 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIndustrial-Grade Sensor Simulation via Gaussian Splatting: A Modular Framework for Scalable Editing and Full-Stack Validation
Mar 14, 2025Sensor simulation is pivotal for scalable validation of autonomous driving systems, yet existing Neural Radiance Fields (NeRF) based methods face applicability and efficiency challenges in industrial workflows. This paper introduces a Gaussian Splatting (GS) based system to address these challenges: We first break down sensor simulator components and analyze the possible advantages of GS over NeRF. Then in practice, we refactor three crucial components through GS, to leverage its explicit scene representation and real-time rendering: (1) choosing the 2D neural Gaussian representation for physics-compliant scene and sensor modeling, (2) proposing a scene editing pipeline to leverage Gaussian primitives library for data augmentation, and (3) coupling a controllable diffusion model for scene expansion and harmonization. We implement this framework on a proprietary autonomous driving dataset supporting cameras and LiDAR sensors. We demonstrate through ablation studies that our approach reduces frame-wise simulation latency, achieves better geometric and photometric consistency, and enables interpretable explicit scene editing and expansion. Furthermore, we showcase how integrating such a GS-based sensor simulator with traffic and dynamic simulators enables full-stack testing of end-to-end autonomy algorithms. Our work provides both algorithmic insights and practical validation, establishing GS as a cornerstone for industrial-grade sensor simulation.
Language Driven Occupancy Prediction
Nov 25, 2024



We introduce LOcc, an effective and generalizable framework for open-vocabulary occupancy (OVO) prediction. Previous approaches typically supervise the networks through coarse voxel-to-text correspondences via image features as intermediates or noisy and sparse correspondences from voxel-based model-view projections. To alleviate the inaccurate supervision, we propose a semantic transitive labeling pipeline to generate dense and finegrained 3D language occupancy ground truth. Our pipeline presents a feasible way to dig into the valuable semantic information of images, transferring text labels from images to LiDAR point clouds and utimately to voxels, to establish precise voxel-to-text correspondences. By replacing the original prediction head of supervised occupancy models with a geometry head for binary occupancy states and a language head for language features, LOcc effectively uses the generated language ground truth to guide the learning of 3D language volume. Through extensive experiments, we demonstrate that our semantic transitive labeling pipeline can produce more accurate pseudo-labeled ground truth, diminishing labor-intensive human annotations. Additionally, we validate LOcc across various architectures, where all models consistently outperform state-ofthe-art zero-shot occupancy prediction approaches on the Occ3D-nuScenes dataset. Notably, even based on the simpler BEVDet model, with an input resolution of 256 * 704,Occ-BEVDet achieves an mIoU of 20.29, surpassing previous approaches that rely on temporal images, higher-resolution inputs, or larger backbone networks. The code for the proposed method is available at https://github.com/pkqbajng/LOcc.
SurroundSDF: Implicit 3D Scene Understanding Based on Signed Distance Field
Mar 21, 2024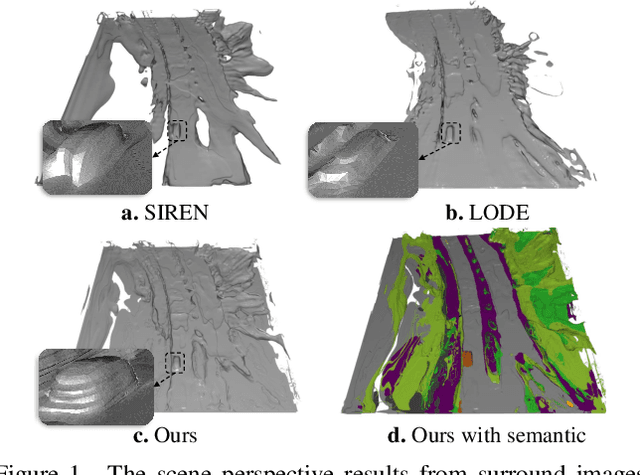



Vision-centric 3D environment understanding is both vital and challenging for autonomous driving systems. Recently, object-free methods have attracted considerable attention. Such methods perceive the world by predicting the semantics of discrete voxel grids but fail to construct continuous and accurate obstacle surfaces. To this end, in this paper, we propose SurroundSDF to implicitly predict the signed distance field (SDF) and semantic field for the continuous perception from surround images. Specifically, we introduce a query-based approach and utilize SDF constrained by the Eikonal formulation to accurately describe the surfaces of obstacles. Furthermore, considering the absence of precise SDF ground truth, we propose a novel weakly supervised paradigm for SDF, referred to as the Sandwich Eikonal formulation, which emphasizes applying correct and dense constraints on both sides of the surface, thereby enhancing the perceptual accuracy of the surface. Experiments suggest that our method achieves SOTA for both occupancy prediction and 3D scene reconstruction tasks on the nuScenes dataset.
