 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMiMo-V2-Flash Technical Report
Jan 08, 2026We present MiMo-V2-Flash, a Mixture-of-Experts (MoE) model with 309B total parameters and 15B active parameters, designed for fast, strong reasoning and agentic capabilities. MiMo-V2-Flash adopts a hybrid attention architecture that interleaves Sliding Window Attention (SWA) with global attention, with a 128-token sliding window under a 5:1 hybrid ratio. The model is pre-trained on 27 trillion tokens with Multi-Token Prediction (MTP), employing a native 32k context length and subsequently extended to 256k. To efficiently scale post-training compute, MiMo-V2-Flash introduces a novel Multi-Teacher On-Policy Distillation (MOPD) paradigm. In this framework, domain-specialized teachers (e.g., trained via large-scale reinforcement learning) provide dense and token-level reward, enabling the student model to perfectly master teacher expertise. MiMo-V2-Flash rivals top-tier open-weight models such as DeepSeek-V3.2 and Kimi-K2, despite using only 1/2 and 1/3 of their total parameters, respectively. During inference, by repurposing MTP as a draft model for speculative decoding, MiMo-V2-Flash achieves up to 3.6 acceptance length and 2.6x decoding speedup with three MTP layers. We open-source both the model weights and the three-layer MTP weights to foster open research and community collaboration.
MiMo-Audio: Audio Language Models are Few-Shot Learners
Dec 29, 2025Existing audio language models typically rely on task-specific fine-tuning to accomplish particular audio tasks. In contrast, humans are able to generalize to new audio tasks with only a few examples or simple instructions. GPT-3 has shown that scaling next-token prediction pretraining enables strong generalization capabilities in text, and we believe this paradigm is equally applicable to the audio domain. By scaling MiMo-Audio's pretraining data to over one hundred million of hours, we observe the emergence of few-shot learning capabilities across a diverse set of audio tasks. We develop a systematic evaluation of these capabilities and find that MiMo-Audio-7B-Base achieves SOTA performance on both speech intelligence and audio understanding benchmarks among open-source models. Beyond standard metrics, MiMo-Audio-7B-Base generalizes to tasks absent from its training data, such as voice conversion, style transfer, and speech editing. MiMo-Audio-7B-Base also demonstrates powerful speech continuation capabilities, capable of generating highly realistic talk shows, recitations, livestreaming and debates. At the post-training stage, we curate a diverse instruction-tuning corpus and introduce thinking mechanisms into both audio understanding and generation. MiMo-Audio-7B-Instruct achieves open-source SOTA on audio understanding benchmarks (MMSU, MMAU, MMAR, MMAU-Pro), spoken dialogue benchmarks (Big Bench Audio, MultiChallenge Audio) and instruct-TTS evaluations, approaching or surpassing closed-source models. Model checkpoints and full evaluation suite are available at https://github.com/XiaomiMiMo/MiMo-Audio.
DiSRouter: Distributed Self-Routing for LLM Selections
Oct 22, 2025The proliferation of Large Language Models (LLMs) has created a diverse ecosystem of models with highly varying performance and costs, necessitating effective query routing to balance performance and expense. Current routing systems often rely on a centralized external router trained on a fixed set of LLMs, making them inflexible and prone to poor performance since the small router can not fully understand the knowledge boundaries of different LLMs. We introduce DiSRouter (Distributed Self-Router), a novel paradigm that shifts from centralized control to distributed routing. In DiSRouter, a query traverses a network of LLM agents, each independently deciding whether to answer or route to other agents based on its own self-awareness, its ability to judge its competence. This distributed design offers superior flexibility, scalability, and generalizability. To enable this, we propose a two-stage Self-Awareness Training pipeline that enhances each LLM's self-awareness. Extensive experiments demonstrate that DiSRouter significantly outperforms existing routing methods in utility across various scenarios, effectively distinguishes between easy and hard queries, and shows strong generalization to out-of-domain tasks. Our work validates that leveraging an LLM's intrinsic self-awareness is more effective than external assessment, paving the way for more modular and efficient multi-agent systems.
