 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisionFM: a Multi-Modal Multi-Task Vision Foundation Model for Generalist Ophthalmic Artificial Intelligence
Oct 08, 2023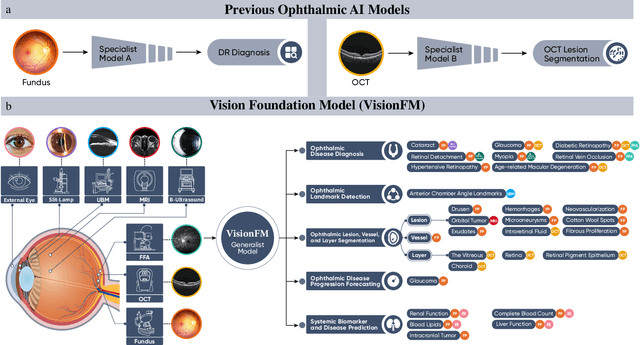
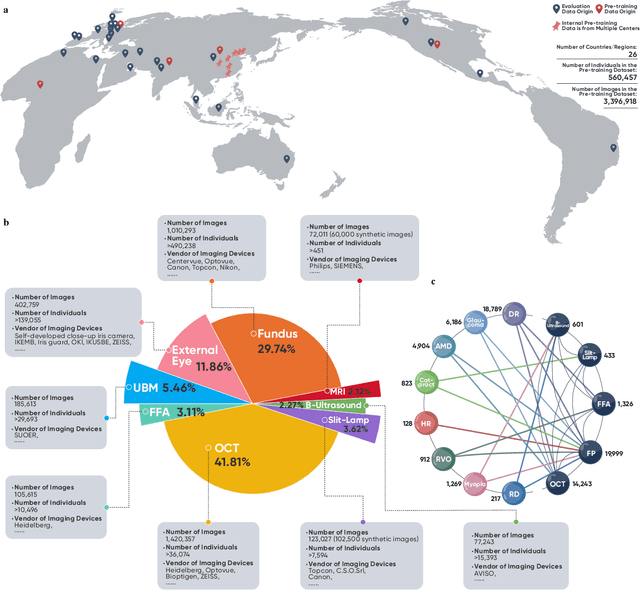

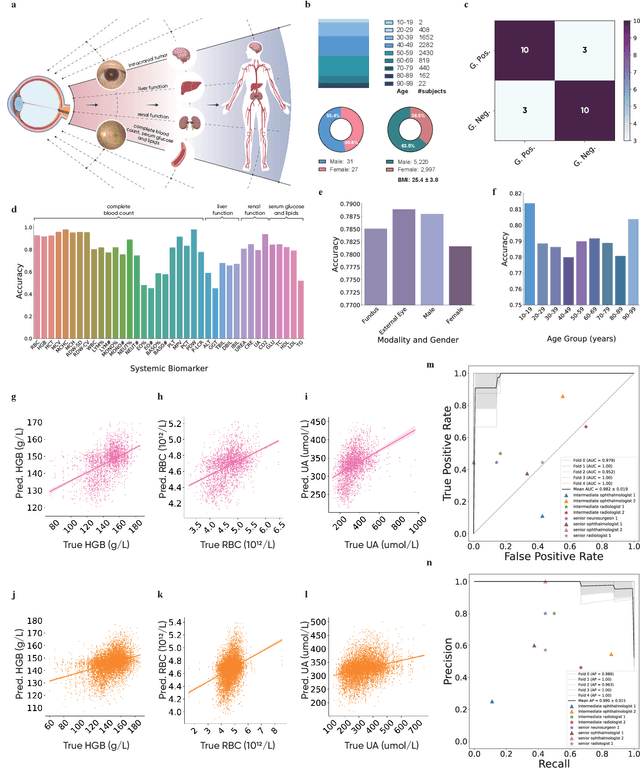
We present VisionFM, a foundation model pre-trained with 3.4 million ophthalmic images from 560,457 individuals, covering a broad range of ophthalmic diseases, modalities, imaging devices, and demography. After pre-training, VisionFM provides a foundation to foster multiple ophthalmic artificial intelligence (AI) applications, such as disease screening and diagnosis, disease prognosis, subclassification of disease phenotype, and systemic biomarker and disease prediction, with each application enhanced with expert-level intelligence and accuracy. The generalist intelligence of VisionFM outperformed ophthalmologists with basic and intermediate levels in jointly diagnosing 12 common ophthalmic diseases. Evaluated on a new large-scale ophthalmic disease diagnosis benchmark database, as well as a new large-scale segmentation and detection benchmark database, VisionFM outperformed strong baseline deep neural networks. The ophthalmic image representations learned by VisionFM exhibited noteworthy explainability, and demonstrated strong generalizability to new ophthalmic modalities, disease spectrum, and imaging devices. As a foundation model, VisionFM has a large capacity to learn from diverse ophthalmic imaging data and disparate datasets. To be commensurate with this capacity, in addition to the real data used for pre-training, we also generated and leveraged synthetic ophthalmic imaging data. Experimental results revealed that synthetic data that passed visual Turing tests, can also enhance the representation learning capability of VisionFM, leading to substantial performance gains on downstream ophthalmic AI tasks. Beyond the ophthalmic AI applications developed, validated, and demonstrated in this work, substantial further applications can be achieved in an efficient and cost-effective manner using VisionFM as the foundation.
