 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Robust Protective Perturbation against DeepFake Face Swapping
Dec 08, 2025DeepFake face swapping enables highly realistic identity forgeries, posing serious privacy and security risks. A common defence embeds invisible perturbations into images, but these are fragile and often destroyed by basic transformations such as compression or resizing. In this paper, we first conduct a systematic analysis of 30 transformations across six categories and show that protection robustness is highly sensitive to the choice of training transformations, making the standard Expectation over Transformation (EOT) with uniform sampling fundamentally suboptimal. Motivated by this, we propose Expectation Over Learned distribution of Transformation (EOLT), the framework to treat transformation distribution as a learnable component rather than a fixed design choice. Specifically, EOLT employs a policy network that learns to automatically prioritize critical transformations and adaptively generate instance-specific perturbations via reinforcement learning, enabling explicit modeling of defensive bottlenecks while maintaining broad transferability. Extensive experiments demonstrate that our method achieves substantial improvements over state-of-the-art approaches, with 26% higher average robustness and up to 30% gains on challenging transformation categories.
SynapseRoute: An Auto-Route Switching Framework on Dual-State Large Language Model
Jul 03, 2025With the widespread adoption of large language models (LLMs) in practical applications, selecting an appropriate model requires balancing not only performance but also operational cost. The emergence of reasoning-capable models has further widened the cost gap between "thinking" (high reasoning) and "non-thinking" (fast, low-cost) modes. In this work, we reveal that approximately 58% of medical questions can be accurately answered by the non-thinking mode alone, without requiring the high-cost reasoning process. This highlights a clear dichotomy in problem complexity and suggests that dynamically routing queries to the appropriate mode based on complexity could optimize accuracy, cost-efficiency, and overall user experience. Based on this, we further propose SynapseRoute, a machine learning-based dynamic routing framework that intelligently assigns input queries to either thinking or non-thinking modes. Experimental results on several medical datasets demonstrate that SynapseRoute not only improves overall accuracy (0.8390 vs. 0.8272) compared to the thinking mode alone but also reduces inference time by 36.8% and token consumption by 39.66%. Importantly, qualitative analysis indicates that over-reasoning on simpler queries can lead to unnecessary delays and even decreased accuracy, a pitfall avoided by our adaptive routing. Finally, this work further introduces the Accuracy-Inference-Token (AIT) index to comprehensively evaluate the trade-offs among accuracy, latency, and token cost.
Artificial Intelligence for Biomedical Video Generation
Nov 12, 2024



As a prominent subfield of Artificial Intelligence Generated Content (AIGC), video generation has achieved notable advancements in recent years. The introduction of Sora-alike models represents a pivotal breakthrough in video generation technologies, significantly enhancing the quality of synthesized videos. Particularly in the realm of biomedicine, video generation technology has shown immense potential such as medical concept explanation, disease simulation, and biomedical data augmentation. In this article, we thoroughly examine the latest developments in video generation models and explore their applications, challenges, and future opportunities in the biomedical sector. We have conducted an extensive review and compiled a comprehensive list of datasets from various sources to facilitate the development and evaluation of video generative models in biomedicine. Given the rapid progress in this field, we have also created a github repository to regularly update the advances of biomedical video generation at: https://github.com/Lee728243228/Biomedical-Video-Generation
MEDCO: Medical Education Copilots Based on A Multi-Agent Framework
Aug 22, 2024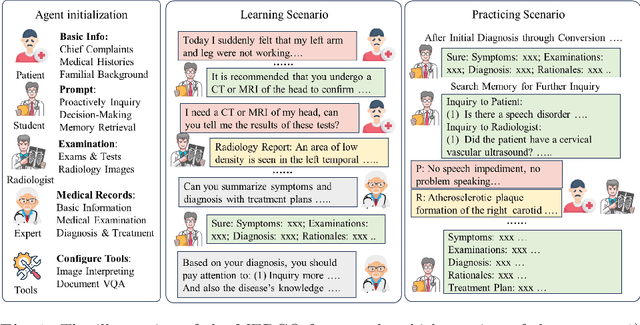
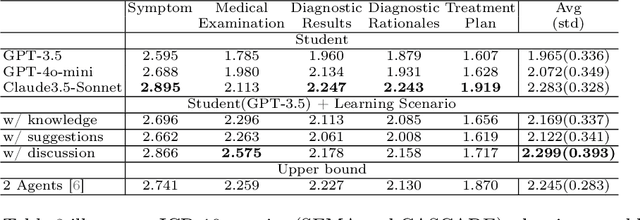

