 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExternalizing Research Synthesis and Validation in AI Scientists through a Research Harness
Jun 17, 2026AI systems can increasingly automate scientific workflows, but the reasoning that links prior evidence, generated ideas, experiments and final claims often remains implicit inside model inference. Here we introduce Xcientist, a research harness that externalizes research synthesis and experimental validation into inspectable, contract-governed processes. Xcientist organizes literature evidence, idea states, implementation plans, ablation records and repair traces as persistent research artifacts, so that generated mechanisms can be grounded, executed, tested and revised without losing their evidential basis. We identify claim drift as a failure mode of automated research, where runnable artifacts no longer support the mechanism originally claimed. Across training-free memory systems, graph-structured traffic forecasting and multi-scale physics-informed neural networks, Xcientist preserves traceable trajectories from problem formulation to mechanism design, validation and bounded revision. These results suggest that AI scientists should be evaluated not only by their final artifacts, but by whether their synthesis and validation processes remain attributable, inspectable and scientifically accountable.
DeepSurvey: Enhancing Analytical Depth and Citation Reliability in Automated Survey Generation
May 28, 2026As scientific literature grows rapidly, automated survey generation has become a key capability for AI scientists and human researchers. However, existing systems suffer from limited analytical depth due to reliance on abstracts and isolated paper processing, and unreliable citations from imprecise retrieval and post-hoc grounding, producing superficial surveys and may mislead researchers. We present DeepSurvey, an agentic system that addresses both. To enhance depth, DeepSurvey extracts structured keynotes from full-text papers, models cross-paper relationships through clustering and comparative analysis, and integrates code-repository analysis to recover implementation-level details. To fortify reliability, it combines citation-graph expansion with hybrid filtering for topic-focussed retrieval, enforces evidence-constrained citation assignment, and deploys multi-granularity agentic refinement to validate citation-claim alignment. Experiments show that DeepSurvey achieves the highest content score (8.644/10) and citation quality (12.3% and 9.3% recall and precision gains over the strongest baseline), generalizes more robustly across domains (0.14 vs 0.22 to 0.69 CS-to-non-CS drop), and is preferred over human-written surveys by domain experts (83.3% overall quality, 100% content depth).
CharTool: Tool-Integrated Visual Reasoning for Chart Understanding
Apr 03, 2026Charts are ubiquitous in scientific and financial literature for presenting structured data. However, chart reasoning remains challenging for multimodal large language models (MLLMs) due to the lack of high-quality training data, as well as the need for fine-grained visual grounding and precise numerical computation. To address these challenges, we first propose DuoChart, a scalable dual-source data pipeline that combines synthesized charts with real-world charts to construct diverse, high-quality chart training data. We then introduce CharTool, which equips MLLMs with external tools, including image cropping for localized visual perception and code-based computation for accurate numerical reasoning. Through agentic reinforcement learning on DuoChart, CharTool learns tool-integrated reasoning grounded in chart content. Extensive experiments on six chart benchmarks show that our method consistently improves over strong MLLM baselines across model scales. Notably, CharTool-7B outperforms the base model by **+8.0%** on CharXiv (Reasoning) and **+9.78%** on ChartQAPro, while achieving competitive performance with substantially larger or proprietary models. Moreover, CharTool demonstrates positive generalization to out-of-domain visual math reasoning benchmarks.
PACER: Blockwise Pre-verification for Speculative Decoding with Adaptive Length
Feb 01, 2026Speculative decoding (SD) is a powerful technique for accelerating the inference process of large language models (LLMs) without sacrificing accuracy. Typically, SD employs a small draft model to generate a fixed number of draft tokens, which are then verified in parallel by the target model. However, our experiments reveal that the optimal draft length varies significantly across different decoding steps. This variation suggests that using a fixed draft length limits the potential for further improvements in decoding speed. To address this challenge, we propose Pacer, a novel approach that dynamically controls draft length using a lightweight, trainable pre-verification layer. This layer pre-verifies draft tokens blockwise before they are sent to the target model, allowing the draft model to stop token generation if the blockwise pre-verification fails. We implement Pacer on multiple SD model pairs and evaluate its performance across various benchmarks. Our results demonstrate that Pacer achieves up to 2.66x Speedup over autoregressive decoding and consistently outperforms standard speculative decoding. Furthermore, when integrated with Ouroboros, Pacer attains up to 3.09x Speedup.