MiMo: Unlocking the Reasoning Potential of Language Model -- From Pretraining to Posttraining
May 12, 2025We present MiMo-7B, a large language model born for reasoning tasks, with optimization across both pre-training and post-training stages. During pre-training, we enhance the data preprocessing pipeline and employ a three-stage data mixing strategy to strengthen the base model's reasoning potential. MiMo-7B-Base is pre-trained on 25 trillion tokens, with additional Multi-Token Prediction objective for enhanced performance and accelerated inference speed. During post-training, we curate a dataset of 130K verifiable mathematics and programming problems for reinforcement learning, integrating a test-difficulty-driven code-reward scheme to alleviate sparse-reward issues and employing strategic data resampling to stabilize training. Extensive evaluations show that MiMo-7B-Base possesses exceptional reasoning potential, outperforming even much larger 32B models. The final RL-tuned model, MiMo-7B-RL, achieves superior performance on mathematics, code and general reasoning tasks, surpassing the performance of OpenAI o1-mini. The model checkpoints are available at https://github.com/xiaomimimo/MiMo.
Alignment for Efficient Tool Calling of Large Language Models
Mar 09, 2025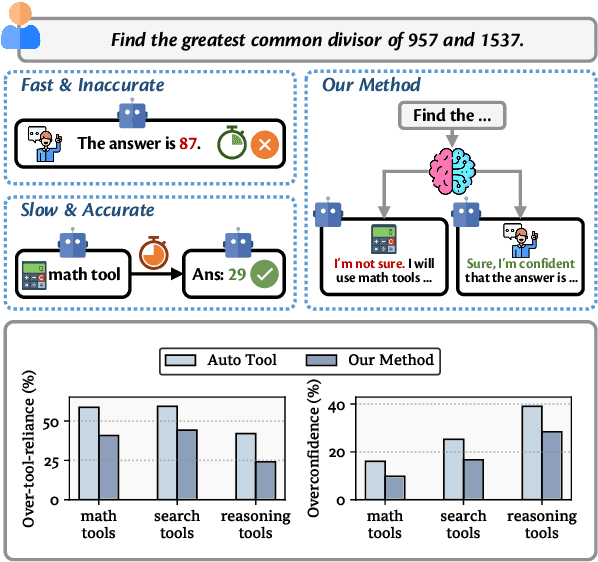
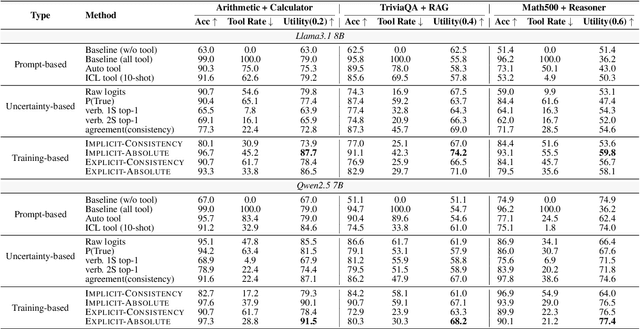
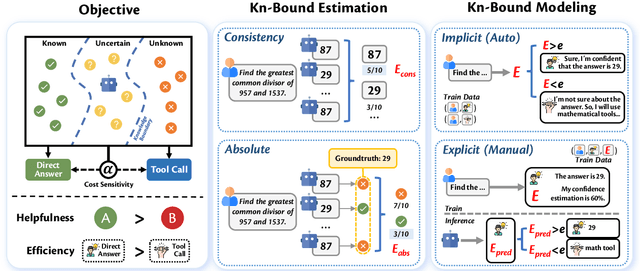

Recent advancements in tool learning have enabled large language models (LLMs) to integrate external tools, enhancing their task performance by expanding their knowledge boundaries. However, relying on tools often introduces tradeoffs between performance, speed, and cost, with LLMs sometimes exhibiting overreliance and overconfidence in tool usage. This paper addresses the challenge of aligning LLMs with their knowledge boundaries to make more intelligent decisions about tool invocation. We propose a multi objective alignment framework that combines probabilistic knowledge boundary estimation with dynamic decision making, allowing LLMs to better assess when to invoke tools based on their confidence. Our framework includes two methods for knowledge boundary estimation, consistency based and absolute estimation, and two training strategies for integrating these estimates into the model decision making process. Experimental results on various tool invocation scenarios demonstrate the effectiveness of our framework, showing significant improvements in tool efficiency by reducing unnecessary tool usage.