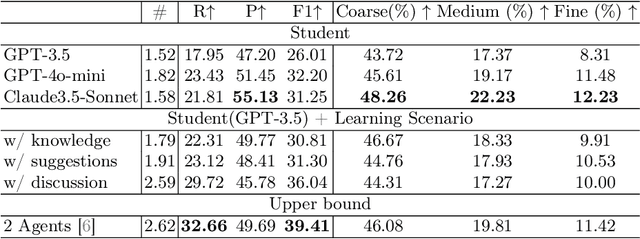
Large language models (LLMs) have had a significant impact on diverse research domains, including medicine and healthcare. However, the potential of LLMs as copilots in medical education remains underexplored. Current AI-assisted educational tools are limited by their solitary learning approach and inability to simulate the multi-disciplinary and interactive nature of actual medical training. To address these limitations, we propose MEDCO (Medical EDucation COpilots), a novel multi-agent-based copilot system specially developed to emulate real-world medical training environments. MEDCO incorporates three primary agents: an agentic patient, an expert doctor, and a radiologist, facilitating a multi-modal and interactive learning environment. Our framework emphasizes the learning of proficient question-asking skills, multi-disciplinary collaboration, and peer discussions between students. Our experiments show that simulated virtual students who underwent training with MEDCO not only achieved substantial performance enhancements comparable to those of advanced models, but also demonstrated human-like learning behaviors and improvements, coupled with an increase in the number of learning samples. This work contributes to medical education by introducing a copilot that implements an interactive and collaborative learning approach. It also provides valuable insights into the effectiveness of AI-integrated training paradigms.
One Prompt Word is Enough to Boost Adversarial Robustness for Pre-trained Vision-Language Models
Mar 04, 2024



Large pre-trained Vision-Language Models (VLMs) like CLIP, despite having remarkable generalization ability, are highly vulnerable to adversarial examples. This work studies the adversarial robustness of VLMs from the novel perspective of the text prompt instead of the extensively studied model weights (frozen in this work). We first show that the effectiveness of both adversarial attack and defense are sensitive to the used text prompt. Inspired by this, we propose a method to improve resilience to adversarial attacks by learning a robust text prompt for VLMs. The proposed method, named Adversarial Prompt Tuning (APT), is effective while being both computationally and data efficient. Extensive experiments are conducted across 15 datasets and 4 data sparsity schemes (from 1-shot to full training data settings) to show APT's superiority over hand-engineered prompts and other state-of-the-art adaption methods. APT demonstrated excellent abilities in terms of the in-distribution performance and the generalization under input distribution shift and across datasets. Surprisingly, by simply adding one learned word to the prompts, APT can significantly boost the accuracy and robustness (epsilon=4/255) over the hand-engineered prompts by +13% and +8.5% on average respectively. The improvement further increases, in our most effective setting, to +26.4% for accuracy and +16.7% for robustness. Code is available at https://github.com/TreeLLi/APT.
A Survey of Reasoning with Foundation Models
Dec 26, 2023

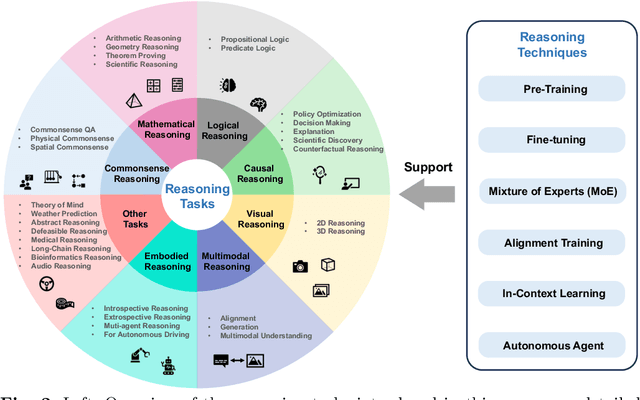

Reasoning, a crucial ability for complex problem-solving, plays a pivotal role in various real-world settings such as negotiation, medical diagnosis, and criminal investigation. It serves as a fundamental methodology in the field of Artificial General Intelligence (AGI). With the ongoing development of foundation models, there is a growing interest in exploring their abilities in reasoning tasks. In this paper, we introduce seminal foundation models proposed or adaptable for reasoning, highlighting the latest advancements in various reasoning tasks, methods, and benchmarks. We then delve into the potential future directions behind the emergence of reasoning abilities within foundation models. We also discuss the relevance of multimodal learning, autonomous agents, and super alignment in the context of reasoning. By discussing these future research directions, we hope to inspire researchers in their exploration of this field, stimulate further advancements in reasoning with foundation models, and contribute to the development of AGI.
Dietary Assessment with Multimodal ChatGPT: A Systematic Analysis
Dec 14, 2023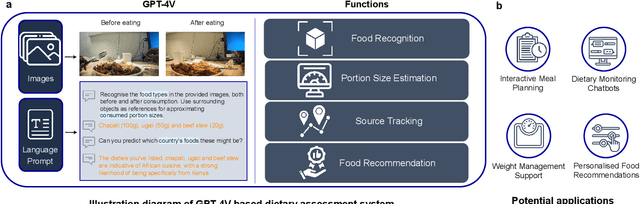

