 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOPeRA: A Dataset of Observation, Persona, Rationale, and Action for Evaluating LLMs on Human Online Shopping Behavior Simulation
Jun 05, 2025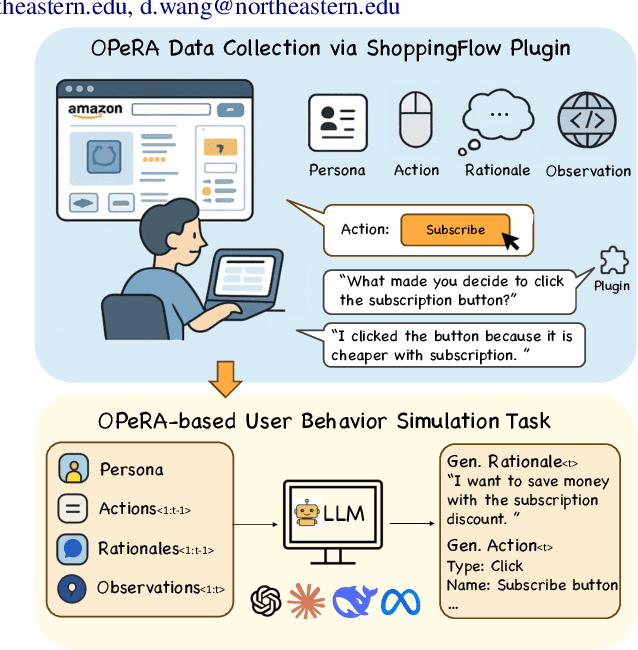
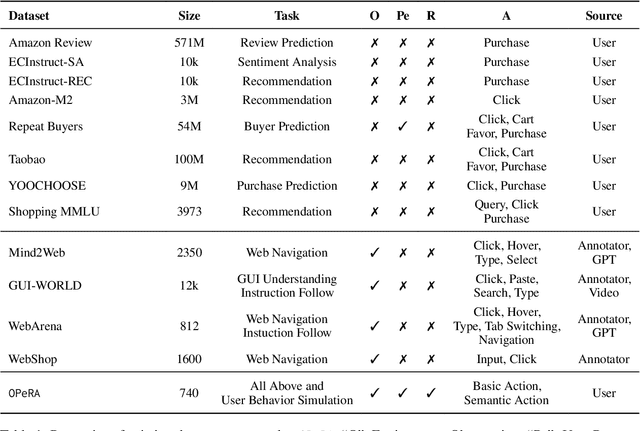
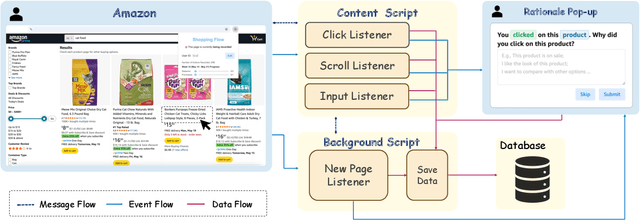
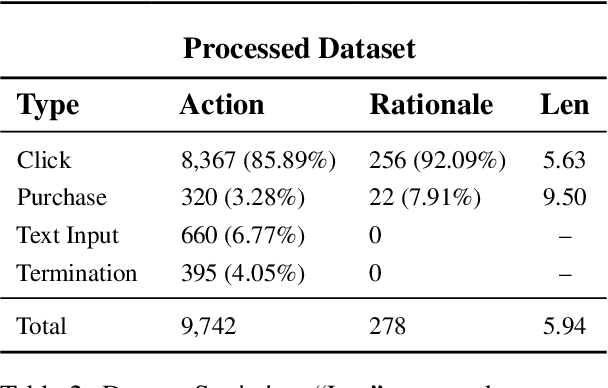
Can large language models (LLMs) accurately simulate the next web action of a specific user? While LLMs have shown promising capabilities in generating ``believable'' human behaviors, evaluating their ability to mimic real user behaviors remains an open challenge, largely due to the lack of high-quality, publicly available datasets that capture both the observable actions and the internal reasoning of an actual human user. To address this gap, we introduce OPERA, a novel dataset of Observation, Persona, Rationale, and Action collected from real human participants during online shopping sessions. OPERA is the first public dataset that comprehensively captures: user personas, browser observations, fine-grained web actions, and self-reported just-in-time rationales. We developed both an online questionnaire and a custom browser plugin to gather this dataset with high fidelity. Using OPERA, we establish the first benchmark to evaluate how well current LLMs can predict a specific user's next action and rationale with a given persona and <observation, action, rationale> history. This dataset lays the groundwork for future research into LLM agents that aim to act as personalized digital twins for human.