Learning Aligned Cross-modal Representations for Referring Image Segmentation
Jan 16, 2023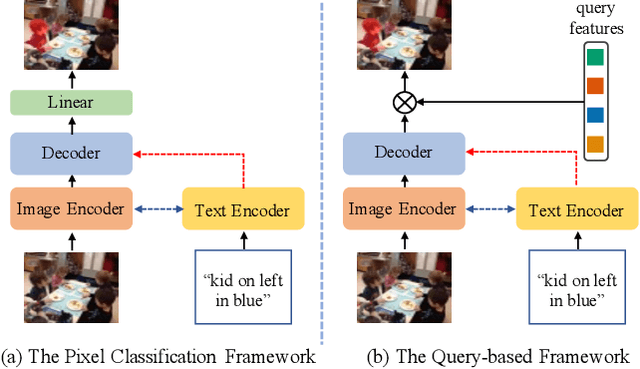
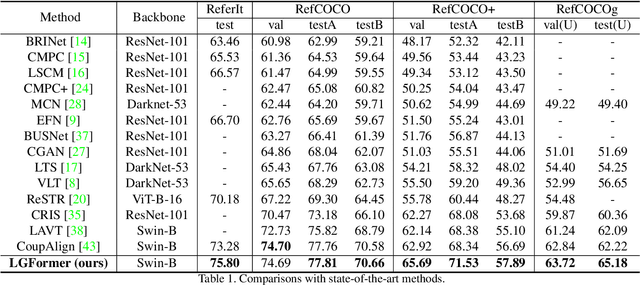

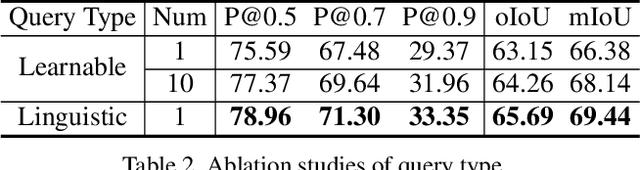
Referring image segmentation aims to segment the image region of interest according to the given language expression, which is a typical multi-modal task. One of the critical challenges of this task is to align semantic representations for different modalities including vision and language. To achieve this, previous methods perform cross-modal interactions to update visual features but ignore the role of integrating fine-grained visual features into linguistic features. We present AlignFormer, an end-to-end framework for referring image segmentation. Our AlignFormer views the linguistic feature as the center embedding and segments the region of interest by pixels grouping based on the center embedding. For achieving the pixel-text alignment, we design a Vision-Language Bidirectional Attention module (VLBA) and resort contrastive learning. Concretely, the VLBA enhances visual features by propagating semantic text representations to each pixel and promotes linguistic features by fusing fine-grained image features. Moreover, we introduce the cross-modal instance contrastive loss to alleviate the influence of pixel samples in ambiguous regions and improve the ability to align multi-modal representations. Extensive experiments demonstrate that our AlignFormer achieves a new state-of-the-art performance on RefCOCO, RefCOCO+, and RefCOCOg by large margins.
