 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePACER: Blockwise Pre-verification for Speculative Decoding with Adaptive Length
Feb 01, 2026Speculative decoding (SD) is a powerful technique for accelerating the inference process of large language models (LLMs) without sacrificing accuracy. Typically, SD employs a small draft model to generate a fixed number of draft tokens, which are then verified in parallel by the target model. However, our experiments reveal that the optimal draft length varies significantly across different decoding steps. This variation suggests that using a fixed draft length limits the potential for further improvements in decoding speed. To address this challenge, we propose Pacer, a novel approach that dynamically controls draft length using a lightweight, trainable pre-verification layer. This layer pre-verifies draft tokens blockwise before they are sent to the target model, allowing the draft model to stop token generation if the blockwise pre-verification fails. We implement Pacer on multiple SD model pairs and evaluate its performance across various benchmarks. Our results demonstrate that Pacer achieves up to 2.66x Speedup over autoregressive decoding and consistently outperforms standard speculative decoding. Furthermore, when integrated with Ouroboros, Pacer attains up to 3.09x Speedup.
ChemDFM-R: An Chemical Reasoner LLM Enhanced with Atomized Chemical Knowledge
Jul 30, 2025While large language models (LLMs) have achieved impressive progress, their application in scientific domains such as chemistry remains hindered by shallow domain understanding and limited reasoning capabilities. In this work, we focus on the specific field of chemistry and develop a Chemical Reasoner LLM, ChemDFM-R. We first construct a comprehensive dataset of atomized knowledge points to enhance the model's understanding of the fundamental principles and logical structure of chemistry. Then, we propose a mix-sourced distillation strategy that integrates expert-curated knowledge with general-domain reasoning skills, followed by domain-specific reinforcement learning to enhance chemical reasoning. Experiments on diverse chemical benchmarks demonstrate that ChemDFM-R achieves cutting-edge performance while providing interpretable, rationale-driven outputs. Further case studies illustrate how explicit reasoning chains significantly improve the reliability, transparency, and practical utility of the model in real-world human-AI collaboration scenarios.
Reasoning-Driven Retrosynthesis Prediction with Large Language Models via Reinforcement Learning
Jul 23, 2025Retrosynthesis planning, essential in organic synthesis and drug discovery, has greatly benefited from recent AI-driven advancements. Nevertheless, existing methods frequently face limitations in both applicability and explainability. Traditional graph-based and sequence-to-sequence models often lack generalized chemical knowledge, leading to predictions that are neither consistently accurate nor easily explainable. To address these challenges, we introduce RetroDFM-R, a reasoning-based large language model (LLM) designed specifically for chemical retrosynthesis. Leveraging large-scale reinforcement learning guided by chemically verifiable rewards, RetroDFM-R significantly enhances prediction accuracy and explainability. Comprehensive evaluations demonstrate that RetroDFM-R significantly outperforms state-of-the-art methods, achieving a top-1 accuracy of 65.0% on the USPTO-50K benchmark. Double-blind human assessments further validate the chemical plausibility and practical utility of RetroDFM-R's predictions. RetroDFM-R also accurately predicts multistep retrosynthetic routes reported in the literature for both real-world drug molecules and perovskite materials. Crucially, the model's explicit reasoning process provides human-interpretable insights, thereby enhancing trust and practical value in real-world retrosynthesis applications.
ProgRM: Build Better GUI Agents with Progress Rewards
May 23, 2025LLM-based (Large Language Model) GUI (Graphical User Interface) agents can potentially reshape our daily lives significantly. However, current LLM-based GUI agents suffer from the scarcity of high-quality training data owing to the difficulties of trajectory collection and reward annotation. Existing works have been exploring LLMs to collect trajectories for imitation learning or to offer reward signals for online RL training. However, the Outcome Reward Model (ORM) used in existing works cannot provide finegrained feedback and can over-penalize the valuable steps in finally failed trajectories. To this end, we propose Progress Reward Model (ProgRM) to provide dense informative intermediate rewards by predicting a task completion progress for each step in online training. To handle the challenge of progress reward label annotation, we further design an efficient LCS-based (Longest Common Subsequence) self-annotation algorithm to discover the key steps in trajectories and assign progress labels accordingly. ProgRM is evaluated with extensive experiments and analyses. Actors trained with ProgRM outperform leading proprietary LLMs and ORM-trained actors, illustrating the effectiveness of ProgRM. The codes for experiments will be made publicly available upon acceptance.
