 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLanguage Driven Occupancy Prediction
Nov 25, 2024



We introduce LOcc, an effective and generalizable framework for open-vocabulary occupancy (OVO) prediction. Previous approaches typically supervise the networks through coarse voxel-to-text correspondences via image features as intermediates or noisy and sparse correspondences from voxel-based model-view projections. To alleviate the inaccurate supervision, we propose a semantic transitive labeling pipeline to generate dense and finegrained 3D language occupancy ground truth. Our pipeline presents a feasible way to dig into the valuable semantic information of images, transferring text labels from images to LiDAR point clouds and utimately to voxels, to establish precise voxel-to-text correspondences. By replacing the original prediction head of supervised occupancy models with a geometry head for binary occupancy states and a language head for language features, LOcc effectively uses the generated language ground truth to guide the learning of 3D language volume. Through extensive experiments, we demonstrate that our semantic transitive labeling pipeline can produce more accurate pseudo-labeled ground truth, diminishing labor-intensive human annotations. Additionally, we validate LOcc across various architectures, where all models consistently outperform state-ofthe-art zero-shot occupancy prediction approaches on the Occ3D-nuScenes dataset. Notably, even based on the simpler BEVDet model, with an input resolution of 256 * 704,Occ-BEVDet achieves an mIoU of 20.29, surpassing previous approaches that rely on temporal images, higher-resolution inputs, or larger backbone networks. The code for the proposed method is available at https://github.com/pkqbajng/LOcc.
FusionFormer: A Multi-sensory Fusion in Bird's-Eye-View and Temporal Consistent Transformer for 3D Objection
Sep 11, 2023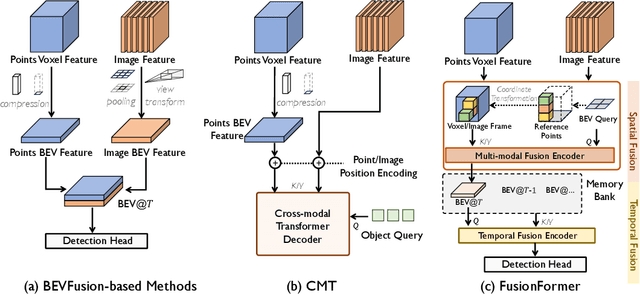
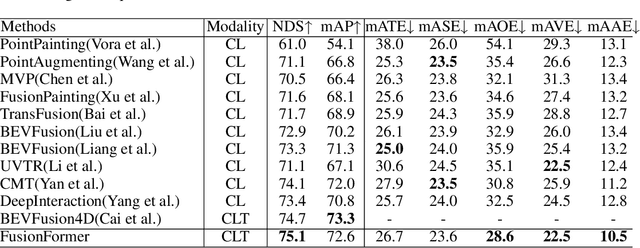
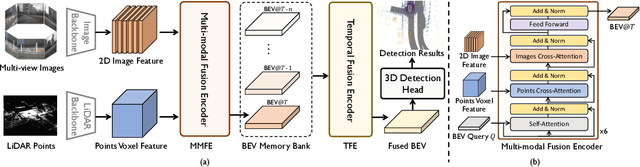
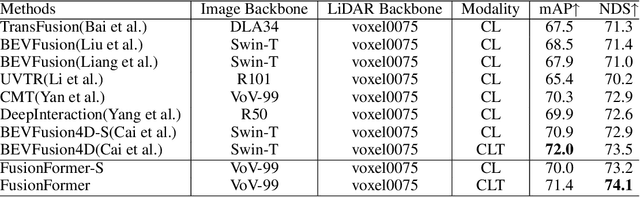
Multi-sensor modal fusion has demonstrated strong advantages in 3D object detection tasks. However, existing methods that fuse multi-modal features through a simple channel concatenation require transformation features into bird's eye view space and may lose the information on Z-axis thus leads to inferior performance. To this end, we propose FusionFormer, an end-to-end multi-modal fusion framework that leverages transformers to fuse multi-modal features and obtain fused BEV features. And based on the flexible adaptability of FusionFormer to the input modality representation, we propose a depth prediction branch that can be added to the framework to improve detection performance in camera-based detection tasks. In addition, we propose a plug-and-play temporal fusion module based on transformers that can fuse historical frame BEV features for more stable and reliable detection results. We evaluate our method on the nuScenes dataset and achieve 72.6% mAP and 75.1% NDS for 3D object detection tasks, outperforming state-of-the-art methods.