PaperGuide: Making Small Language-Model Paper-Reading Agents More Efficient
Jan 19, 2026The accelerating growth of the scientific literature makes it increasingly difficult for researchers to track new advances through manual reading alone. Recent progress in large language models (LLMs) has therefore spurred interest in autonomous agents that can read scientific papers and extract task-relevant information. However, most existing approaches rely either on heavily engineered prompting or on a conventional SFT-RL training pipeline, both of which often lead to excessive and low-yield exploration. Drawing inspiration from cognitive science, we propose PaperCompass, a framework that mitigates these issues by separating high-level planning from fine-grained execution. PaperCompass first drafts an explicit plan that outlines the intended sequence of actions, and then performs detailed reasoning to instantiate each step by selecting the parameters for the corresponding function calls. To train such behavior, we introduce Draft-and-Follow Policy Optimization (DFPO), a tailored RL method that jointly optimizes both the draft plan and the final solution. DFPO can be viewed as a lightweight form of hierarchical reinforcement learning, aimed at narrowing the `knowing-doing' gap in LLMs. We provide a theoretical analysis that establishes DFPO's favorable optimization properties, supporting a stable and reliable training process. Experiments on paper-based question answering (Paper-QA) benchmarks show that PaperCompass improves efficiency over strong baselines without sacrificing performance, achieving results comparable to much larger models.
ChemDFM-R: An Chemical Reasoner LLM Enhanced with Atomized Chemical Knowledge
Jul 30, 2025While large language models (LLMs) have achieved impressive progress, their application in scientific domains such as chemistry remains hindered by shallow domain understanding and limited reasoning capabilities. In this work, we focus on the specific field of chemistry and develop a Chemical Reasoner LLM, ChemDFM-R. We first construct a comprehensive dataset of atomized knowledge points to enhance the model's understanding of the fundamental principles and logical structure of chemistry. Then, we propose a mix-sourced distillation strategy that integrates expert-curated knowledge with general-domain reasoning skills, followed by domain-specific reinforcement learning to enhance chemical reasoning. Experiments on diverse chemical benchmarks demonstrate that ChemDFM-R achieves cutting-edge performance while providing interpretable, rationale-driven outputs. Further case studies illustrate how explicit reasoning chains significantly improve the reliability, transparency, and practical utility of the model in real-world human-AI collaboration scenarios.
Neuronal Activation States as Sample Embeddings for Data Selection in Task-Specific Instruction Tuning
Mar 19, 2025Task-specific instruction tuning enhances the performance of large language models (LLMs) on specialized tasks, yet efficiently selecting relevant data for this purpose remains a challenge. Inspired by neural coactivation in the human brain, we propose a novel data selection method called NAS, which leverages neuronal activation states as embeddings for samples in the feature space. Extensive experiments show that NAS outperforms classical data selection methods in terms of both effectiveness and robustness across different models, datasets, and selection ratios.
AdaEAGLE: Optimizing Speculative Decoding via Explicit Modeling of Adaptive Draft Structures
Dec 25, 2024



Speculative Decoding (SD) is a popular lossless technique for accelerating the inference of Large Language Models (LLMs). We show that the decoding speed of SD frameworks with static draft structures can be significantly improved by incorporating context-aware adaptive draft structures. However, current studies on adaptive draft structures are limited by their performance, modeling approaches, and applicability. In this paper, we introduce AdaEAGLE, the first SD framework that explicitly models adaptive draft structures. AdaEAGLE leverages the Lightweight Draft Length Predictor (LDLP) module to explicitly predict the optimal number of draft tokens during inference to guide the draft model. It achieves comparable speedup results without manual thresholds and allows for deeper, more specialized optimizations. Moreover, together with threshold-based strategies, AdaEAGLE achieves a $1.62\times$ speedup over the vanilla AR decoding and outperforms fixed-length SotA baseline while maintaining output quality.