AdaEAGLE: Optimizing Speculative Decoding via Explicit Modeling of Adaptive Draft Structures
Dec 25, 2024



Speculative Decoding (SD) is a popular lossless technique for accelerating the inference of Large Language Models (LLMs). We show that the decoding speed of SD frameworks with static draft structures can be significantly improved by incorporating context-aware adaptive draft structures. However, current studies on adaptive draft structures are limited by their performance, modeling approaches, and applicability. In this paper, we introduce AdaEAGLE, the first SD framework that explicitly models adaptive draft structures. AdaEAGLE leverages the Lightweight Draft Length Predictor (LDLP) module to explicitly predict the optimal number of draft tokens during inference to guide the draft model. It achieves comparable speedup results without manual thresholds and allows for deeper, more specialized optimizations. Moreover, together with threshold-based strategies, AdaEAGLE achieves a $1.62\times$ speedup over the vanilla AR decoding and outperforms fixed-length SotA baseline while maintaining output quality.
Compressing KV Cache for Long-Context LLM Inference with Inter-Layer Attention Similarity
Dec 03, 2024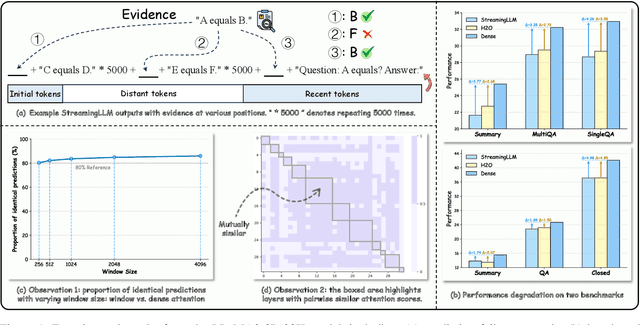



The increasing context window size in Large Language Models (LLMs), such as the GPT and LLaMA series, has improved their ability to tackle complex, long-text tasks, but at the cost of inference efficiency, particularly regarding memory and computational complexity. Existing methods, including selective token retention and window-based attention, improve efficiency but risk discarding important tokens needed for future text generation. In this paper, we propose an approach that enhances LLM efficiency without token loss by reducing the memory and computational load of less important tokens, rather than discarding them.We address two challenges: 1) investigating the distribution of important tokens in the context, discovering recent tokens are more important than distant tokens in context, and 2) optimizing resources for distant tokens by sharing attention scores across layers. The experiments show that our method saves $35\%$ KV cache without compromising the performance.
Fast and High-Quality Auto-Regressive Speech Synthesis via Speculative Decoding
Oct 29, 2024



The auto-regressive architecture, like GPTs, is widely used in modern Text-to-Speech (TTS) systems. However, it incurs substantial inference time, particularly due to the challenges in the next-token prediction posed by lengthy sequences of speech tokens. In this work, we introduce VADUSA, one of the first approaches to accelerate auto-regressive TTS through speculative decoding. Our results show that VADUSA not only significantly improves inference speed but also enhances performance by incorporating draft heads to predict future speech content auto-regressively. Furthermore, the inclusion of a tolerance mechanism during sampling accelerates inference without compromising quality. Our approach demonstrates strong generalization across large datasets and various types of speech tokens.