Delusions of Large Language Models
Mar 09, 2025Large Language Models often generate factually incorrect but plausible outputs, known as hallucinations. We identify a more insidious phenomenon, LLM delusion, defined as high belief hallucinations, incorrect outputs with abnormally high confidence, making them harder to detect and mitigate. Unlike ordinary hallucinations, delusions persist with low uncertainty, posing significant challenges to model reliability. Through empirical analysis across different model families and sizes on several Question Answering tasks, we show that delusions are prevalent and distinct from hallucinations. LLMs exhibit lower honesty with delusions, which are harder to override via finetuning or self reflection. We link delusion formation with training dynamics and dataset noise and explore mitigation strategies such as retrieval augmented generation and multi agent debating to mitigate delusions. By systematically investigating the nature, prevalence, and mitigation of LLM delusions, our study provides insights into the underlying causes of this phenomenon and outlines future directions for improving model reliability.
Enhancing LLM Reliability via Explicit Knowledge Boundary Modeling
Mar 04, 2025Large language models (LLMs) frequently hallucinate due to misaligned self-awareness, generating erroneous outputs when addressing queries beyond their knowledge boundaries. While existing approaches mitigate hallucinations via uncertainty estimation or query rejection, they suffer from computational inefficiency or sacrificed helpfulness. To address these issues, we propose the Explicit Knowledge Boundary Modeling (EKBM) framework, integrating fast and slow reasoning systems to harmonize reliability and usability. The framework first employs a fast-thinking model to generate confidence-labeled responses, enabling immediate use of high-confidence outputs. For uncertain predictions, a slow refinement model conducts targeted reasoning to improve accuracy. To align model behavior with our proposed object, we propose a hybrid training pipeline, enhancing self-awareness without degrading task performance. Evaluations on dialogue state tracking tasks demonstrate that EKBM achieves superior model reliability over uncertainty-based baselines. Further analysis reveals that refinement substantially boosts accuracy while maintaining low computational overhead. Our work establishes a scalable paradigm for advancing LLM reliability and balancing accuracy and practical utility in error-sensitive applications.
