 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Aligned Cross-modal Representations for Referring Image Segmentation
Paper and Code
Jan 16, 2023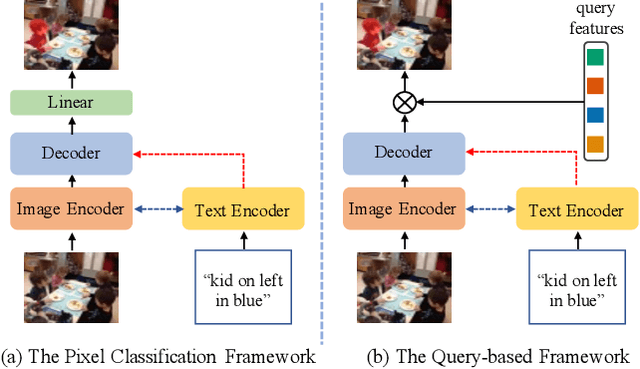
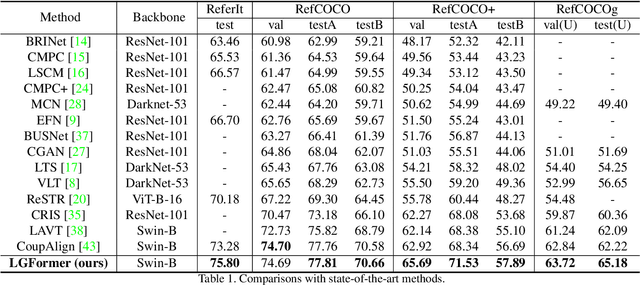

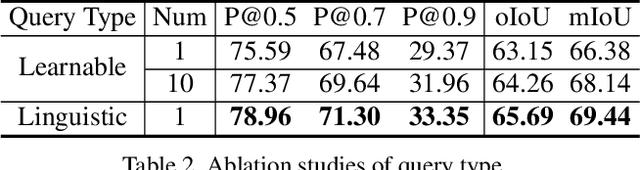
Referring image segmentation aims to segment the image region of interest according to the given language expression, which is a typical multi-modal task. One of the critical challenges of this task is to align semantic representations for different modalities including vision and language. To achieve this, previous methods perform cross-modal interactions to update visual features but ignore the role of integrating fine-grained visual features into linguistic features. We present AlignFormer, an end-to-end framework for referring image segmentation. Our AlignFormer views the linguistic feature as the center embedding and segments the region of interest by pixels grouping based on the center embedding. For achieving the pixel-text alignment, we design a Vision-Language Bidirectional Attention module (VLBA) and resort contrastive learning. Concretely, the VLBA enhances visual features by propagating semantic text representations to each pixel and promotes linguistic features by fusing fine-grained image features. Moreover, we introduce the cross-modal instance contrastive loss to alleviate the influence of pixel samples in ambiguous regions and improve the ability to align multi-modal representations. Extensive experiments demonstrate that our AlignFormer achieves a new state-of-the-art performance on RefCOCO, RefCOCO+, and RefCOCOg by large margins.