new speech discrete token vocoder, vec2wav 2.0, which advances voice conversion (VC). We use discrete tokens from speech self-supervised models as the content features of source speech, and treat VC as a prompted vocoding task. To amend the loss of speaker timbre in the content tokens, vec2wav 2.0 utilizes the WavLM features to provide strong timbre-dependent information. A novel adaptive Snake activation function is proposed to better incorporate timbre into the waveform reconstruction process. In this way, vec2wav 2.0 learns to alter the speaker timbre appropriately given different reference prompts. Also, no supervised data is required for vec2wav 2.0 to be effectively trained. Experimental results demonstrate that vec2wav 2.0 outperforms all other baselines to a considerable margin in terms of audio quality and speaker similarity in any-to-any VC. Ablation studies verify the effects made by the proposed techniques. Moreover, vec2wav 2.0 achieves competitive cross-lingual VC even only trained on monolingual corpus. Thus, vec2wav 2.0 shows timbre can potentially be manipulated only by speech token vocoders, pushing the frontiers of VC and speech synthesis.