STORYWARS: A Dataset and Instruction Tuning Baselines for Collaborative Story Understanding and Generation
May 14, 2023Collaborative stories, which are texts created through the collaborative efforts of multiple authors with different writing styles and intentions, pose unique challenges for NLP models. Understanding and generating such stories remains an underexplored area due to the lack of open-domain corpora. To address this, we introduce STORYWARS, a new dataset of over 40,000 collaborative stories written by 9,400 different authors from an online platform. We design 12 task types, comprising 7 understanding and 5 generation task types, on STORYWARS, deriving 101 diverse story-related tasks in total as a multi-task benchmark covering all fully-supervised, few-shot, and zero-shot scenarios. Furthermore, we present our instruction-tuned model, INSTRUCTSTORY, for the story tasks showing that instruction tuning, in addition to achieving superior results in zero-shot and few-shot scenarios, can also obtain the best performance on the fully-supervised tasks in STORYWARS, establishing strong multi-task benchmark performances on STORYWARS.
Generative Disco: Text-to-Video Generation for Music Visualization
Apr 17, 2023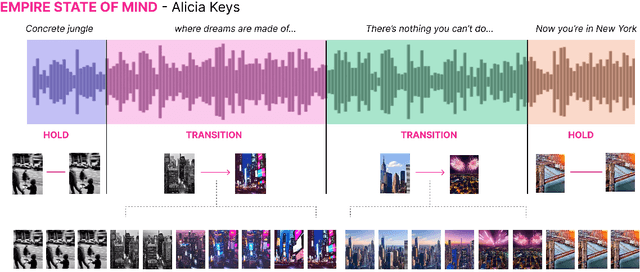
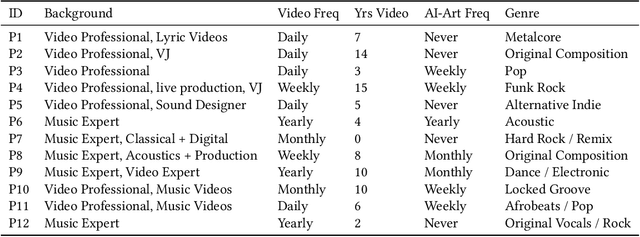

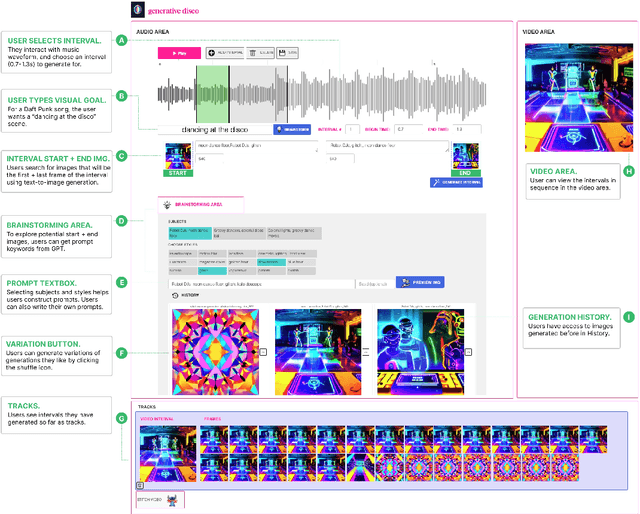
Visuals are a core part of our experience of music, owing to the way they can amplify the emotions and messages conveyed through the music. However, creating music visualization is a complex, time-consuming, and resource-intensive process. We introduce Generative Disco, a generative AI system that helps generate music visualizations with large language models and text-to-image models. Users select intervals of music to visualize and then parameterize that visualization by defining start and end prompts. These prompts are warped between and generated according to the beat of the music for audioreactive video. We introduce design patterns for improving generated videos: "transitions", which express shifts in color, time, subject, or style, and "holds", which encourage visual emphasis and consistency. A study with professionals showed that the system was enjoyable, easy to explore, and highly expressive. We conclude on use cases of Generative Disco for professionals and how AI-generated content is changing the landscape of creative work.
