 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReducing Tool Hallucination via Reliability Alignment
Paper and Code
Dec 05, 2024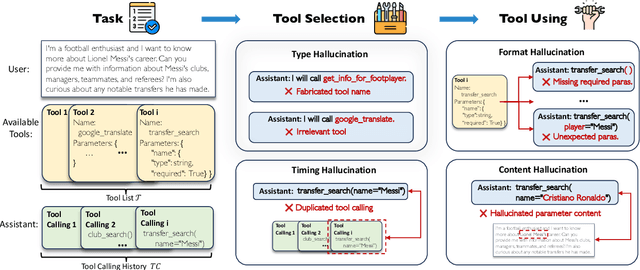
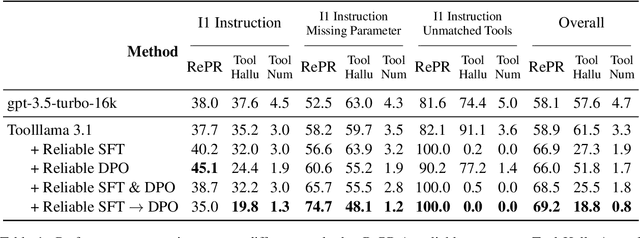
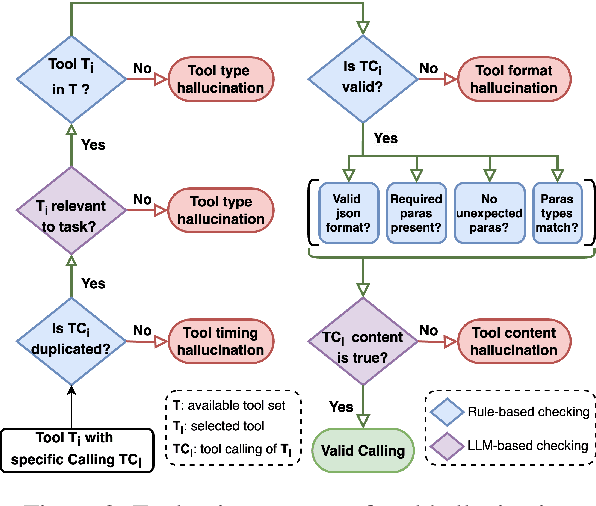
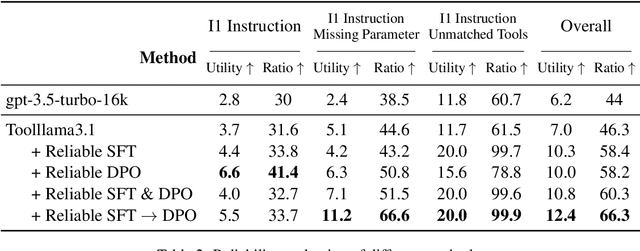
Large Language Models (LLMs) have extended their capabilities beyond language generation to interact with external systems through tool calling, offering powerful potential for real-world applications. However, the phenomenon of tool hallucinations, which occur when models improperly select or misuse tools, presents critical challenges that can lead to flawed task execution and increased operational costs. This paper investigates the concept of reliable tool calling and highlights the necessity of addressing tool hallucinations. We systematically categorize tool hallucinations into two main types: tool selection hallucination and tool usage hallucination. To mitigate these issues, we propose a reliability-focused alignment framework that enhances the model's ability to accurately assess tool relevance and usage. By proposing a suite of evaluation metrics and evaluating on StableToolBench, we further demonstrate the effectiveness of our framework in mitigating tool hallucination and improving the overall system reliability of LLM tool calling.