 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeoNorm: Unify Pre-Norm and Post-Norm with Geodesic Optimization
Jan 29, 2026The placement of normalization layers, specifically Pre-Norm and Post-Norm, remains an open question in Transformer architecture design. In this work, we rethink these approaches through the lens of manifold optimization, interpreting the outputs of the Feed-Forward Network (FFN) and attention layers as update directions in optimization. Building on this perspective, we introduce GeoNorm, a novel method that replaces standard normalization with geodesic updates on the manifold. Furthermore, analogous to learning rate schedules, we propose a layer-wise update decay for the FFN and attention components. Comprehensive experiments demonstrate that GeoNorm consistently outperforms existing normalization methods in Transformer models. Crucially, GeoNorm can be seamlessly integrated into standard Transformer architectures, achieving performance improvements with negligible additional computational cost.
Decoupled Entity Representation Learning for Pinterest Ads Ranking
Sep 04, 2025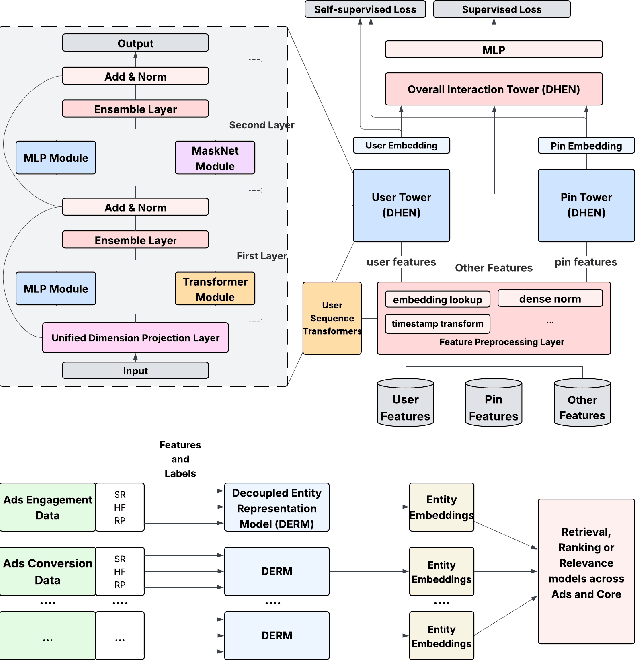



In this paper, we introduce a novel framework following an upstream-downstream paradigm to construct user and item (Pin) embeddings from diverse data sources, which are essential for Pinterest to deliver personalized Pins and ads effectively. Our upstream models are trained on extensive data sources featuring varied signals, utilizing complex architectures to capture intricate relationships between users and Pins on Pinterest. To ensure scalability of the upstream models, entity embeddings are learned, and regularly refreshed, rather than real-time computation, allowing for asynchronous interaction between the upstream and downstream models. These embeddings are then integrated as input features in numerous downstream tasks, including ad retrieval and ranking models for CTR and CVR predictions. We demonstrate that our framework achieves notable performance improvements in both offline and online settings across various downstream tasks. This framework has been deployed in Pinterest's production ad ranking systems, resulting in significant gains in online metrics.
PERRY: Policy Evaluation with Confidence Intervals using Auxiliary Data
Jul 26, 2025Off-policy evaluation (OPE) methods aim to estimate the value of a new reinforcement learning (RL) policy prior to deployment. Recent advances have shown that leveraging auxiliary datasets, such as those synthesized by generative models, can improve the accuracy of these value estimates. Unfortunately, such auxiliary datasets may also be biased, and existing methods for using data augmentation for OPE in RL lack principled uncertainty quantification. In high stakes settings like healthcare, reliable uncertainty estimates are important for comparing policy value estimates. In this work, we propose two approaches to construct valid confidence intervals for OPE when using data augmentation. The first provides a confidence interval over the policy performance conditioned on a particular initial state $V^{\pi}(s_0)$-- such intervals are particularly important for human-centered applications. To do so we introduce a new conformal prediction method for high dimensional state MDPs. Second, we consider the more common task of estimating the average policy performance over many initial states; to do so we draw on ideas from doubly robust estimation and prediction powered inference. Across simulators spanning robotics, healthcare and inventory management, and a real healthcare dataset from MIMIC-IV, we find that our methods can use augmented data and still consistently produce intervals that cover the ground truth values, unlike previously proposed methods.
SAS: Simulated Attention Score
Jul 10, 2025The attention mechanism is a core component of the Transformer architecture. Various methods have been developed to compute attention scores, including multi-head attention (MHA), multi-query attention, group-query attention and so on. We further analyze the MHA and observe that its performance improves as the number of attention heads increases, provided the hidden size per head remains sufficiently large. Therefore, increasing both the head count and hidden size per head with minimal parameter overhead can lead to significant performance gains at a low cost. Motivated by this insight, we introduce Simulated Attention Score (SAS), which maintains a compact model size while simulating a larger number of attention heads and hidden feature dimension per head. This is achieved by projecting a low-dimensional head representation into a higher-dimensional space, effectively increasing attention capacity without increasing parameter count. Beyond the head representations, we further extend the simulation approach to feature dimension of the key and query embeddings, enhancing expressiveness by mimicking the behavior of a larger model while preserving the original model size. To control the parameter cost, we also propose Parameter-Efficient Attention Aggregation (PEAA). Comprehensive experiments on a variety of datasets and tasks demonstrate the effectiveness of the proposed SAS method, achieving significant improvements over different attention variants.