SafeText: A Benchmark for Exploring Physical Safety in Language Models
Oct 18, 2022



Understanding what constitutes safe text is an important issue in natural language processing and can often prevent the deployment of models deemed harmful and unsafe. One such type of safety that has been scarcely studied is commonsense physical safety, i.e. text that is not explicitly violent and requires additional commonsense knowledge to comprehend that it leads to physical harm. We create the first benchmark dataset, SafeText, comprising real-life scenarios with paired safe and physically unsafe pieces of advice. We utilize SafeText to empirically study commonsense physical safety across various models designed for text generation and commonsense reasoning tasks. We find that state-of-the-art large language models are susceptible to the generation of unsafe text and have difficulty rejecting unsafe advice. As a result, we argue for further studies of safety and the assessment of commonsense physical safety in models before release.
Lightweight Decoding Strategies for Increasing Specificity
Oct 22, 2021
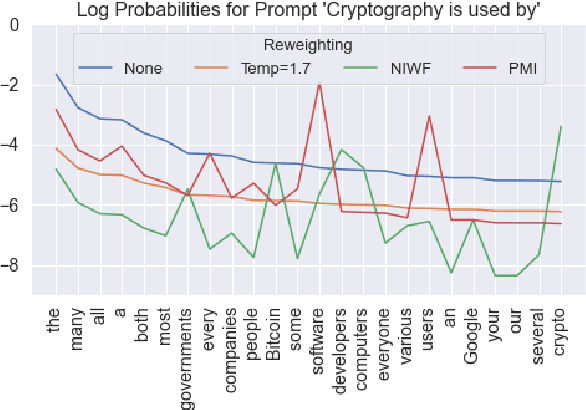

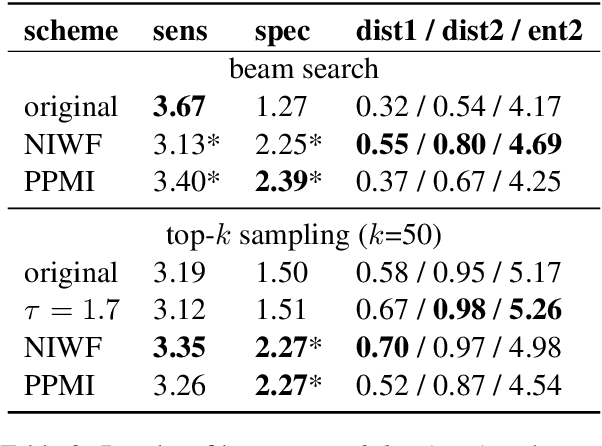
Language models are known to produce vague and generic outputs. We propose two unsupervised decoding strategies based on either word-frequency or point-wise mutual information to increase the specificity of any model that outputs a probability distribution over its vocabulary at generation time. We test the strategies in a prompt completion task; with human evaluations, we find that both strategies increase the specificity of outputs with only modest decreases in sensibility. We also briefly present a summarization use case, where these strategies can produce more specific summaries.
