 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBEHAVIOR Robot Suite: Streamlining Real-World Whole-Body Manipulation for Everyday Household Activities
Mar 07, 2025Real-world household tasks present significant challenges for mobile manipulation robots. An analysis of existing robotics benchmarks reveals that successful task performance hinges on three key whole-body control capabilities: bimanual coordination, stable and precise navigation, and extensive end-effector reachability. Achieving these capabilities requires careful hardware design, but the resulting system complexity further complicates visuomotor policy learning. To address these challenges, we introduce the BEHAVIOR Robot Suite (BRS), a comprehensive framework for whole-body manipulation in diverse household tasks. Built on a bimanual, wheeled robot with a 4-DoF torso, BRS integrates a cost-effective whole-body teleoperation interface for data collection and a novel algorithm for learning whole-body visuomotor policies. We evaluate BRS on five challenging household tasks that not only emphasize the three core capabilities but also introduce additional complexities, such as long-range navigation, interaction with articulated and deformable objects, and manipulation in confined spaces. We believe that BRS's integrated robotic embodiment, data collection interface, and learning framework mark a significant step toward enabling real-world whole-body manipulation for everyday household tasks. BRS is open-sourced at https://behavior-robot-suite.github.io/
ACDC: Automated Creation of Digital Cousins for Robust Policy Learning
Oct 09, 2024



Training robot policies in the real world can be unsafe, costly, and difficult to scale. Simulation serves as an inexpensive and potentially limitless source of training data, but suffers from the semantics and physics disparity beween simulated and real-world environments. These discrepancies can be minimized by training in digital twins,which serve as virtual replicas of a real scene but are expensive to generate and cannot produce cross-domain generalization. To address these limitations, we propose the concept of digital cousins, a virtual asset or scene that, unlike a digital twin,does not explicitly model a real-world counterpart but still exhibits similar geometric and semantic affordances. As a result, digital cousins simultaneously reduce the cost of generating an analogous virtual environment while also facilitating better robustness during sim-to-real domain transfer by providing a distribution of similar training scenes. Leveraging digital cousins, we introduce a novel method for the Automatic Creation of Digital Cousins (ACDC), and propose a fully automated real-to-sim-to-real pipeline for generating fully interactive scenes and training robot policies that can be deployed zero-shot in the original scene. We find that ACDC can produce digital cousin scenes that preserve geometric and semantic affordances, and can be used to train policies that outperform policies trained on digital twins, achieving 90% vs. 25% under zero-shot sim-to-real transfer. Additional details are available at https://digital-cousins.github.io/.
BEHAVIOR Vision Suite: Customizable Dataset Generation via Simulation
May 15, 2024



The systematic evaluation and understanding of computer vision models under varying conditions require large amounts of data with comprehensive and customized labels, which real-world vision datasets rarely satisfy. While current synthetic data generators offer a promising alternative, particularly for embodied AI tasks, they often fall short for computer vision tasks due to low asset and rendering quality, limited diversity, and unrealistic physical properties. We introduce the BEHAVIOR Vision Suite (BVS), a set of tools and assets to generate fully customized synthetic data for systematic evaluation of computer vision models, based on the newly developed embodied AI benchmark, BEHAVIOR-1K. BVS supports a large number of adjustable parameters at the scene level (e.g., lighting, object placement), the object level (e.g., joint configuration, attributes such as "filled" and "folded"), and the camera level (e.g., field of view, focal length). Researchers can arbitrarily vary these parameters during data generation to perform controlled experiments. We showcase three example application scenarios: systematically evaluating the robustness of models across different continuous axes of domain shift, evaluating scene understanding models on the same set of images, and training and evaluating simulation-to-real transfer for a novel vision task: unary and binary state prediction. Project website: https://behavior-vision-suite.github.io/
BEHAVIOR-1K: A Human-Centered, Embodied AI Benchmark with 1,000 Everyday Activities and Realistic Simulation
Mar 14, 2024



We present BEHAVIOR-1K, a comprehensive simulation benchmark for human-centered robotics. BEHAVIOR-1K includes two components, guided and motivated by the results of an extensive survey on "what do you want robots to do for you?". The first is the definition of 1,000 everyday activities, grounded in 50 scenes (houses, gardens, restaurants, offices, etc.) with more than 9,000 objects annotated with rich physical and semantic properties. The second is OMNIGIBSON, a novel simulation environment that supports these activities via realistic physics simulation and rendering of rigid bodies, deformable bodies, and liquids. Our experiments indicate that the activities in BEHAVIOR-1K are long-horizon and dependent on complex manipulation skills, both of which remain a challenge for even state-of-the-art robot learning solutions. To calibrate the simulation-to-reality gap of BEHAVIOR-1K, we provide an initial study on transferring solutions learned with a mobile manipulator in a simulated apartment to its real-world counterpart. We hope that BEHAVIOR-1K's human-grounded nature, diversity, and realism make it valuable for embodied AI and robot learning research. Project website: https://behavior.stanford.edu.
