 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNo Action Without a NOD: A Heterogeneous Multi-Agent Architecture for Reliable Service Agents
May 12, 2026Large language model (LLM) agents have increasingly advanced service applications, such as booking flight tickets. However, these service agents suffer from unreliability in long-horizon tasks, as they often produce policy violations, tool hallucinations, and misaligned actions, which greatly impedes their real-world deployment. To address these challenges, we propose NOD (Navigator-Operator-Director), a heterogeneous multi-agent architecture for service agents. Instead of maintaining task state implicitly in dialogue context as in prior work, we externalize a structured Global State to enable explicit task state tracking and consistent decision-making by the Navigator. Besides, we introduce selective external oversight before critical actions, allowing an independent Director agent to verify execution and intervene when necessary. As such, NOD effectively mitigates error propagation and unsafe behavior in long-horizon tasks. Experiments on $τ^2$-Bench demonstrate that NOD achieves higher task success rates and critical action precision over baselines. More importantly, NOD improves the reliability of service agents by reducing policy violations, tool hallucinations, and user-intent misalignment.
Position: Academic Conferences are Potentially Facing Denominator Gaming Caused by Fully Automated Scientific Agents
May 11, 2026The implicit policy of maintaining relatively stable acceptance rates at top AI conferences, despite exponentially growing submissions, introduces a critical structural vulnerability. This position paper characterizes a new systemic threat we term Agentic Denominator Gaming, in which a malicious actor deploys AI agents to generate and submit a large volume of superficially plausible but low-quality papers. Crucially, their objective is not the acceptance of low-quality papers, but rather to inflate the submission denominator and overwhelm reviewing capacity. Under a relatively stable acceptance rate, this dilution can systematically increase the publication probability of a small, targeted set of legitimate papers. We analyze the practical feasibility of this threat and its broader consequences, including intensified reviewer burnout, degraded review quality, and the emergence of industrialized automated agent mills. Finally, we propose and evaluate a range of mitigation strategies, and argue that durable protection will require system-level policy and incentive reforms, rather than relying primarily on technical detection alone.
CapsID: Soft-Routed Variable-Length Semantic IDs for Generative Recommendation
May 06, 2026Generative recommendation maps each item to a sequence of Semantic IDs (SIDs) and recasts retrieval as autoregressive token generation. In this paradigm the main bottleneck is the tokenizer rather than the Transformer: residual vector quantization with a hard nearest-neighbor assignment at every layer collapses multi-faceted item semantics at cluster boundaries and propagates early errors to later SID positions. A common workaround is to append a dense vector or attribute prefix to the SID, but this dual-representation design inflates inference cost and gives up the simplicity of a generative interface. We address the bottleneck at the tokenizer itself. CAPSID replaces hard residual quantization with capsule routing: at each layer an item probabilistically routes to several semantic capsules, the residual is updated by the routed reconstruction rather than by a single winning code, and the SID terminates once the active capsule's confidence is high enough. On top of CAPSID, SEMANTICBPE composes adjacent SID tokens into reusable subwords by combining their co-occurrence with their embedding compatibility. On Amazon Beauty, Sports, Toys, and a 35M-item proprietary industrial catalog, CAPSID+SEMANTICBPE improves Recall at 10 by 9.6% on average over ReSID, the strongest single-representation baseline, and matches or exceeds a COBRA-style sparse-dense system on every public benchmark while running at 51% of its inference latency. Ablations show that soft routing, iterative agreement, and confidence-driven length each contribute independently, and the gains are largest on tail items where boundary semantics dominate.