Hierarchical Summarization for Longform Spoken Dialog
Aug 21, 2021


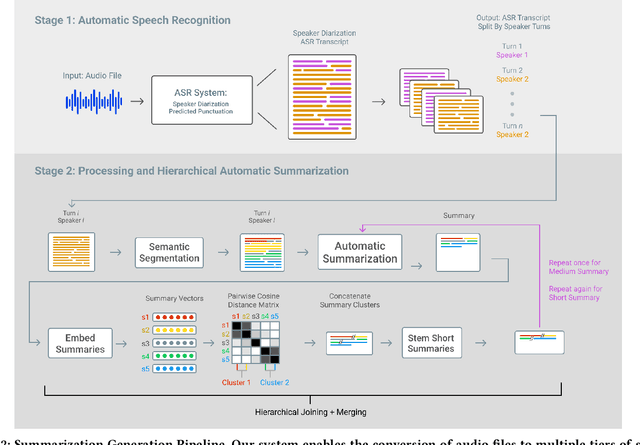
Every day we are surrounded by spoken dialog. This medium delivers rich diverse streams of information auditorily; however, systematically understanding dialog can often be non-trivial. Despite the pervasiveness of spoken dialog, automated speech understanding and quality information extraction remains markedly poor, especially when compared to written prose. Furthermore, compared to understanding text, auditory communication poses many additional challenges such as speaker disfluencies, informal prose styles, and lack of structure. These concerns all demonstrate the need for a distinctly speech tailored interactive system to help users understand and navigate the spoken language domain. While individual automatic speech recognition (ASR) and text summarization methods already exist, they are imperfect technologies; neither consider user purpose and intent nor address spoken language induced complications. Consequently, we design a two stage ASR and text summarization pipeline and propose a set of semantic segmentation and merging algorithms to resolve these speech modeling challenges. Our system enables users to easily browse and navigate content as well as recover from errors in these underlying technologies. Finally, we present an evaluation of the system which highlights user preference for hierarchical summarization as a tool to quickly skim audio and identify content of interest to the user.
Low-Level Linguistic Controls for Style Transfer and Content Preservation
Nov 08, 2019
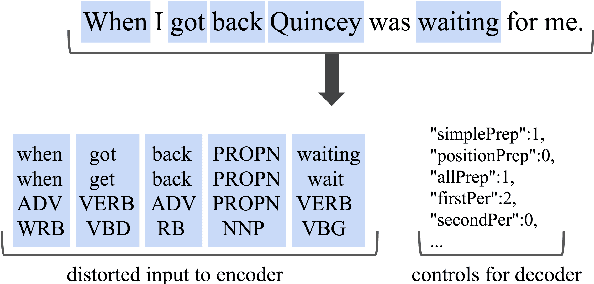
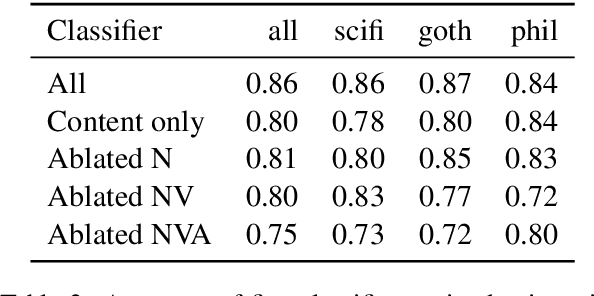
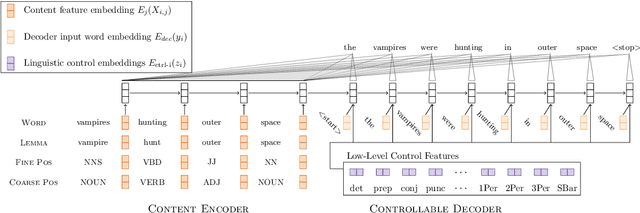
Despite the success of style transfer in image processing, it has seen limited progress in natural language generation. Part of the problem is that content is not as easily decoupled from style in the text domain. Curiously, in the field of stylometry, content does not figure prominently in practical methods of discriminating stylistic elements, such as authorship and genre. Rather, syntax and function words are the most salient features. Drawing on this work, we model style as a suite of low-level linguistic controls, such as frequency of pronouns, prepositions, and subordinate clause constructions. We train a neural encoder-decoder model to reconstruct reference sentences given only content words and the setting of the controls. We perform style transfer by keeping the content words fixed while adjusting the controls to be indicative of another style. In experiments, we show that the model reliably responds to the linguistic controls and perform both automatic and manual evaluations on style transfer. We find we can fool a style classifier 84% of the time, and that our model produces highly diverse and stylistically distinctive outputs. This work introduces a formal, extendable model of style that can add control to any neural text generation system.