Error-Aware Imitation Learning from Teleoperation Data for Mobile Manipulation
Dec 09, 2021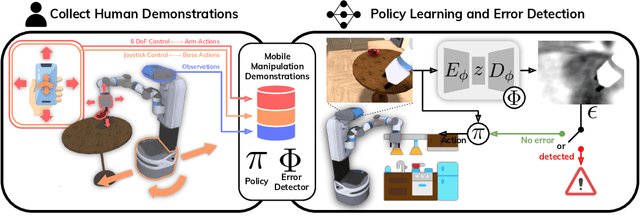
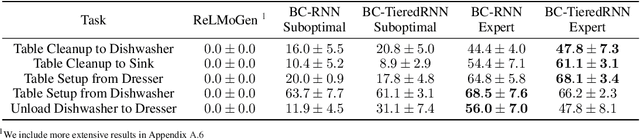

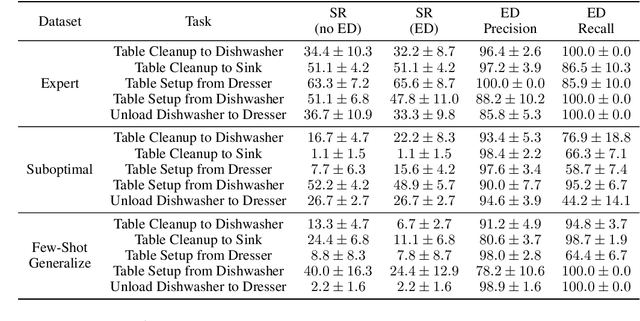
In mobile manipulation (MM), robots can both navigate within and interact with their environment and are thus able to complete many more tasks than robots only capable of navigation or manipulation. In this work, we explore how to apply imitation learning (IL) to learn continuous visuo-motor policies for MM tasks. Much prior work has shown that IL can train visuo-motor policies for either manipulation or navigation domains, but few works have applied IL to the MM domain. Doing this is challenging for two reasons: on the data side, current interfaces make collecting high-quality human demonstrations difficult, and on the learning side, policies trained on limited data can suffer from covariate shift when deployed. To address these problems, we first propose Mobile Manipulation RoboTurk (MoMaRT), a novel teleoperation framework allowing simultaneous navigation and manipulation of mobile manipulators, and collect a first-of-its-kind large scale dataset in a realistic simulated kitchen setting. We then propose a learned error detection system to address the covariate shift by detecting when an agent is in a potential failure state. We train performant IL policies and error detectors from this data, and achieve over 45% task success rate and 85% error detection success rate across multiple multi-stage tasks when trained on expert data. Codebase, datasets, visualization, and more available at https://sites.google.com/view/il-for-mm/home.