Reducing Tool Hallucination via Reliability Alignment
Dec 05, 2024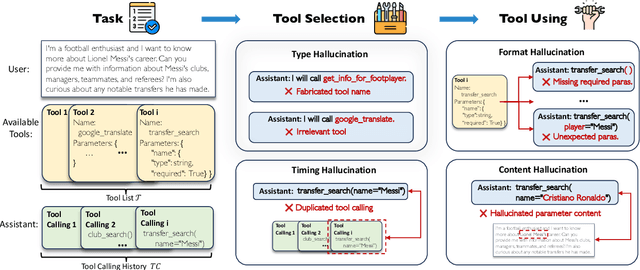
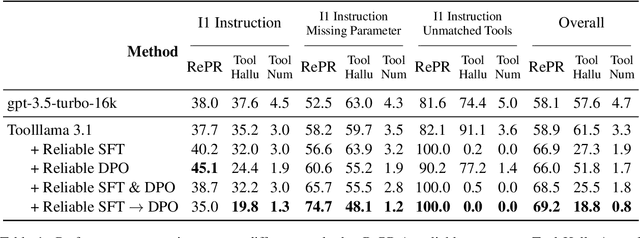
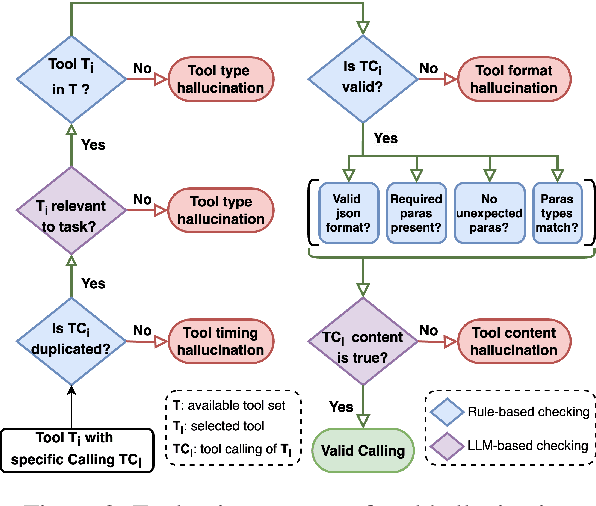
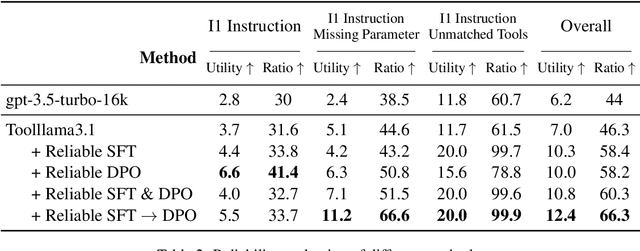
Large Language Models (LLMs) have extended their capabilities beyond language generation to interact with external systems through tool calling, offering powerful potential for real-world applications. However, the phenomenon of tool hallucinations, which occur when models improperly select or misuse tools, presents critical challenges that can lead to flawed task execution and increased operational costs. This paper investigates the concept of reliable tool calling and highlights the necessity of addressing tool hallucinations. We systematically categorize tool hallucinations into two main types: tool selection hallucination and tool usage hallucination. To mitigate these issues, we propose a reliability-focused alignment framework that enhances the model's ability to accurately assess tool relevance and usage. By proposing a suite of evaluation metrics and evaluating on StableToolBench, we further demonstrate the effectiveness of our framework in mitigating tool hallucination and improving the overall system reliability of LLM tool calling.
Compressing KV Cache for Long-Context LLM Inference with Inter-Layer Attention Similarity
Dec 03, 2024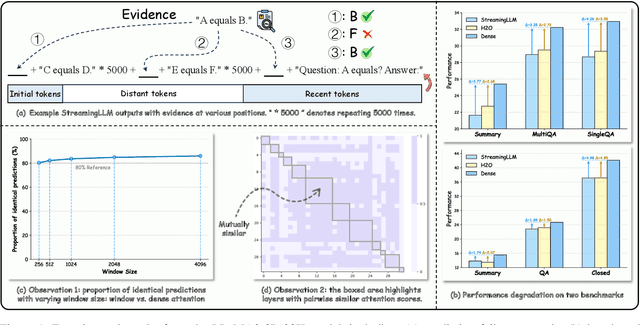



The increasing context window size in Large Language Models (LLMs), such as the GPT and LLaMA series, has improved their ability to tackle complex, long-text tasks, but at the cost of inference efficiency, particularly regarding memory and computational complexity. Existing methods, including selective token retention and window-based attention, improve efficiency but risk discarding important tokens needed for future text generation. In this paper, we propose an approach that enhances LLM efficiency without token loss by reducing the memory and computational load of less important tokens, rather than discarding them.We address two challenges: 1) investigating the distribution of important tokens in the context, discovering recent tokens are more important than distant tokens in context, and 2) optimizing resources for distant tokens by sharing attention scores across layers. The experiments show that our method saves $35\%$ KV cache without compromising the performance.
Spider2-V: How Far Are Multimodal Agents From Automating Data Science and Engineering Workflows?