GB-CosFace: Rethinking Softmax-based Face Recognition from the Perspective of Open Set Classification
Nov 22, 2021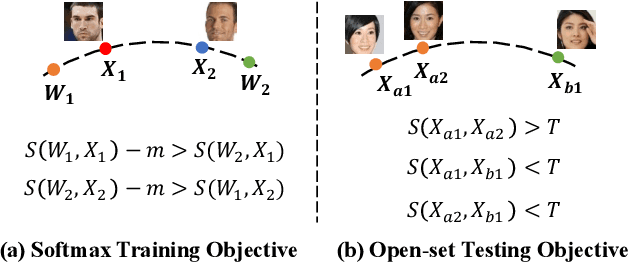
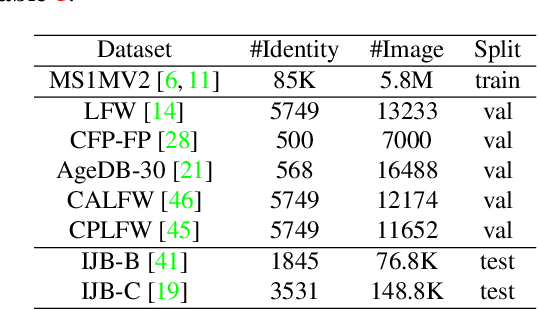
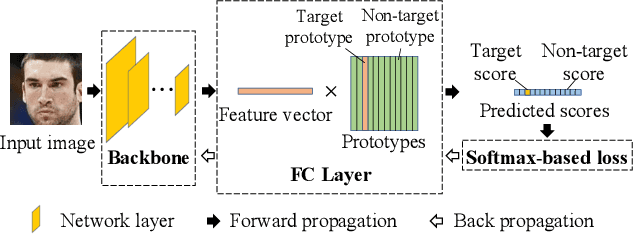
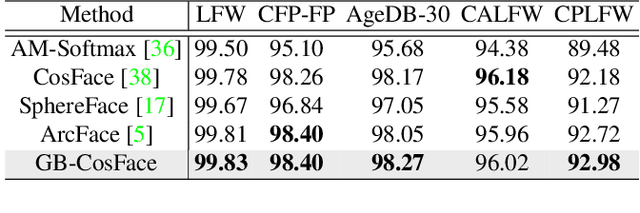
State-of-the-art face recognition methods typically take the multi-classification pipeline and adopt the softmax-based loss for optimization. Although these methods have achieved great success, the softmax-based loss has its limitation from the perspective of open set classification: the multi-classification objective in the training phase does not strictly match the objective of open set classification testing. In this paper, we derive a new loss named global boundary CosFace (GB-CosFace). Our GB-CosFace introduces an adaptive global boundary to determine whether two face samples belong to the same identity so that the optimization objective is aligned with the testing process from the perspective of open set classification. Meanwhile, since the loss formulation is derived from the softmax-based loss, our GB-CosFace retains the excellent properties of the softmax-based loss, and CosFace is proved to be a special case of the proposed loss. We analyze and explain the proposed GB-CosFace geometrically. Comprehensive experiments on multiple face recognition benchmarks indicate that the proposed GB-CosFace outperforms current state-of-the-art face recognition losses in mainstream face recognition tasks. Compared to CosFace, our GB-CosFace improves 1.58%, 0.57%, and 0.28% at TAR@FAR=1e-6, 1e-5, 1e-4 on IJB-C benchmark.
Batch Feature Erasing for Person Re-identification and Beyond
Nov 17, 2018



This paper presents a new training mechanism called Batch Feature Erasing (BFE) for person re-identification. We apply this strategy to train a novel network with two branches and employing the ResNet-50 as the backbone. The two branches consist of a conventional global branch and a feature erasing branch where the BFE strategy is applied. When training the feature erasing branch, we randomly erase the same region of all the feature maps in a batch. The network then concatenates features from the two branches for person re-identification. Albeit simple, our method achieves state-of-the-art on person re-identification and is applicable to general metric learning tasks in image retrieval problems. For instance, we achieve 75.4% Rank1 accuracy on the CUHK03-Detect dataset and 83.0% Recall-1 score on the Stanford Online Products dataset, outperforming the existed works by a large margin (more than 6%).