CMDFusion: Bidirectional Fusion Network with Cross-modality Knowledge Distillation for LIDAR Semantic Segmentation
Jul 09, 2023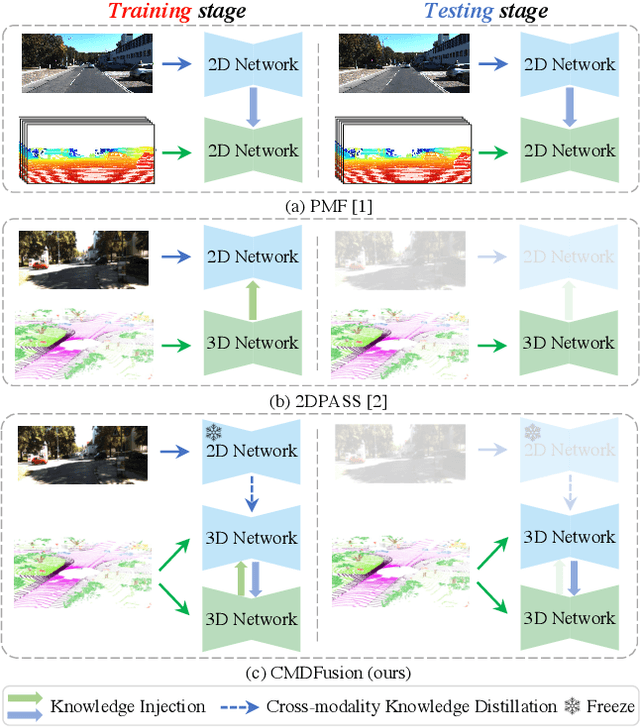
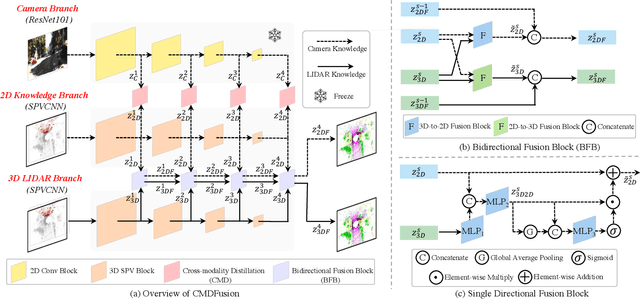
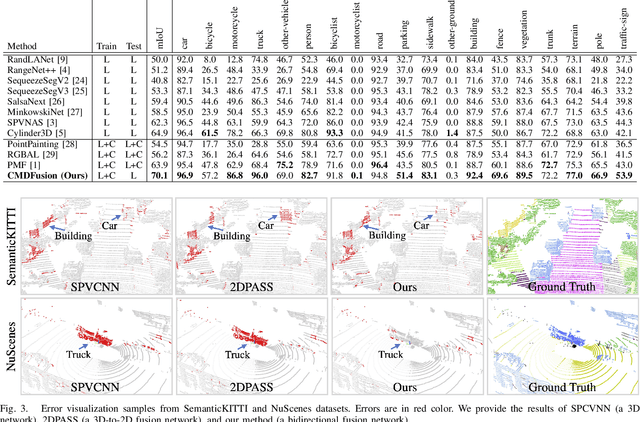

2D RGB images and 3D LIDAR point clouds provide complementary knowledge for the perception system of autonomous vehicles. Several 2D and 3D fusion methods have been explored for the LIDAR semantic segmentation task, but they suffer from different problems. 2D-to-3D fusion methods require strictly paired data during inference, which may not be available in real-world scenarios, while 3D-to-2D fusion methods cannot explicitly make full use of the 2D information. Therefore, we propose a Bidirectional Fusion Network with Cross-Modality Knowledge Distillation (CMDFusion) in this work. Our method has two contributions. First, our bidirectional fusion scheme explicitly and implicitly enhances the 3D feature via 2D-to-3D fusion and 3D-to-2D fusion, respectively, which surpasses either one of the single fusion schemes. Second, we distillate the 2D knowledge from a 2D network (Camera branch) to a 3D network (2D knowledge branch) so that the 3D network can generate 2D information even for those points not in the FOV (field of view) of the camera. In this way, RGB images are not required during inference anymore since the 2D knowledge branch provides 2D information according to the 3D LIDAR input. We show that our CMDFusion achieves the best performance among all fusion-based methods on SemanticKITTI and nuScenes datasets. The code will be released at https://github.com/Jun-CEN/CMDFusion.