 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeError-Aware Imitation Learning from Teleoperation Data for Mobile Manipulation
Dec 09, 2021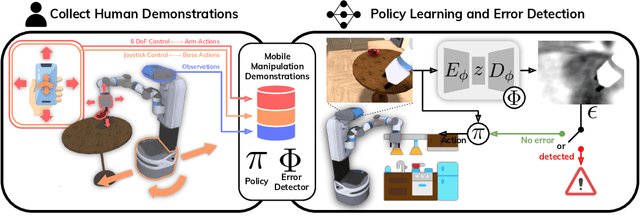
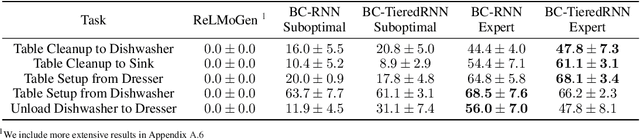

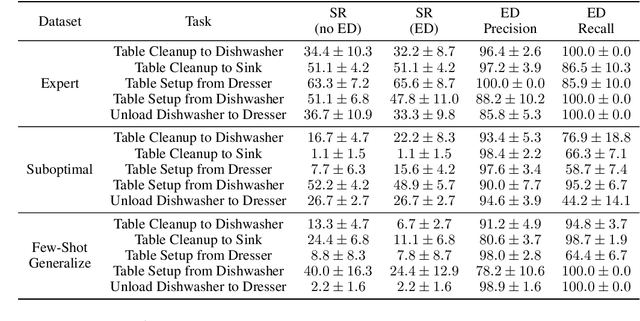
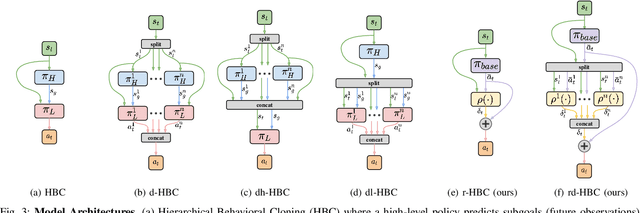
In mobile manipulation (MM), robots can both navigate within and interact with their environment and are thus able to complete many more tasks than robots only capable of navigation or manipulation. In this work, we explore how to apply imitation learning (IL) to learn continuous visuo-motor policies for MM tasks. Much prior work has shown that IL can train visuo-motor policies for either manipulation or navigation domains, but few works have applied IL to the MM domain. Doing this is challenging for two reasons: on the data side, current interfaces make collecting high-quality human demonstrations difficult, and on the learning side, policies trained on limited data can suffer from covariate shift when deployed. To address these problems, we first propose Mobile Manipulation RoboTurk (MoMaRT), a novel teleoperation framework allowing simultaneous navigation and manipulation of mobile manipulators, and collect a first-of-its-kind large scale dataset in a realistic simulated kitchen setting. We then propose a learned error detection system to address the covariate shift by detecting when an agent is in a potential failure state. We train performant IL policies and error detectors from this data, and achieve over 45% task success rate and 85% error detection success rate across multiple multi-stage tasks when trained on expert data. Codebase, datasets, visualization, and more available at https://sites.google.com/view/il-for-mm/home.
Hierarchical Summarization for Longform Spoken Dialog
Aug 21, 2021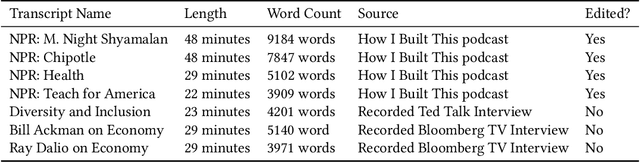