Bohrium + SciMaster: Building the Infrastructure and Ecosystem for Agentic Science at Scale
Dec 23, 2025



AI agents are emerging as a practical way to run multi-step scientific workflows that interleave reasoning with tool use and verification, pointing to a shift from isolated AI-assisted steps toward \emph{agentic science at scale}. This shift is increasingly feasible, as scientific tools and models can be invoked through stable interfaces and verified with recorded execution traces, and increasingly necessary, as AI accelerates scientific output and stresses the peer-review and publication pipeline, raising the bar for traceability and credible evaluation. However, scaling agentic science remains difficult: workflows are hard to observe and reproduce; many tools and laboratory systems are not agent-ready; execution is hard to trace and govern; and prototype AI Scientist systems are often bespoke, limiting reuse and systematic improvement from real workflow signals. We argue that scaling agentic science requires an infrastructure-and-ecosystem approach, instantiated in Bohrium+SciMaster. Bohrium acts as a managed, traceable hub for AI4S assets -- akin to a HuggingFace of AI for Science -- that turns diverse scientific data, software, compute, and laboratory systems into agent-ready capabilities. SciMaster orchestrates these capabilities into long-horizon scientific workflows, on which scientific agents can be composed and executed. Between infrastructure and orchestration, a \emph{scientific intelligence substrate} organizes reusable models, knowledge, and components into executable building blocks for workflow reasoning and action, enabling composition, auditability, and improvement through use. We demonstrate this stack with eleven representative master agents in real workflows, achieving orders-of-magnitude reductions in end-to-end scientific cycle time and generating execution-grounded signals from real workloads at multi-million scale.
DiSRouter: Distributed Self-Routing for LLM Selections
Oct 22, 2025The proliferation of Large Language Models (LLMs) has created a diverse ecosystem of models with highly varying performance and costs, necessitating effective query routing to balance performance and expense. Current routing systems often rely on a centralized external router trained on a fixed set of LLMs, making them inflexible and prone to poor performance since the small router can not fully understand the knowledge boundaries of different LLMs. We introduce DiSRouter (Distributed Self-Router), a novel paradigm that shifts from centralized control to distributed routing. In DiSRouter, a query traverses a network of LLM agents, each independently deciding whether to answer or route to other agents based on its own self-awareness, its ability to judge its competence. This distributed design offers superior flexibility, scalability, and generalizability. To enable this, we propose a two-stage Self-Awareness Training pipeline that enhances each LLM's self-awareness. Extensive experiments demonstrate that DiSRouter significantly outperforms existing routing methods in utility across various scenarios, effectively distinguishes between easy and hard queries, and shows strong generalization to out-of-domain tasks. Our work validates that leveraging an LLM's intrinsic self-awareness is more effective than external assessment, paving the way for more modular and efficient multi-agent systems.
Enhancing LLM Reliability via Explicit Knowledge Boundary Modeling
Mar 04, 2025Large language models (LLMs) frequently hallucinate due to misaligned self-awareness, generating erroneous outputs when addressing queries beyond their knowledge boundaries. While existing approaches mitigate hallucinations via uncertainty estimation or query rejection, they suffer from computational inefficiency or sacrificed helpfulness. To address these issues, we propose the Explicit Knowledge Boundary Modeling (EKBM) framework, integrating fast and slow reasoning systems to harmonize reliability and usability. The framework first employs a fast-thinking model to generate confidence-labeled responses, enabling immediate use of high-confidence outputs. For uncertain predictions, a slow refinement model conducts targeted reasoning to improve accuracy. To align model behavior with our proposed object, we propose a hybrid training pipeline, enhancing self-awareness without degrading task performance. Evaluations on dialogue state tracking tasks demonstrate that EKBM achieves superior model reliability over uncertainty-based baselines. Further analysis reveals that refinement substantially boosts accuracy while maintaining low computational overhead. Our work establishes a scalable paradigm for advancing LLM reliability and balancing accuracy and practical utility in error-sensitive applications.