Decoder-Hybrid-Decoder Architecture for Efficient Reasoning with Long Generation
Jul 09, 2025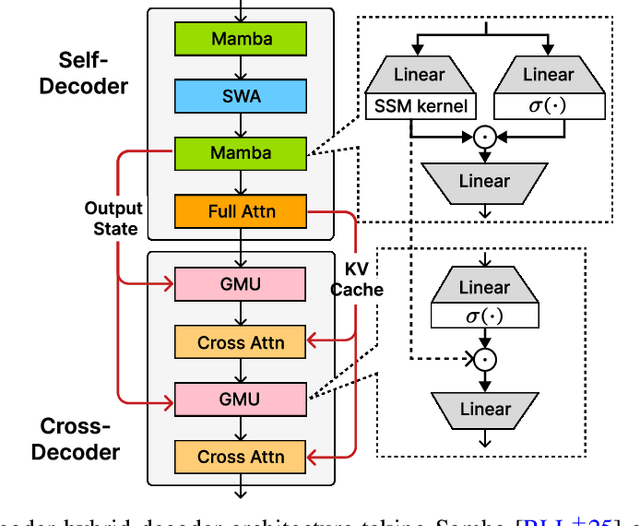
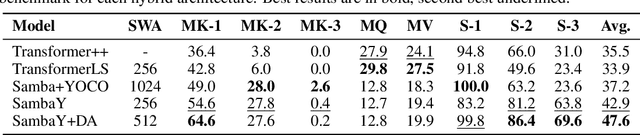
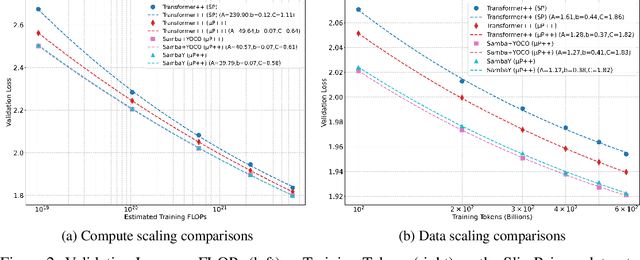
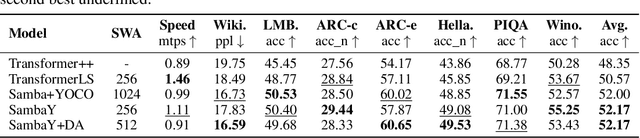
Recent advances in language modeling have demonstrated the effectiveness of State Space Models (SSMs) for efficient sequence modeling. While hybrid architectures such as Samba and the decoder-decoder architecture, YOCO, have shown promising performance gains over Transformers, prior works have not investigated the efficiency potential of representation sharing between SSM layers. In this paper, we introduce the Gated Memory Unit (GMU), a simple yet effective mechanism for efficient memory sharing across layers. We apply it to create SambaY, a decoder-hybrid-decoder architecture that incorporates GMUs in the cross-decoder to share memory readout states from a Samba-based self-decoder. SambaY significantly enhances decoding efficiency, preserves linear pre-filling time complexity, and boosts long-context performance, all while eliminating the need for explicit positional encoding. Through extensive scaling experiments, we demonstrate that our model exhibits a significantly lower irreducible loss compared to a strong YOCO baseline, indicating superior performance scalability under large-scale compute regimes. Our largest model enhanced with Differential Attention, Phi4-mini-Flash-Reasoning, achieves significantly better performance than Phi4-mini-Reasoning on reasoning tasks such as Math500, AIME24/25, and GPQA Diamond without any reinforcement learning, while delivering up to 10x higher decoding throughput on 2K-length prompts with 32K generation length under the vLLM inference framework. We release our training codebase on open-source data at https://github.com/microsoft/ArchScale.
SynapseRoute: An Auto-Route Switching Framework on Dual-State Large Language Model
Jul 03, 2025With the widespread adoption of large language models (LLMs) in practical applications, selecting an appropriate model requires balancing not only performance but also operational cost. The emergence of reasoning-capable models has further widened the cost gap between "thinking" (high reasoning) and "non-thinking" (fast, low-cost) modes. In this work, we reveal that approximately 58% of medical questions can be accurately answered by the non-thinking mode alone, without requiring the high-cost reasoning process. This highlights a clear dichotomy in problem complexity and suggests that dynamically routing queries to the appropriate mode based on complexity could optimize accuracy, cost-efficiency, and overall user experience. Based on this, we further propose SynapseRoute, a machine learning-based dynamic routing framework that intelligently assigns input queries to either thinking or non-thinking modes. Experimental results on several medical datasets demonstrate that SynapseRoute not only improves overall accuracy (0.8390 vs. 0.8272) compared to the thinking mode alone but also reduces inference time by 36.8% and token consumption by 39.66%. Importantly, qualitative analysis indicates that over-reasoning on simpler queries can lead to unnecessary delays and even decreased accuracy, a pitfall avoided by our adaptive routing. Finally, this work further introduces the Accuracy-Inference-Token (AIT) index to comprehensively evaluate the trade-offs among accuracy, latency, and token cost.