GB-CosFace: Rethinking Softmax-based Face Recognition from the Perspective of Open Set Classification
Nov 22, 2021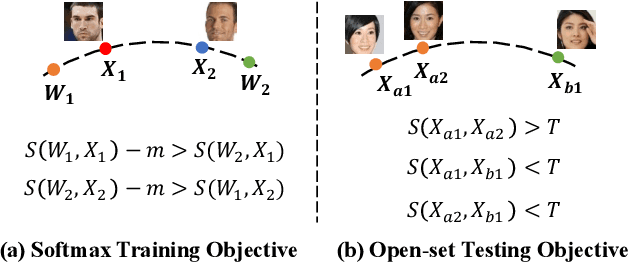
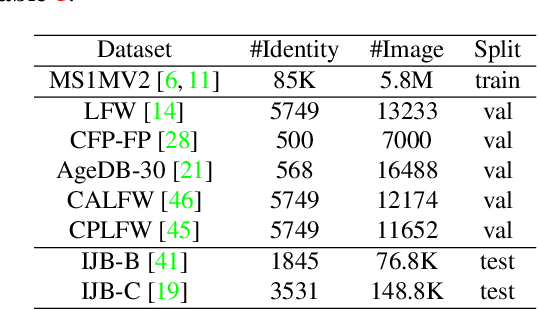
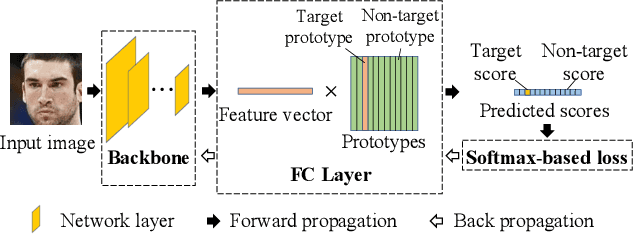
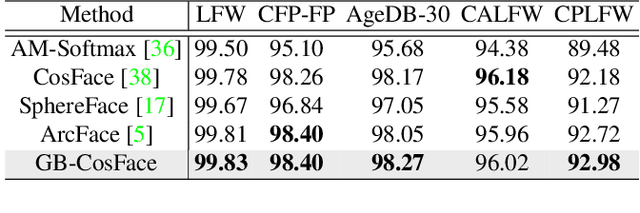
State-of-the-art face recognition methods typically take the multi-classification pipeline and adopt the softmax-based loss for optimization. Although these methods have achieved great success, the softmax-based loss has its limitation from the perspective of open set classification: the multi-classification objective in the training phase does not strictly match the objective of open set classification testing. In this paper, we derive a new loss named global boundary CosFace (GB-CosFace). Our GB-CosFace introduces an adaptive global boundary to determine whether two face samples belong to the same identity so that the optimization objective is aligned with the testing process from the perspective of open set classification. Meanwhile, since the loss formulation is derived from the softmax-based loss, our GB-CosFace retains the excellent properties of the softmax-based loss, and CosFace is proved to be a special case of the proposed loss. We analyze and explain the proposed GB-CosFace geometrically. Comprehensive experiments on multiple face recognition benchmarks indicate that the proposed GB-CosFace outperforms current state-of-the-art face recognition losses in mainstream face recognition tasks. Compared to CosFace, our GB-CosFace improves 1.58%, 0.57%, and 0.28% at TAR@FAR=1e-6, 1e-5, 1e-4 on IJB-C benchmark.
