 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Unified and Reproducible Experimentation Framework for Speech Understanding
May 29, 2026Speech foundation models and Speech LLMs have advanced speech understanding, yet deployment-oriented model selection is hindered by non-comparable evaluations caused by mismatched post-processing, and by training results that are hard to reproduce across data scales and pipelines. We present SURE, a unified experimentation framework that standardizes prediction formats, normalization, and scoring. SURE evaluates strong systems across paradigms, from conventional pipelines to Speech LLMs, on representative tasks under realistic acoustic and linguistic stressors. Beyond evaluation, SURE introduces an agent-assisted training conversion flow that maps paper and code into versioned, runnable training pipelines under a unified protocol on matched open-data subsets. Overall, SURE improves comparability and reproducibility for deployment-oriented evaluation.
DeepSurvey: Enhancing Analytical Depth and Citation Reliability in Automated Survey Generation
May 28, 2026As scientific literature grows rapidly, automated survey generation has become a key capability for AI scientists and human researchers. However, existing systems suffer from limited analytical depth due to reliance on abstracts and isolated paper processing, and unreliable citations from imprecise retrieval and post-hoc grounding, producing superficial surveys and may mislead researchers. We present DeepSurvey, an agentic system that addresses both. To enhance depth, DeepSurvey extracts structured keynotes from full-text papers, models cross-paper relationships through clustering and comparative analysis, and integrates code-repository analysis to recover implementation-level details. To fortify reliability, it combines citation-graph expansion with hybrid filtering for topic-focussed retrieval, enforces evidence-constrained citation assignment, and deploys multi-granularity agentic refinement to validate citation-claim alignment. Experiments show that DeepSurvey achieves the highest content score (8.644/10) and citation quality (12.3% and 9.3% recall and precision gains over the strongest baseline), generalizes more robustly across domains (0.14 vs 0.22 to 0.69 CS-to-non-CS drop), and is preferred over human-written surveys by domain experts (83.3% overall quality, 100% content depth).
Audio-Mind: An Auditable Agentic Framework for Audio Understanding
May 27, 2026Audio agents extend large audio-language models (LALMs) by decomposing audio questions into tool calls, intermediate evidence, and iterative reasoning steps. However, as LALMs become stronger, the key challenge shifts from enabling tool use to determining when agentic evidence acquisition genuinely benefits audio understanding. We propose Audio-Mind, an auditable and pluggable framework for conditional evidence acquisition in audio understanding. Audio-Mind dynamically combines a strong frontend with planner-guided tool use, preserving frontend judgment when initial evidence is sufficient while acquiring bounded external evidence for questions with unresolved evidence gaps. Experiments on MMAR and MSU-Bench show that Audio-Mind outperforms prior audio-agent baselines, reaching 80.4% accuracy on MMAR and 82.8% accuracy on MSU-Bench. A matched-backbone comparison highlights why this design matters: under strong audio frontends, agentic decomposition can become an orchestration bottleneck when the workflow does not preserve the frontend's holistic audio-grounded judgment. Beyond accuracy, Audio-Mind produces higher-quality, auditable reasoning traces that expose uncertainty, tool evidence, and answer rationales, offering a potential basis for more reliable audio-QA annotation and error analysis.
Diagnosing CFG Interpretation in LLMs
Apr 22, 2026As LLMs are increasingly integrated into agentic systems, they must adhere to dynamically defined, machine-interpretable interfaces. We evaluate LLMs as in-context interpreters: given a novel context-free grammar, can LLMs generate syntactically valid, behaviorally functional, and semantically faithful outputs? We introduce RoboGrid, a framework that disentangles syntax, behavior, and semantics through controlled stress-tests of recursion depth, expression complexity, and surface styles. Our experiments reveal a consistent hierarchical degradation: LLMs often maintain surface syntax but fail to preserve structural semantics. Despite the partial mitigation provided by CoT reasoning, performance collapses under structural density, specifically deep recursion and high branching, with semantic alignment vanishing at extreme depths. Furthermore, "Alien" lexicons reveal that LLMs rely on semantic bootstrapping from keywords rather than pure symbolic induction. These findings pinpoint critical gaps in hierarchical state-tracking required for reliable, grammar-agnostic agents.
PaperGuide: Making Small Language-Model Paper-Reading Agents More Efficient
Jan 19, 2026The accelerating growth of the scientific literature makes it increasingly difficult for researchers to track new advances through manual reading alone. Recent progress in large language models (LLMs) has therefore spurred interest in autonomous agents that can read scientific papers and extract task-relevant information. However, most existing approaches rely either on heavily engineered prompting or on a conventional SFT-RL training pipeline, both of which often lead to excessive and low-yield exploration. Drawing inspiration from cognitive science, we propose PaperCompass, a framework that mitigates these issues by separating high-level planning from fine-grained execution. PaperCompass first drafts an explicit plan that outlines the intended sequence of actions, and then performs detailed reasoning to instantiate each step by selecting the parameters for the corresponding function calls. To train such behavior, we introduce Draft-and-Follow Policy Optimization (DFPO), a tailored RL method that jointly optimizes both the draft plan and the final solution. DFPO can be viewed as a lightweight form of hierarchical reinforcement learning, aimed at narrowing the `knowing-doing' gap in LLMs. We provide a theoretical analysis that establishes DFPO's favorable optimization properties, supporting a stable and reliable training process. Experiments on paper-based question answering (Paper-QA) benchmarks show that PaperCompass improves efficiency over strong baselines without sacrificing performance, achieving results comparable to much larger models.