Reducing Tool Hallucination via Reliability Alignment
Dec 05, 2024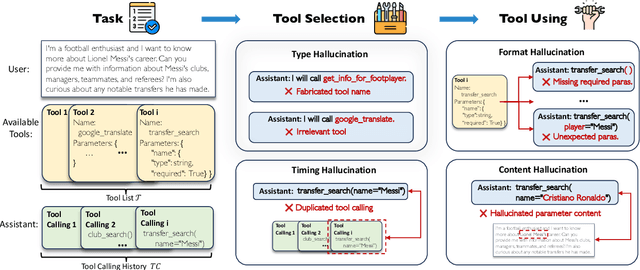
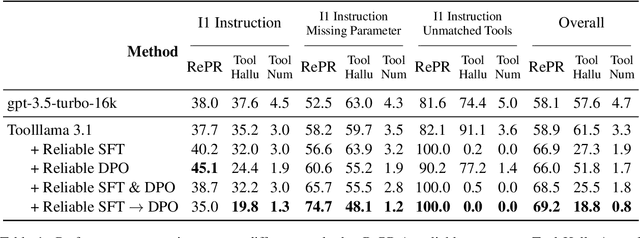
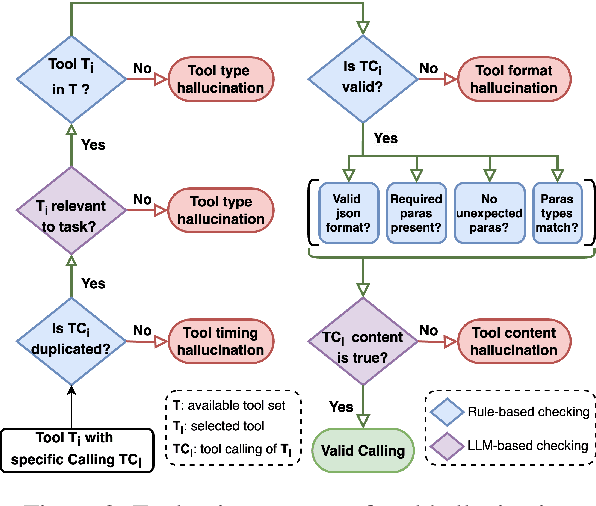
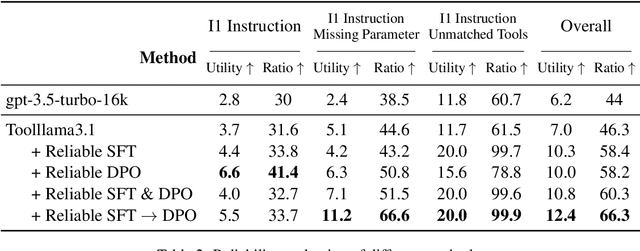
Large Language Models (LLMs) have extended their capabilities beyond language generation to interact with external systems through tool calling, offering powerful potential for real-world applications. However, the phenomenon of tool hallucinations, which occur when models improperly select or misuse tools, presents critical challenges that can lead to flawed task execution and increased operational costs. This paper investigates the concept of reliable tool calling and highlights the necessity of addressing tool hallucinations. We systematically categorize tool hallucinations into two main types: tool selection hallucination and tool usage hallucination. To mitigate these issues, we propose a reliability-focused alignment framework that enhances the model's ability to accurately assess tool relevance and usage. By proposing a suite of evaluation metrics and evaluating on StableToolBench, we further demonstrate the effectiveness of our framework in mitigating tool hallucination and improving the overall system reliability of LLM tool calling.
Compressing KV Cache for Long-Context LLM Inference with Inter-Layer Attention Similarity
Dec 03, 2024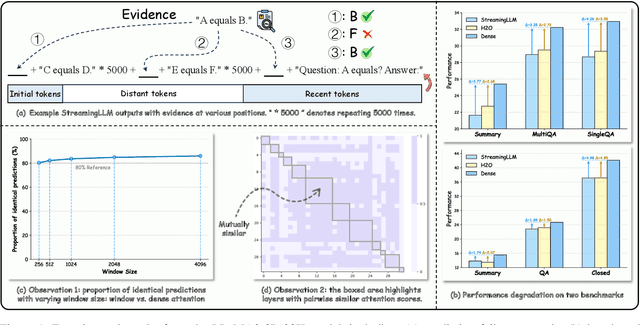



The increasing context window size in Large Language Models (LLMs), such as the GPT and LLaMA series, has improved their ability to tackle complex, long-text tasks, but at the cost of inference efficiency, particularly regarding memory and computational complexity. Existing methods, including selective token retention and window-based attention, improve efficiency but risk discarding important tokens needed for future text generation. In this paper, we propose an approach that enhances LLM efficiency without token loss by reducing the memory and computational load of less important tokens, rather than discarding them.We address two challenges: 1) investigating the distribution of important tokens in the context, discovering recent tokens are more important than distant tokens in context, and 2) optimizing resources for distant tokens by sharing attention scores across layers. The experiments show that our method saves $35\%$ KV cache without compromising the performance.