OSCAR: Data-Driven Operational Space Control for Adaptive and Robust Robot Manipulation
Oct 02, 2021
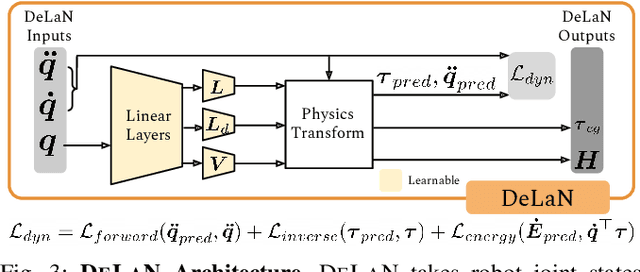
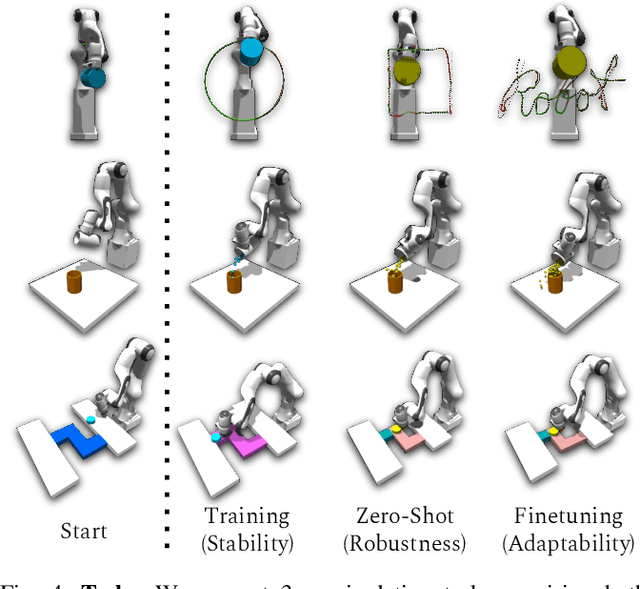

Learning performant robot manipulation policies can be challenging due to high-dimensional continuous actions and complex physics-based dynamics. This can be alleviated through intelligent choice of action space. Operational Space Control (OSC) has been used as an effective task-space controller for manipulation. Nonetheless, its strength depends on the underlying modeling fidelity, and is prone to failure when there are modeling errors. In this work, we propose OSC for Adaptation and Robustness (OSCAR), a data-driven variant of OSC that compensates for modeling errors by inferring relevant dynamics parameters from online trajectories. OSCAR decomposes dynamics learning into task-agnostic and task-specific phases, decoupling the dynamics dependencies of the robot and the extrinsics due to its environment. This structure enables robust zero-shot performance under out-of-distribution and rapid adaptation to significant domain shifts through additional finetuning. We evaluate our method on a variety of simulated manipulation problems, and find substantial improvements over an array of controller baselines. For more results and information, please visit https://cremebrule.github.io/oscar-web/.
What Matters in Learning from Offline Human Demonstrations for Robot Manipulation
Aug 06, 2021
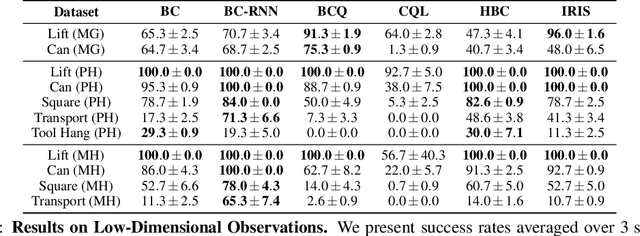
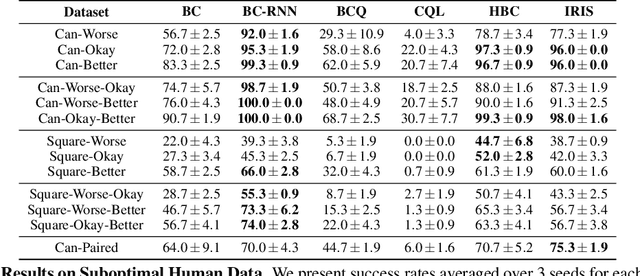
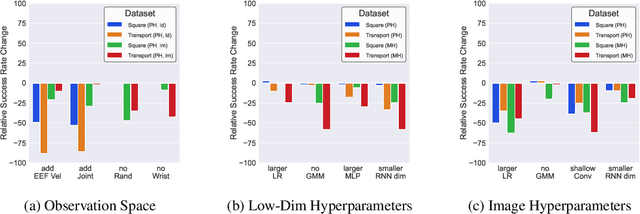
Imitating human demonstrations is a promising approach to endow robots with various manipulation capabilities. While recent advances have been made in imitation learning and batch (offline) reinforcement learning, a lack of open-source human datasets and reproducible learning methods make assessing the state of the field difficult. In this paper, we conduct an extensive study of six offline learning algorithms for robot manipulation on five simulated and three real-world multi-stage manipulation tasks of varying complexity, and with datasets of varying quality. Our study analyzes the most critical challenges when learning from offline human data for manipulation. Based on the study, we derive a series of lessons including the sensitivity to different algorithmic design choices, the dependence on the quality of the demonstrations, and the variability based on the stopping criteria due to the different objectives in training and