Reasoning-Driven Retrosynthesis Prediction with Large Language Models via Reinforcement Learning
Jul 23, 2025Retrosynthesis planning, essential in organic synthesis and drug discovery, has greatly benefited from recent AI-driven advancements. Nevertheless, existing methods frequently face limitations in both applicability and explainability. Traditional graph-based and sequence-to-sequence models often lack generalized chemical knowledge, leading to predictions that are neither consistently accurate nor easily explainable. To address these challenges, we introduce RetroDFM-R, a reasoning-based large language model (LLM) designed specifically for chemical retrosynthesis. Leveraging large-scale reinforcement learning guided by chemically verifiable rewards, RetroDFM-R significantly enhances prediction accuracy and explainability. Comprehensive evaluations demonstrate that RetroDFM-R significantly outperforms state-of-the-art methods, achieving a top-1 accuracy of 65.0% on the USPTO-50K benchmark. Double-blind human assessments further validate the chemical plausibility and practical utility of RetroDFM-R's predictions. RetroDFM-R also accurately predicts multistep retrosynthetic routes reported in the literature for both real-world drug molecules and perovskite materials. Crucially, the model's explicit reasoning process provides human-interpretable insights, thereby enhancing trust and practical value in real-world retrosynthesis applications.
NeuSym-RAG: Hybrid Neural Symbolic Retrieval with Multiview Structuring for PDF Question Answering
May 26, 2025The increasing number of academic papers poses significant challenges for researchers to efficiently acquire key details. While retrieval augmented generation (RAG) shows great promise in large language model (LLM) based automated question answering, previous works often isolate neural and symbolic retrieval despite their complementary strengths. Moreover, conventional single-view chunking neglects the rich structure and layout of PDFs, e.g., sections and tables. In this work, we propose NeuSym-RAG, a hybrid neural symbolic retrieval framework which combines both paradigms in an interactive process. By leveraging multi-view chunking and schema-based parsing, NeuSym-RAG organizes semi-structured PDF content into both the relational database and vectorstore, enabling LLM agents to iteratively gather context until sufficient to generate answers. Experiments on three full PDF-based QA datasets, including a self-annotated one AIRQA-REAL, show that NeuSym-RAG stably defeats both the vector-based RAG and various structured baselines, highlighting its capacity to unify both retrieval schemes and utilize multiple views. Code and data are publicly available at https://github.com/X-LANCE/NeuSym-RAG.
"From Unseen Needs to Classroom Solutions": Exploring AI Literacy Challenges & Opportunities with Project-based Learning Toolkit in K-12 Education
Dec 23, 2024As artificial intelligence (AI) becomes increasingly central to various fields, there is a growing need to equip K-12 students with AI literacy skills that extend beyond computer science. This paper explores the integration of a Project-Based Learning (PBL) AI toolkit into diverse subject areas, aimed at helping educators teach AI concepts more effectively. Through interviews and co-design sessions with K-12 teachers, we examined current AI literacy levels and how teachers adapt AI tools like the AI Art Lab, AI Music Studio, and AI Chatbot into their course designs. While teachers appreciated the potential of AI tools to foster creativity and critical thinking, they also expressed concerns about the accuracy, trustworthiness, and ethical implications of AI-generated content. Our findings reveal the challenges teachers face, including limited resources, varying student and instructor skill levels, and the need for scalable, adaptable AI tools. This research contributes insights that can inform the development of AI curricula tailored to diverse educational contexts.
Compressing KV Cache for Long-Context LLM Inference with Inter-Layer Attention Similarity
Dec 03, 2024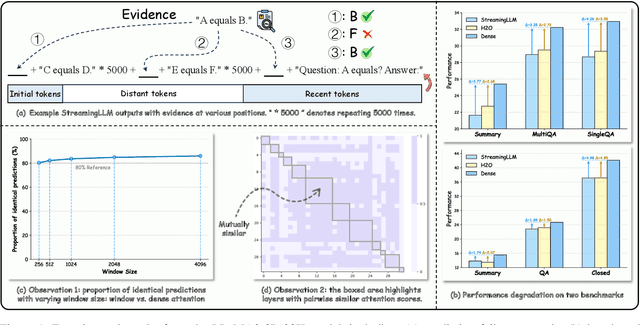



The increasing context window size in Large Language Models (LLMs), such as the GPT and LLaMA series, has improved their ability to tackle complex, long-text tasks, but at the cost of inference efficiency, particularly regarding memory and computational complexity. Existing methods, including selective token retention and window-based attention, improve efficiency but risk discarding important tokens needed for future text generation. In this paper, we propose an approach that enhances LLM efficiency without token loss by reducing the memory and computational load of less important tokens, rather than discarding them.We address two challenges: 1) investigating the distribution of important tokens in the context, discovering recent tokens are more important than distant tokens in context, and 2) optimizing resources for distant tokens by sharing attention scores across layers. The experiments show that our method saves $35\%$ KV cache without compromising the performance.
Evolving Subnetwork Training for Large Language Models
Jun 11, 2024



Large language models have ushered in a new era of artificial intelligence research. However, their substantial training costs hinder further development and widespread adoption. In this paper, inspired by the redundancy in the parameters of large language models, we propose a novel training paradigm: Evolving Subnetwork Training (EST). EST samples subnetworks from the layers of the large language model and from commonly used modules within each layer, Multi-Head Attention (MHA) and Multi-Layer Perceptron (MLP). By gradually increasing the size of the subnetworks during the training process, EST can save the cost of training. We apply EST to train GPT2 model and TinyLlama model, resulting in 26.7\% FLOPs saving for GPT2 and 25.0\% for TinyLlama without an increase in loss on the pre-training dataset. Moreover, EST leads to performance improvements in downstream tasks, indicating that it benefits generalization. Additionally, we provide intuitive theoretical studies based on training dynamics and Dropout theory to ensure the feasibility of EST. Our code is available at https://github.com/OpenDFM/EST.