CondLaneNet: a Top-to-down Lane Detection Framework Based on Conditional Convolution
May 11, 2021
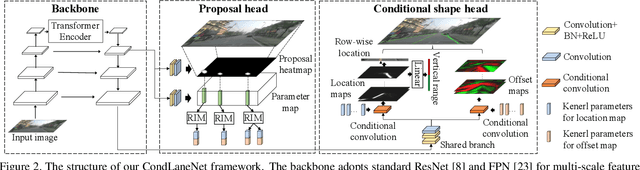

Modern deep-learning-based lane detection methods are successful in most scenarios but struggling for lane lines with complex topologies. In this work, we propose CondLaneNet, a novel top-to-down lane detection framework that detects the lane instances first and then dynamically predicts the line shape for each instance. Aiming to resolve lane instance-level discrimination problem, we introduce a conditional lane detection strategy based on conditional convolution and row-wise formulation. Further, we design the Recurrent Instance Module(RIM) to overcome the problem of detecting lane lines with complex topologies such as dense lines and fork lines. Benefit from the end-to-end pipeline which requires little post-process, our method has real-time efficiency. We extensively evaluate our method on three benchmarks of lane detection. Results show that our method achieves state-of-the-art performance on all three benchmark datasets. Moreover, our method has the coexistence of accuracy and efficiency, e.g. a 78.14 F1 score and 220 FPS on CULane.
Defective samples simulation through Neural Style Transfer for automatic surface defect segment
Oct 08, 2019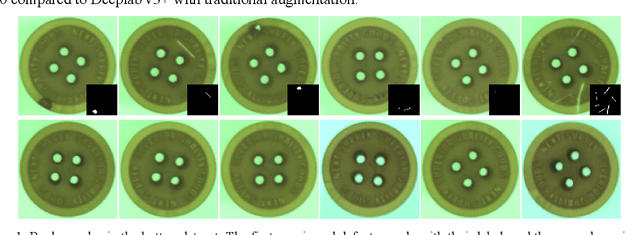

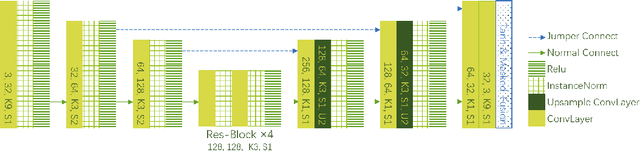
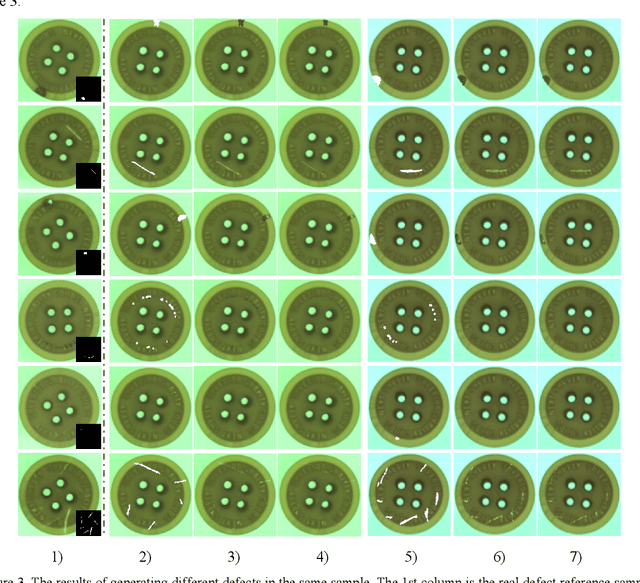
Owing to the lack of defect samples in industrial product quality inspection, trained segmentation model tends to overfit when applied online. To address this problem, we propose a defect sample simulation algorithm based on neural style transfer. The simulation algorithm requires only a small number of defect samples for training, and can efficiently generate simulation samples for next-step segmentation task. In our work, we introduce a masked histogram matching module to maintain color consistency of the generated area and the true defect. To preserve the texture consistency with the surrounding pixels, we take the fast style transfer algorithm to blend the generated area into the background. At the same time, we also use the histogram loss to further improve the quality of the generated image. Besides, we propose a novel structure of segment net to make it more suitable for defect segmentation task. We train the segment net with the real defect samples and the generated simulation samples separately on the button datasets. The results show that the F1 score of the model trained with only the generated simulation samples reaches 0.80, which is better than the real sample result.