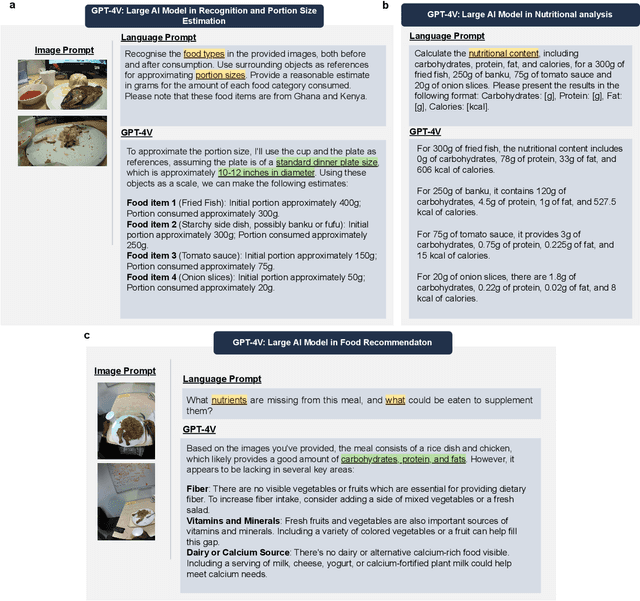

Conventional approaches to dietary assessment are primarily grounded in self-reporting methods or structured interviews conducted under the supervision of dietitians. These methods, however, are often subjective, potentially inaccurate, and time-intensive. Although artificial intelligence (AI)-based solutions have been devised to automate the dietary assessment process, these prior AI methodologies encounter challenges in their ability to generalize across a diverse range of food types, dietary behaviors, and cultural contexts. This results in AI applications in the dietary field that possess a narrow specialization and limited accuracy. Recently, the emergence of multimodal foundation models such as GPT-4V powering the latest ChatGPT has exhibited transformative potential across a wide range of tasks (e.g., Scene understanding and image captioning) in numerous research domains. These models have demonstrated remarkable generalist intelligence and accuracy, capable of processing various data modalities. In this study, we explore the application of multimodal ChatGPT within the realm of dietary assessment. Our findings reveal that GPT-4V excels in food detection under challenging conditions with accuracy up to 87.5% without any fine-tuning or adaptation using food-specific datasets. By guiding the model with specific language prompts (e.g., African cuisine), it shifts from recognizing common staples like rice and bread to accurately identifying regional dishes like banku and ugali. Another GPT-4V's standout feature is its contextual awareness. GPT-4V can leverage surrounding objects as scale references to deduce the portion sizes of food items, further enhancing its accuracy in translating food weight into nutritional content. This alignment with the USDA National Nutrient Database underscores GPT-4V's potential to advance nutritional science and dietary assessment techniques.
Aria-NeRF: Multimodal Egocentric View Synthesis
Nov 11, 2023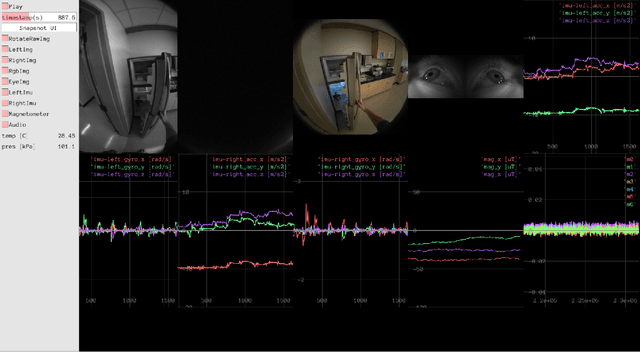
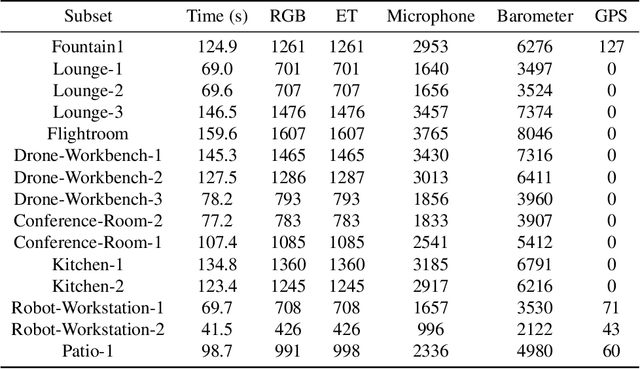