MobA: A Two-Level Agent System for Efficient Mobile Task Automation
Oct 17, 2024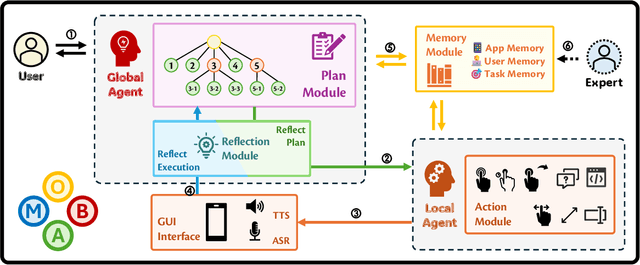
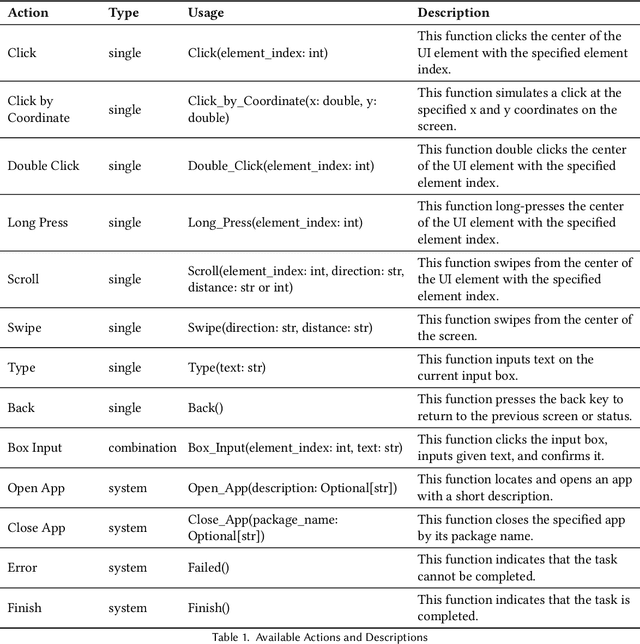
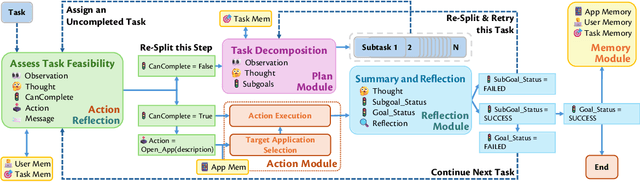
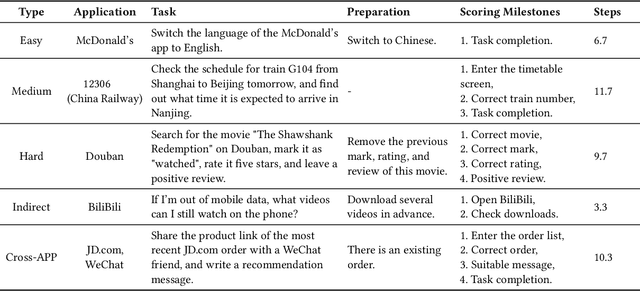
Current mobile assistants are limited by dependence on system APIs or struggle with complex user instructions and diverse interfaces due to restricted comprehension and decision-making abilities. To address these challenges, we propose MobA, a novel Mobile phone Agent powered by multimodal large language models that enhances comprehension and planning capabilities through a sophisticated two-level agent architecture. The high-level Global Agent (GA) is responsible for understanding user commands, tracking history memories, and planning tasks. The low-level Local Agent (LA) predicts detailed actions in the form of function calls, guided by sub-tasks and memory from the GA. Integrating a Reflection Module allows for efficient task completion and enables the system to handle previously unseen complex tasks. MobA demonstrates significant improvements in task execution efficiency and completion rate in real-life evaluations, underscoring the potential of MLLM-empowered mobile assistants.