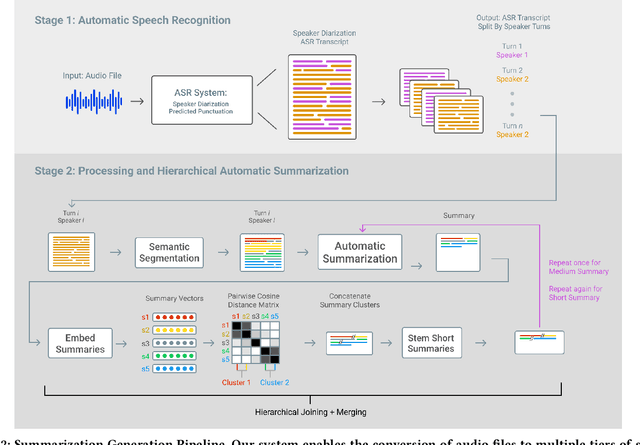
Every day we are surrounded by spoken dialog. This medium delivers rich diverse streams of information auditorily; however, systematically understanding dialog can often be non-trivial. Despite the pervasiveness of spoken dialog, automated speech understanding and quality information extraction remains markedly poor, especially when compared to written prose. Furthermore, compared to understanding text, auditory communication poses many additional challenges such as speaker disfluencies, informal prose styles, and lack of structure. These concerns all demonstrate the need for a distinctly speech tailored interactive system to help users understand and navigate the spoken language domain. While individual automatic speech recognition (ASR) and text summarization methods already exist, they are imperfect technologies; neither consider user purpose and intent nor address spoken language induced complications. Consequently, we design a two stage ASR and text summarization pipeline and propose a set of semantic segmentation and merging algorithms to resolve these speech modeling challenges. Our system enables users to easily browse and navigate content as well as recover from errors in these underlying technologies. Finally, we present an evaluation of the system which highlights user preference for hierarchical summarization as a tool to quickly skim audio and identify content of interest to the user.
Learning Multi-Arm Manipulation Through Collaborative Teleoperation
Dec 12, 2020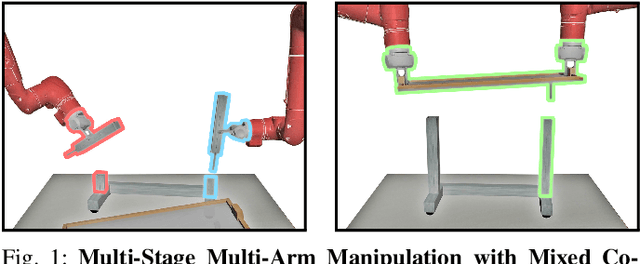
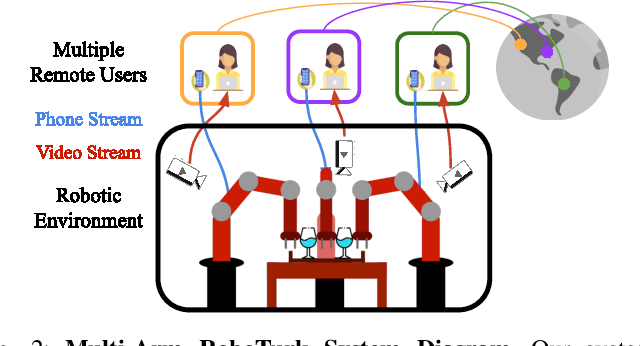

Imitation Learning (IL) is a powerful paradigm to teach robots to perform manipulation tasks by allowing them to learn from human demonstrations collected via teleoperation, but has mostly been limited to single-arm manipulation. However, many real-world tasks require multiple arms, such as lifting a heavy object or assembling a desk. Unfortunately, applying IL to multi-arm manipulation tasks has been challenging -- asking a human to control more than one robotic arm can impose significant cognitive burden and is often only possible for a maximum of two robot arms. To address these challenges, we present Multi-Arm RoboTurk (MART), a multi-user data collection platform that allows multiple remote users to simultaneously teleoperate a set of robotic arms and collect demonstrations for multi-arm tasks. Using MART, we collected demonstrations for five novel two and three-arm tasks from several geographically separated users. From our data we arrived at a critical insight: most multi-arm tasks do not require global coordination throughout its full duration, but only during specific moments. We show that learning from such data consequently presents challenges for centralized agents that directly attempt to model all robot actions simultaneously, and perform a comprehensive study of different policy architectures with varying levels of centralization on our tasks. Finally, we propose and evaluate a base-residual policy framework that allows trained policies to better adapt to the mixed coordination setting common in multi-arm manipulation, and show that a centralized policy augmented with a decentralized residual model outperforms all other models on our set of benchmark tasks. Additional results and videos at https://roboturk.stanford.edu/multiarm .
Scaling Robot Supervision to Hundreds of Hours with RoboTurk: Robotic Manipulation Dataset through Human Reasoning and Dexterity
Nov 11, 2019
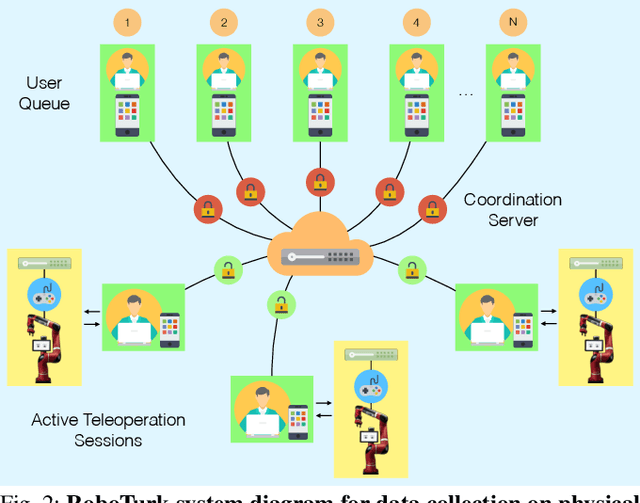