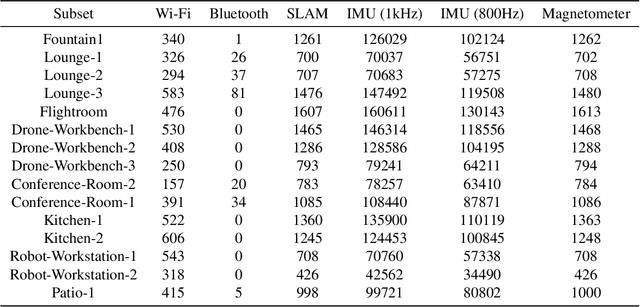
We seek to accelerate research in developing rich, multimodal scene models trained from egocentric data, based on differentiable volumetric ray-tracing inspired by Neural Radiance Fields (NeRFs). The construction of a NeRF-like model from an egocentric image sequence plays a pivotal role in understanding human behavior and holds diverse applications within the realms of VR/AR. Such egocentric NeRF-like models may be used as realistic simulations, contributing significantly to the advancement of intelligent agents capable of executing tasks in the real-world. The future of egocentric view synthesis may lead to novel environment representations going beyond today's NeRFs by augmenting visual data with multimodal sensors such as IMU for egomotion tracking, audio sensors to capture surface texture and human language context, and eye-gaze trackers to infer human attention patterns in the scene. To support and facilitate the development and evaluation of egocentric multimodal scene modeling, we present a comprehensive multimodal egocentric video dataset. This dataset offers a comprehensive collection of sensory data, featuring RGB images, eye-tracking camera footage, audio recordings from a microphone, atmospheric pressure readings from a barometer, positional coordinates from GPS, connectivity details from Wi-Fi and Bluetooth, and information from dual-frequency IMU datasets (1kHz and 800Hz) paired with a magnetometer. The dataset was collected with the Meta Aria Glasses wearable device platform. The diverse data modalities and the real-world context captured within this dataset serve as a robust foundation for furthering our understanding of human behavior and enabling more immersive and intelligent experiences in the realms of VR, AR, and robotics.
VisionFM: a Multi-Modal Multi-Task Vision Foundation Model for Generalist Ophthalmic Artificial Intelligence
Oct 08, 2023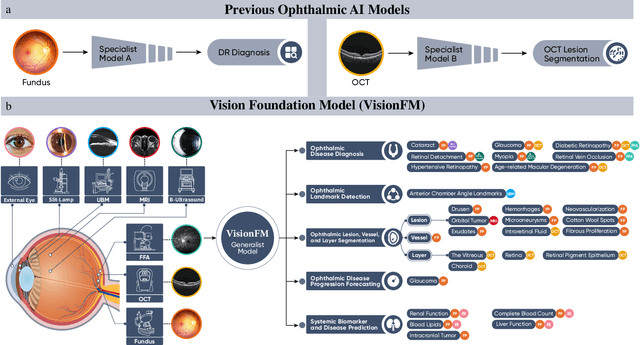
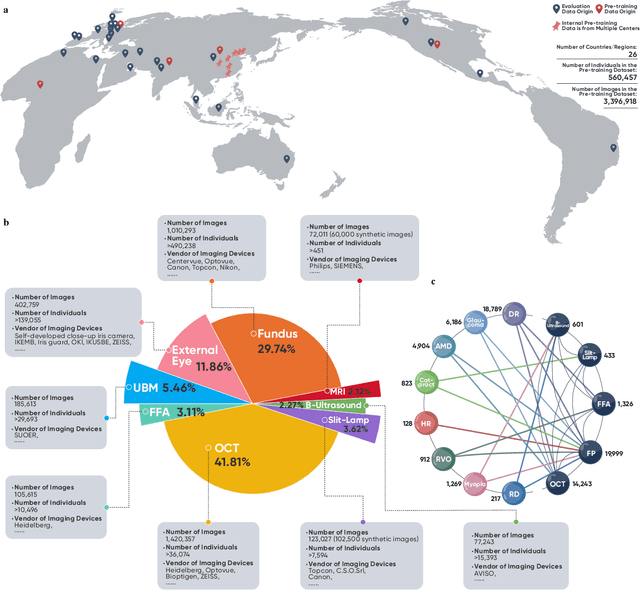