Spatial RoboGrasp: Generalized Robotic Grasping Control Policy
May 27, 2025



Achieving generalizable and precise robotic manipulation across diverse environments remains a critical challenge, largely due to limitations in spatial perception. While prior imitation-learning approaches have made progress, their reliance on raw RGB inputs and handcrafted features often leads to overfitting and poor 3D reasoning under varied lighting, occlusion, and object conditions. In this paper, we propose a unified framework that couples robust multimodal perception with reliable grasp prediction. Our architecture fuses domain-randomized augmentation, monocular depth estimation, and a depth-aware 6-DoF Grasp Prompt into a single spatial representation for downstream action planning. Conditioned on this encoding and a high-level task prompt, our diffusion-based policy yields precise action sequences, achieving up to 40% improvement in grasp success and 45% higher task success rates under environmental variation. These results demonstrate that spatially grounded perception, paired with diffusion-based imitation learning, offers a scalable and robust solution for general-purpose robotic grasping.
SeqPO-SiMT: Sequential Policy Optimization for Simultaneous Machine Translation
May 27, 2025



We present Sequential Policy Optimization for Simultaneous Machine Translation (SeqPO-SiMT), a new policy optimization framework that defines the simultaneous machine translation (SiMT) task as a sequential decision making problem, incorporating a tailored reward to enhance translation quality while reducing latency. In contrast to popular Reinforcement Learning from Human Feedback (RLHF) methods, such as PPO and DPO, which are typically applied in single-step tasks, SeqPO-SiMT effectively tackles the multi-step SiMT task. This intuitive framework allows the SiMT LLMs to simulate and refine the SiMT process using a tailored reward. We conduct experiments on six datasets from diverse domains for En to Zh and Zh to En SiMT tasks, demonstrating that SeqPO-SiMT consistently achieves significantly higher translation quality with lower latency. In particular, SeqPO-SiMT outperforms the supervised fine-tuning (SFT) model by 1.13 points in COMET, while reducing the Average Lagging by 6.17 in the NEWSTEST2021 En to Zh dataset. While SiMT operates with far less context than offline translation, the SiMT results of SeqPO-SiMT on 7B LLM surprisingly rival the offline translation of high-performing LLMs, including Qwen-2.5-7B-Instruct and LLaMA-3-8B-Instruct.
Privacy Preserving Conversion Modeling in Data Clean Room
May 20, 2025In the realm of online advertising, accurately predicting the conversion rate (CVR) is crucial for enhancing advertising efficiency and user satisfaction. This paper addresses the challenge of CVR prediction while adhering to user privacy preferences and advertiser requirements. Traditional methods face obstacles such as the reluctance of advertisers to share sensitive conversion data and the limitations of model training in secure environments like data clean rooms. We propose a novel model training framework that enables collaborative model training without sharing sample-level gradients with the advertising platform. Our approach introduces several innovative components: (1) utilizing batch-level aggregated gradients instead of sample-level gradients to minimize privacy risks; (2) applying adapter-based parameter-efficient fine-tuning and gradient compression to reduce communication costs; and (3) employing de-biasing techniques to train the model under label differential privacy, thereby maintaining accuracy despite privacy-enhanced label perturbations. Our experimental results, conducted on industrial datasets, demonstrate that our method achieves competitive ROCAUC performance while significantly decreasing communication overhead and complying with both advertiser privacy requirements and user privacy choices. This framework establishes a new standard for privacy-preserving, high-performance CVR prediction in the digital advertising landscape.
CoinRobot: Generalized End-to-end Robotic Learning for Physical Intelligence
Mar 07, 2025Physical intelligence holds immense promise for advancing embodied intelligence, enabling robots to acquire complex behaviors from demonstrations. However, achieving generalization and transfer across diverse robotic platforms and environments requires careful design of model architectures, training strategies, and data diversity. Meanwhile existing systems often struggle with scalability, adaptability to heterogeneous hardware, and objective evaluation in real-world settings. We present a generalized end-to-end robotic learning framework designed to bridge this gap. Our framework introduces a unified architecture that supports cross-platform adaptability, enabling seamless deployment across industrial-grade robots, collaborative arms, and novel embodiments without task-specific modifications. By integrating multi-task learning with streamlined network designs, it achieves more robust performance than conventional approaches, while maintaining compatibility with varying sensor configurations and action spaces. We validate our framework through extensive experiments on seven manipulation tasks. Notably, Diffusion-based models trained in our framework demonstrated superior performance and generalizability compared to the LeRobot framework, achieving performance improvements across diverse robotic platforms and environmental conditions.