evaluation. We also highlight opportunities for learning from human datasets, such as the ability to learn proficient policies on challenging, multi-stage tasks beyond the scope of current reinforcement learning methods, and the ability to easily scale to natural, real-world manipulation scenarios where only raw sensory signals are available. We have open-sourced our datasets and all algorithm implementations to facilitate future research and fair comparisons in learning from human demonstration data. Codebase, datasets, trained models, and more available at https://arise-initiative.github.io/robomimic-web/
Learning Multi-Arm Manipulation Through Collaborative Teleoperation
Dec 12, 2020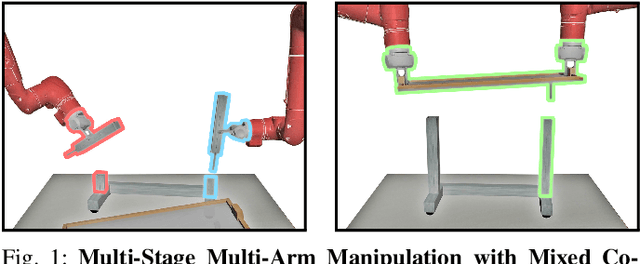
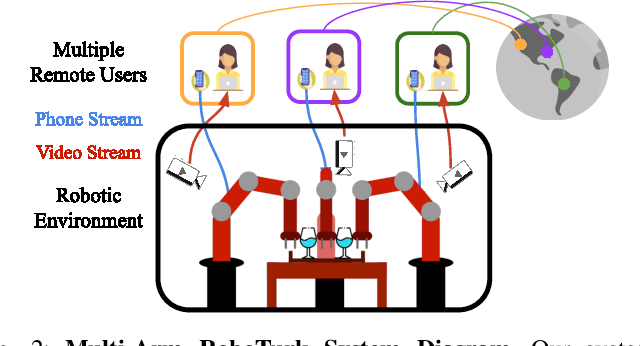

Imitation Learning (IL) is a powerful paradigm to teach robots to perform manipulation tasks by allowing them to learn from human demonstrations collected via teleoperation, but has mostly been limited to single-arm manipulation. However, many real-world tasks require multiple arms, such as lifting a heavy object or assembling a desk. Unfortunately, applying IL to multi-arm manipulation tasks has been challenging -- asking a human to control more than one robotic arm can impose significant cognitive burden and is often only possible for a maximum of two robot arms. To address these challenges, we present Multi-Arm RoboTurk (MART), a multi-user data collection platform that allows multiple remote users to simultaneously teleoperate a set of robotic arms and collect demonstrations for multi-arm tasks. Using MART, we collected demonstrations for five novel two and three-arm tasks from several geographically separated users. From our data we arrived at a critical insight: most multi-arm tasks do not require global coordination throughout its full duration, but only during specific moments. We show that learning from such data consequently presents challenges for centralized agents that directly attempt to model all robot actions simultaneously, and perform a comprehensive study of different policy architectures with varying levels of centralization on our tasks. Finally, we propose and evaluate a base-residual policy framework that allows trained policies to better adapt to the mixed coordination setting common in multi-arm manipulation, and show that a centralized policy augmented with a decentralized residual model outperforms all other models on our set of benchmark tasks. Additional results and videos at https://roboturk.stanford.edu/multiarm .