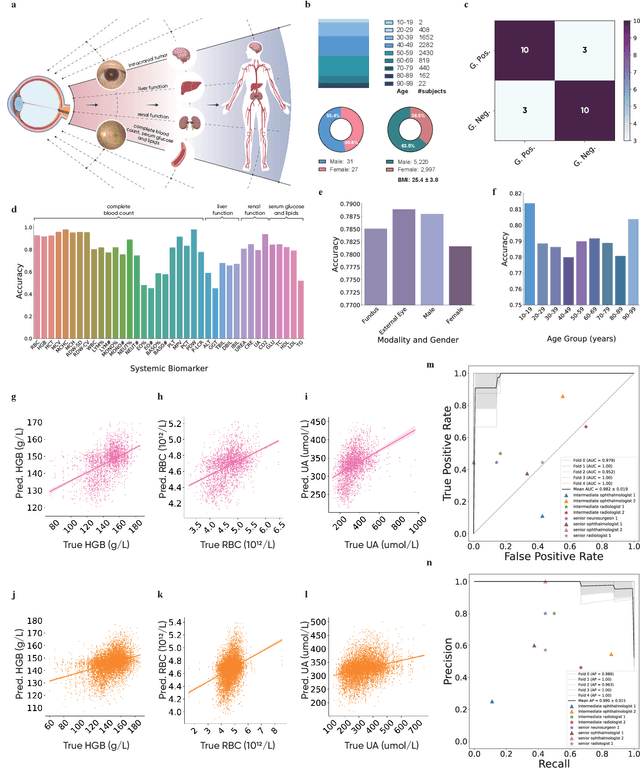
We present VisionFM, a foundation model pre-trained with 3.4 million ophthalmic images from 560,457 individuals, covering a broad range of ophthalmic diseases, modalities, imaging devices, and demography. After pre-training, VisionFM provides a foundation to foster multiple ophthalmic artificial intelligence (AI) applications, such as disease screening and diagnosis, disease prognosis, subclassification of disease phenotype, and systemic biomarker and disease prediction, with each application enhanced with expert-level intelligence and accuracy. The generalist intelligence of VisionFM outperformed ophthalmologists with basic and intermediate levels in jointly diagnosing 12 common ophthalmic diseases. Evaluated on a new large-scale ophthalmic disease diagnosis benchmark database, as well as a new large-scale segmentation and detection benchmark database, VisionFM outperformed strong baseline deep neural networks. The ophthalmic image representations learned by VisionFM exhibited noteworthy explainability, and demonstrated strong generalizability to new ophthalmic modalities, disease spectrum, and imaging devices. As a foundation model, VisionFM has a large capacity to learn from diverse ophthalmic imaging data and disparate datasets. To be commensurate with this capacity, in addition to the real data used for pre-training, we also generated and leveraged synthetic ophthalmic imaging data. Experimental results revealed that synthetic data that passed visual Turing tests, can also enhance the representation learning capability of VisionFM, leading to substantial performance gains on downstream ophthalmic AI tasks. Beyond the ophthalmic AI applications developed, validated, and demonstrated in this work, substantial further applications can be achieved in an efficient and cost-effective manner using VisionFM as the foundation.
CauDR: A Causality-inspired Domain Generalization Framework for Fundus-based Diabetic Retinopathy Grading
Sep 27, 2023Diabetic retinopathy (DR) is the most common diabetic complication, which usually leads to retinal damage, vision loss, and even blindness. A computer-aided DR grading system has a significant impact on helping ophthalmologists with rapid screening and diagnosis. Recent advances in fundus photography have precipitated the development of novel retinal imaging cameras and their subsequent implementation in clinical practice. However, most deep learning-based algorithms for DR grading demonstrate limited generalization across domains. This inferior performance stems from variance in imaging protocols and devices inducing domain shifts. We posit that declining model performance between domains arises from learning spurious correlations in the data. Incorporating do-operations from causality analysis into model architectures may mitigate this issue and improve generalizability. Specifically, a novel universal structural causal model (SCM) was proposed to analyze spurious correlations in fundus imaging. Building on this, a causality-inspired diabetic retinopathy grading framework named CauDR was developed to eliminate spurious correlations and achieve more generalizable DR diagnostics. Furthermore, existing datasets were reorganized into 4DR benchmark for DG scenario. Results demonstrate the effectiveness and the state-of-the-art (SOTA) performance of CauDR.