Jul 15, 2024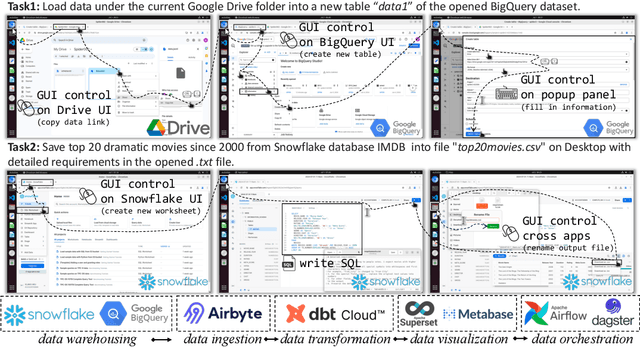
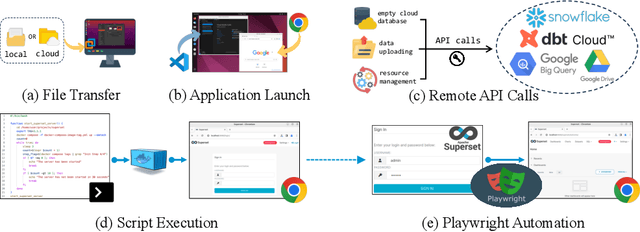
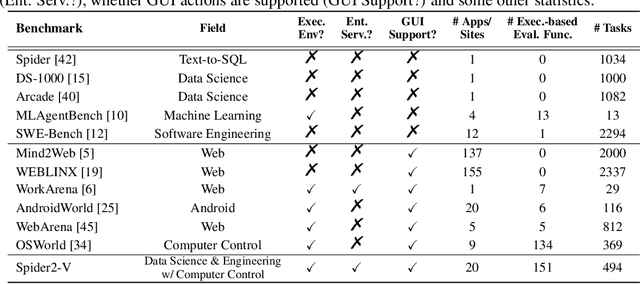
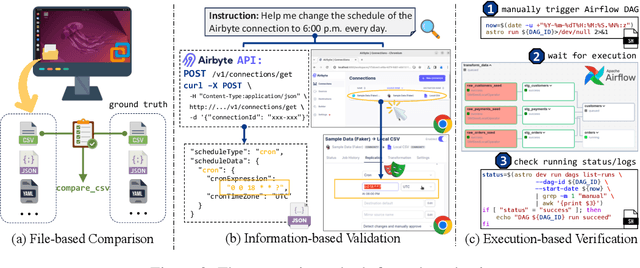
Data science and engineering workflows often span multiple stages, from warehousing to orchestration, using tools like BigQuery, dbt, and Airbyte. As vision language models (VLMs) advance in multimodal understanding and code generation, VLM-based agents could potentially automate these workflows by generating SQL queries, Python code, and GUI operations. This automation can improve the productivity of experts while democratizing access to large-scale data analysis. In this paper, we introduce Spider2-V, the first multimodal agent benchmark focusing on professional data science and engineering workflows, featuring 494 real-world tasks in authentic computer environments and incorporating 20 enterprise-level professional applications. These tasks, derived from real-world use cases, evaluate the ability of a multimodal agent to perform data-related tasks by writing code and managing the GUI in enterprise data software systems. To balance realistic simulation with evaluation simplicity, we devote significant effort to developing automatic configurations for task setup and carefully crafting evaluation metrics for each task. Furthermore, we supplement multimodal agents with comprehensive documents of these enterprise data software systems. Our empirical evaluation reveals that existing state-of-the-art LLM/VLM-based agents do not reliably automate full data workflows (14.0% success). Even with step-by-step guidance, these agents still underperform in tasks that require fine-grained, knowledge-intensive GUI actions (16.2%) and involve remote cloud-hosted workspaces (10.6%). We hope that Spider2-V paves the way for autonomous multimodal agents to transform the automation of data science and engineering workflow. Our code and data are available at https://spider2-v.github.io.