Reducing Tool Hallucination via Reliability Alignment
Dec 05, 2024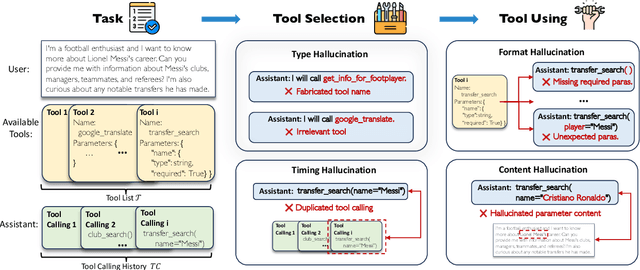
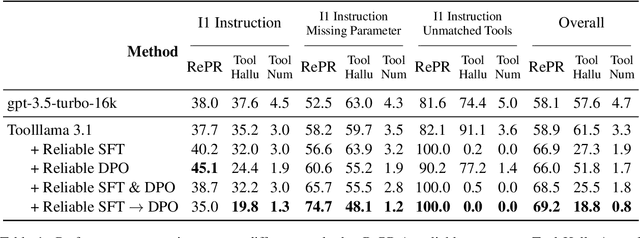
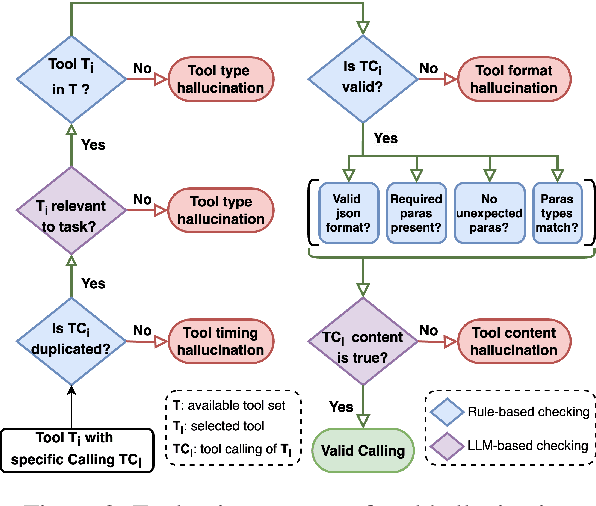
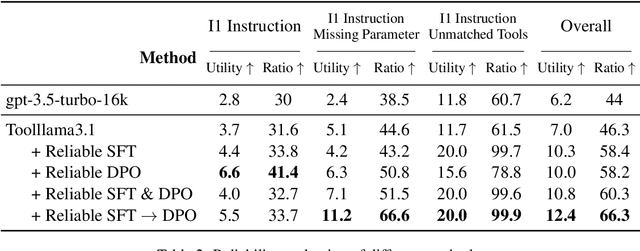
Large Language Models (LLMs) have extended their capabilities beyond language generation to interact with external systems through tool calling, offering powerful potential for real-world applications. However, the phenomenon of tool hallucinations, which occur when models improperly select or misuse tools, presents critical challenges that can lead to flawed task execution and increased operational costs. This paper investigates the concept of reliable tool calling and highlights the necessity of addressing tool hallucinations. We systematically categorize tool hallucinations into two main types: tool selection hallucination and tool usage hallucination. To mitigate these issues, we propose a reliability-focused alignment framework that enhances the model's ability to accurately assess tool relevance and usage. By proposing a suite of evaluation metrics and evaluating on StableToolBench, we further demonstrate the effectiveness of our framework in mitigating tool hallucination and improving the overall system reliability of LLM tool calling.
Uni-Mol2: Exploring Molecular Pretraining Model at Scale
Jun 21, 2024



In recent years, pretraining models have made significant advancements in the fields of natural language processing (NLP), computer vision (CV), and life sciences. The significant advancements in NLP and CV are predominantly driven by the expansion of model parameters and data size, a phenomenon now recognized as the scaling laws. However, research exploring scaling law in molecular pretraining models remains unexplored. In this work, we present Uni-Mol2 , an innovative molecular pretraining model that leverages a two-track transformer to effectively integrate features at the atomic level, graph level, and geometry structure level. Along with this, we systematically investigate the scaling law within molecular pretraining models, characterizing the power-law correlations between validation loss and model size, dataset size, and computational resources. Consequently, we successfully scale Uni-Mol2 to 1.1 billion parameters through pretraining on 800 million conformations, making it the largest molecular pretraining model to date. Extensive experiments show consistent improvement in the downstream tasks as the model size grows. The Uni-Mol2 with 1.1B parameters also outperforms existing methods, achieving an average 27% improvement on the QM9 and 14% on COMPAS-1D dataset.