Rejection Improves Reliability: Training LLMs to Refuse Unknown Questions Using RL from Knowledge Feedback
Apr 07, 2024
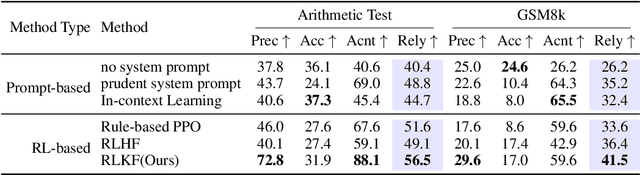
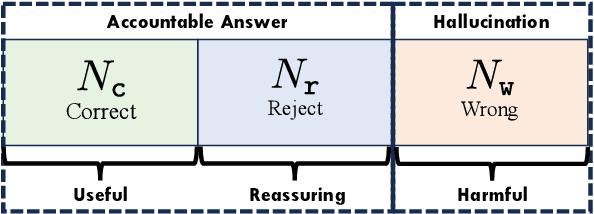
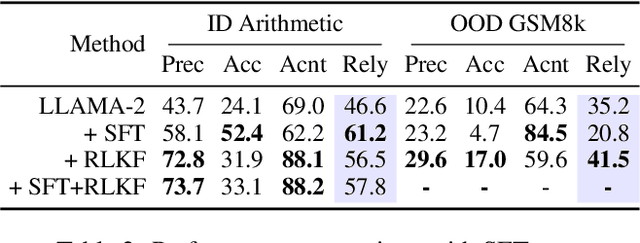
Large Language Models (LLMs) often generate erroneous outputs, known as hallucinations, due to their limitations in discerning questions beyond their knowledge scope. While addressing hallucination has been a focal point in research, previous efforts primarily concentrate on enhancing correctness without giving due consideration to the significance of rejection mechanisms. In this paper, we conduct a comprehensive examination of the role of rejection, introducing the notion of model reliability along with corresponding metrics. These metrics measure the model's ability to provide accurate responses while adeptly rejecting questions exceeding its knowledge boundaries, thereby minimizing hallucinations. To improve the inherent reliability of LLMs, we present a novel alignment framework called Reinforcement Learning from Knowledge Feedback (RLKF). RLKF leverages knowledge feedback to dynamically determine the model's knowledge boundary and trains a reliable reward model to encourage the refusal of out-of-knowledge questions. Experimental results on mathematical questions affirm the substantial efficacy of RLKF in significantly enhancing LLM reliability.
Multi: Multimodal Understanding Leaderboard with Text and Images
Feb 05, 2024
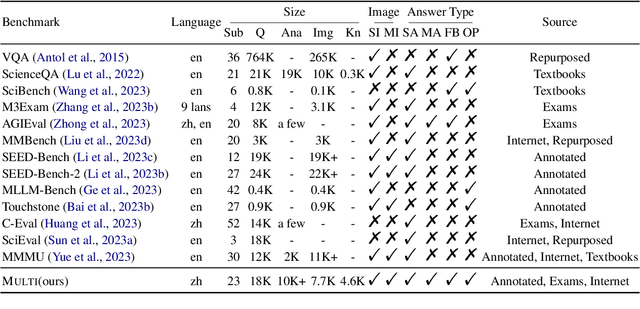
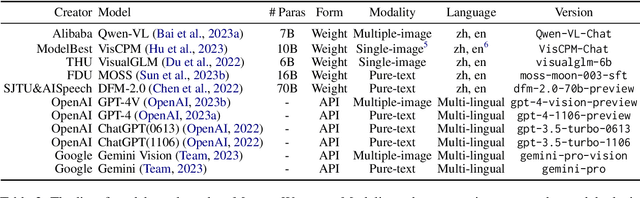

Rapid progress in multimodal large language models (MLLMs) highlights the need to introduce challenging yet realistic benchmarks to the academic community. Existing benchmarks primarily focus on simple natural image understanding, but Multi emerges as a cutting-edge benchmark for MLLMs, offering a comprehensive dataset for evaluating MLLMs against understanding complex figures and tables, and scientific questions. This benchmark, reflecting current realistic examination styles, provides multimodal inputs and requires responses that are either precise or open-ended, similar to real-life school tests. It challenges MLLMs with a variety of tasks, ranging from formula derivation to image detail analysis, and cross-modality reasoning. Multi includes over 18,000 questions, with a focus on science-based QA in diverse formats. We also introduce Multi-Elite, a 500-question subset for testing the extremities of MLLMs, and Multi-Extend, which enhances In-Context Learning research with more than 4,500 knowledge pieces. Our evaluation indicates significant potential for MLLM advancement, with GPT-4V achieving a 63.7% accuracy rate on Multi, in contrast to other MLLMs scoring between 31.3% and 53.7%. Multi serves not only as a robust evaluation platform but also paves the way for the development of expert-level AI.