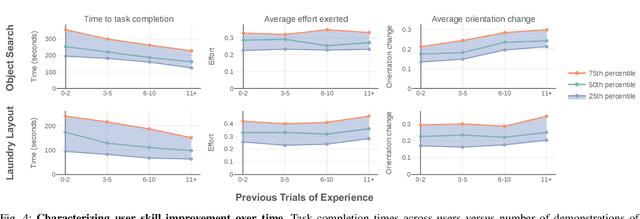
Large, richly annotated datasets have accelerated progress in fields such as computer vision and natural language processing, but replicating these successes in robotics has been challenging. While prior data collection methodologies such as self-supervision have resulted in large datasets, the data can have poor signal-to-noise ratio. By contrast, previous efforts to collect task demonstrations with humans provide better quality data, but they cannot reach the same data magnitude. Furthermore, neither approach places guarantees on the diversity of the data collected, in terms of solution strategies. In this work, we leverage and extend the RoboTurk platform to scale up data collection for robotic manipulation using remote teleoperation. The primary motivation for our platform is two-fold: (1) to address the shortcomings of prior work and increase the total quantity of manipulation data collected through human supervision by an order of magnitude without sacrificing the quality of the data and (2) to collect data on challenging manipulation tasks across several operators and observe a diverse set of emergent behaviors and solutions. We collected over 111 hours of robot manipulation data across 54 users and 3 challenging manipulation tasks in 1 week, resulting in the largest robot dataset collected via remote teleoperation. We evaluate the quality of our platform, the diversity of demonstrations in our dataset, and the utility of our dataset via quantitative and qualitative analysis. For additional results, supplementary videos, and to download our dataset, visit http://roboturk.stanford.edu/realrobotdataset .
RoboTurk: A Crowdsourcing Platform for Robotic Skill Learning through Imitation
Nov 07, 2018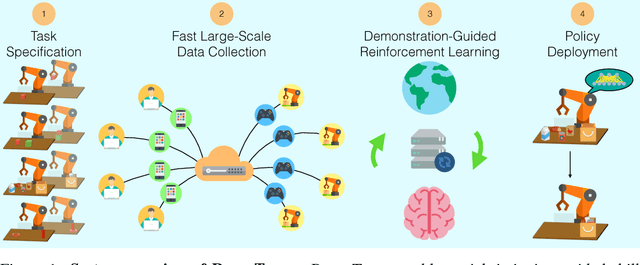

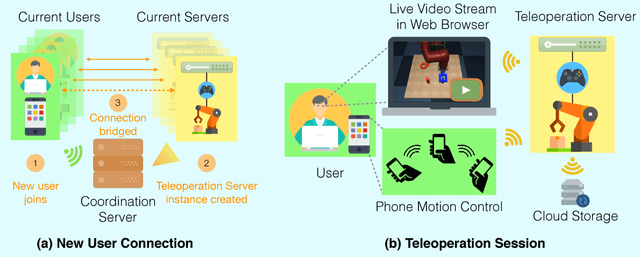
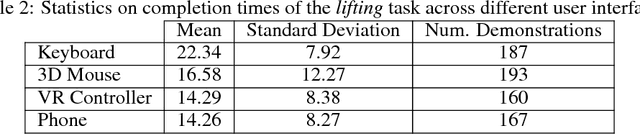
Imitation Learning has empowered recent advances in learning robotic manipulation tasks by addressing shortcomings of Reinforcement Learning such as exploration and reward specification. However, research in this area has been limited to modest-sized datasets due to the difficulty of collecting large quantities of task demonstrations through existing mechanisms. This work introduces RoboTurk to address this challenge. RoboTurk is a crowdsourcing platform for high quality 6-DoF trajectory based teleoperation through the use of widely available mobile devices (e.g. iPhone). We evaluate RoboTurk on three manipulation tasks of varying timescales (15-120s) and observe that our user interface is statistically similar to special purpose hardware such as virtual reality controllers in terms of task completion times. Furthermore, we observe that poor network conditions, such as low bandwidth and high delay links, do not substantially affect the remote users' ability to perform task demonstrations successfully on RoboTurk. Lastly, we demonstrate the efficacy of RoboTurk through the collection of a pilot dataset; using RoboTurk, we collected 137.5 hours of manipulation data from remote workers, amounting to over 2200 successful task demonstrations in 22 hours of total system usage. We show that the data obtained through RoboTurk enables policy learning on multi-step manipulation tasks with sparse rewards and that using larger quantities of demonstrations during policy learning provides benefits in terms of both learning consistency and final performance. For additional results, videos, and to download our pilot dataset, visit $\href{http://roboturk.stanford.edu/}{\texttt{roboturk.stanford.edu}}$