Uni-Mol Docking V2: Towards Realistic and Accurate Binding Pose Prediction
May 20, 2024



In recent years, machine learning (ML) methods have emerged as promising alternatives for molecular docking, offering the potential for high accuracy without incurring prohibitive computational costs. However, recent studies have indicated that these ML models may overfit to quantitative metrics while neglecting the physical constraints inherent in the problem. In this work, we present Uni-Mol Docking V2, which demonstrates a remarkable improvement in performance, accurately predicting the binding poses of 77+% of ligands in the PoseBusters benchmark with an RMSD value of less than 2.0 {\AA}, and 75+% passing all quality checks. This represents a significant increase from the 62% achieved by the previous Uni-Mol Docking model. Notably, our Uni-Mol Docking approach generates chemically accurate predictions, circumventing issues such as chirality inversions and steric clashes that have plagued previous ML models. Furthermore, we observe enhanced performance in terms of high-quality predictions (RMSD values of less than 1.0 {\AA} and 1.5 {\AA}) and physical soundness when Uni-Mol Docking is combined with more physics-based methods like Uni-Dock. Our results represent a significant advancement in the application of artificial intelligence for scientific research, adopting a holistic approach to ligand docking that is well-suited for industrial applications in virtual screening and drug design. The code, data and service for Uni-Mol Docking are publicly available for use and further development in https://github.com/dptech-corp/Uni-Mol.
FusionFormer: A Multi-sensory Fusion in Bird's-Eye-View and Temporal Consistent Transformer for 3D Objection
Sep 11, 2023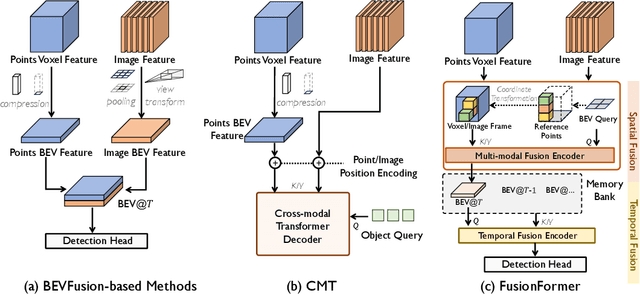
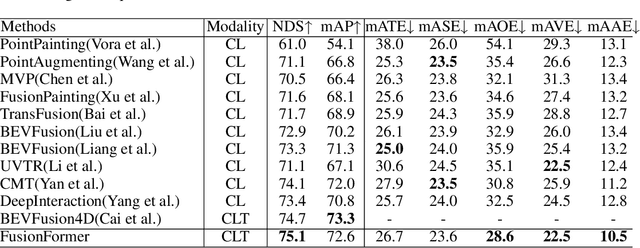
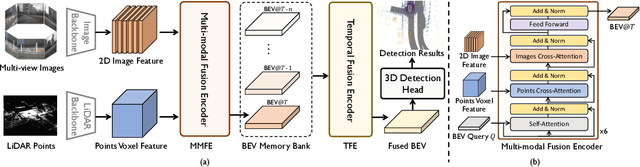
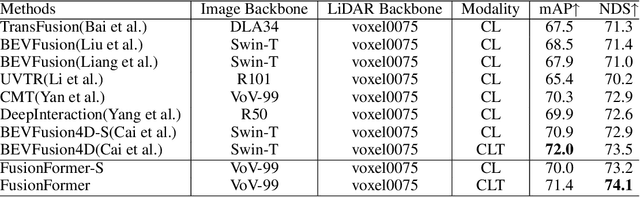
Multi-sensor modal fusion has demonstrated strong advantages in 3D object detection tasks. However, existing methods that fuse multi-modal features through a simple channel concatenation require transformation features into bird's eye view space and may lose the information on Z-axis thus leads to inferior performance. To this end, we propose FusionFormer, an end-to-end multi-modal fusion framework that leverages transformers to fuse multi-modal features and obtain fused BEV features. And based on the flexible adaptability of FusionFormer to the input modality representation, we propose a depth prediction branch that can be added to the framework to improve detection performance in camera-based detection tasks. In addition, we propose a plug-and-play temporal fusion module based on transformers that can fuse historical frame BEV features for more stable and reliable detection results. We evaluate our method on the nuScenes dataset and achieve 72.6% mAP and 75.1% NDS for 3D object detection tasks, outperforming state-of-the-art methods.