robosuite: A Modular Simulation Framework and Benchmark for Robot Learning
Sep 25, 2020
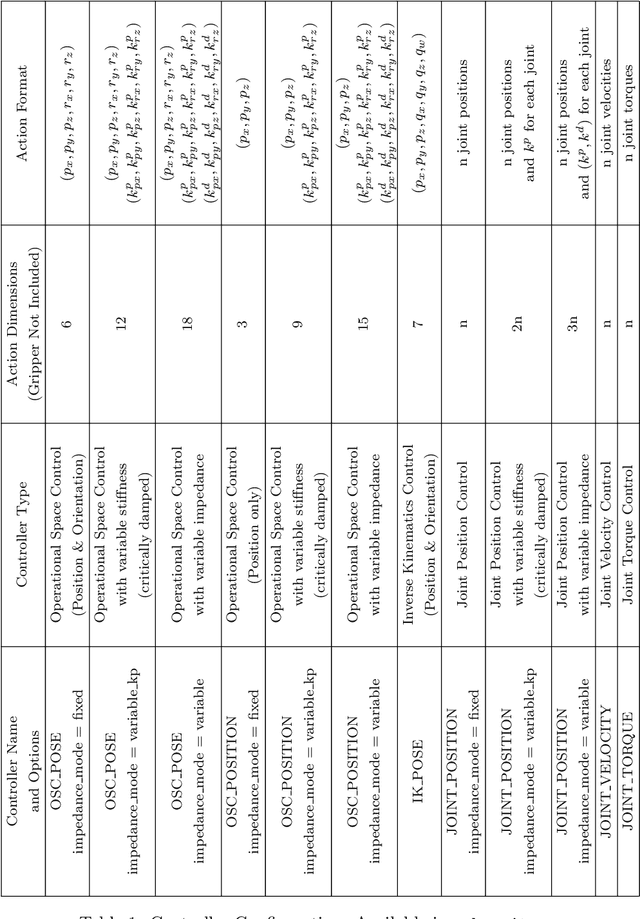
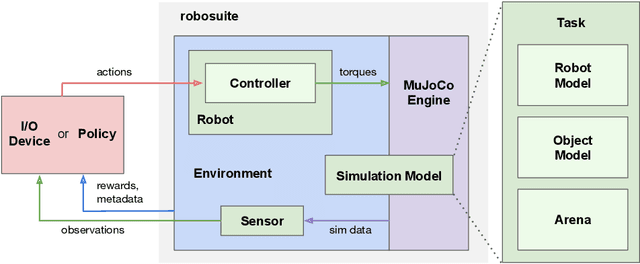
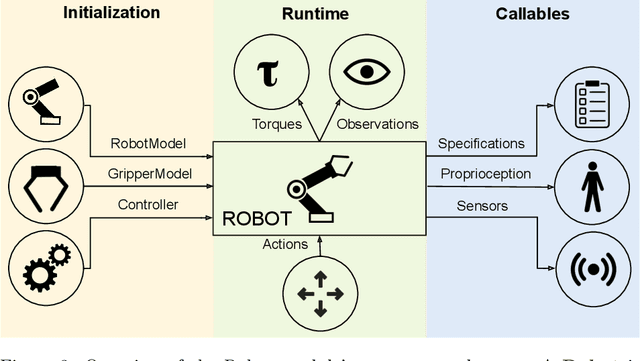
robosuite is a simulation framework for robot learning powered by the MuJoCo physics engine. It offers a modular design for creating robotic tasks as well as a suite of benchmark environments for reproducible research. This paper discusses the key system modules and the benchmark environments of our new release robosuite v1.0.