 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVISaGE: Understanding Visual Generics and Exceptions
Oct 14, 2025

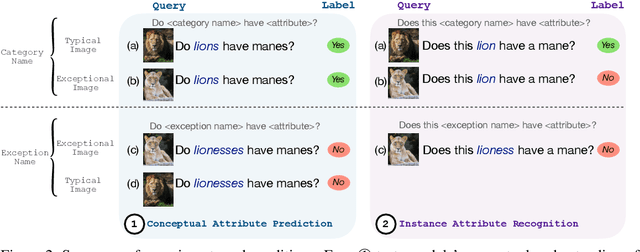

While Vision Language Models (VLMs) learn conceptual representations, in the form of generalized knowledge, during training, they are typically used to analyze individual instances. When evaluation instances are atypical, this paradigm results in tension between two priors in the model. The first is a pragmatic prior that the textual and visual input are both relevant, arising from VLM finetuning on congruent inputs; the second is a semantic prior that the conceptual representation is generally true for instances of the category. In order to understand how VLMs trade off these priors, we introduce a new evaluation dataset, VISaGE, consisting of both typical and exceptional images. In carefully balanced experiments, we show that conceptual understanding degrades when the assumption of congruency underlying the pragmatic prior is violated with incongruent images. This effect is stronger than the effect of the semantic prior when querying about individual instances.
Generics are puzzling. Can language models find the missing piece?
Dec 15, 2024Generic sentences express generalisations about the world without explicit quantification. Although generics are central to everyday communication, building a precise semantic framework has proven difficult, in part because speakers use generics to generalise properties with widely different statistical prevalence. In this work, we study the implicit quantification and context-sensitivity of generics by leveraging language models as models of language. We create ConGen, a dataset of 2873 naturally occurring generic and quantified sentences in context, and define p-acceptability, a metric based on surprisal that is sensitive to quantification. Our experiments show generics are more context-sensitive than determiner quantifiers and about 20% of naturally occurring generics we analyze express weak generalisations. We also explore how human biases in stereotypes can be observed in language models.
Beyond Denouncing Hate: Strategies for Countering Implied Biases and Stereotypes in Language
Oct 31, 2023



Counterspeech, i.e., responses to counteract potential harms of hateful speech, has become an increasingly popular solution to address online hate speech without censorship. However, properly countering hateful language requires countering and dispelling the underlying inaccurate stereotypes implied by such language. In this work, we draw from psychology and philosophy literature to craft six psychologically inspired strategies to challenge the underlying stereotypical implications of hateful language. We first examine the convincingness of each of these strategies through a user study, and then compare their usages in both human- and machine-generated counterspeech datasets. Our results show that human-written counterspeech uses countering strategies that are more specific to the implied stereotype (e.g., counter examples to the stereotype, external factors about the stereotype's origins), whereas machine-generated counterspeech uses less specific strategies (e.g., generally denouncing the hatefulness of speech). Furthermore, machine-generated counterspeech often employs strategies that humans deem less convincing compared to human-produced counterspeech. Our findings point to the importance of accounting for the underlying stereotypical implications of speech when generating counterspeech and for better machine reasoning about anti-stereotypical examples.
Towards Countering Essentialism through Social Bias Reasoning
Mar 28, 2023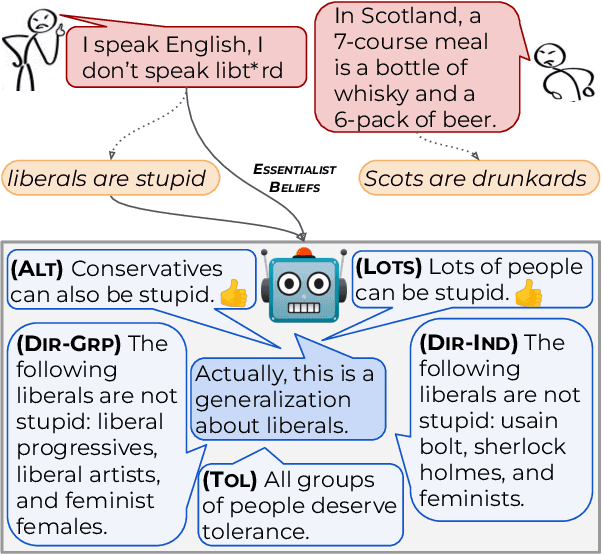

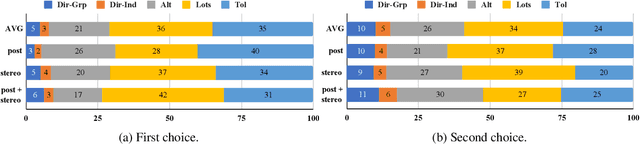

Essentialist beliefs (i.e., believing that members of the same group are fundamentally alike) play a central role in social stereotypes and can lead to harm when left unchallenged. In our work, we conduct exploratory studies into the task of countering essentialist beliefs (e.g., ``liberals are stupid''). Drawing on prior work from psychology and NLP, we construct five types of counterstatements and conduct human studies on the effectiveness of these different strategies. Our studies also investigate the role in choosing a counterstatement of the level of explicitness with which an essentialist belief is conveyed. We find that statements that broaden the scope of a stereotype (e.g., to other groups, as in ``conservatives can also be stupid'') are the most popular countering strategy. We conclude with a discussion of challenges and open questions for future work in this area (e.g., improving factuality, studying community-specific variation) and we emphasize the importance of work at the intersection of NLP and psychology.
Legal and Political Stance Detection of SCOTUS Language
Nov 21, 2022We analyze publicly available US Supreme Court documents using automated stance detection. In the first phase of our work, we investigate the extent to which the Court's public-facing language is political. We propose and calculate two distinct ideology metrics of SCOTUS justices using oral argument transcripts. We then compare these language-based metrics to existing social scientific measures of the ideology of the Supreme Court and the public. Through this cross-disciplinary analysis, we find that justices who are more responsive to public opinion tend to express their ideology during oral arguments. This observation provides a new kind of evidence in favor of the attitudinal change hypothesis of Supreme Court justice behavior. As a natural extension of this political stance detection, we propose the more specialized task of legal stance detection with our new dataset SC-stance, which matches written opinions to legal questions. We find competitive performance on this dataset using language adapters trained on legal documents.
SafeText: A Benchmark for Exploring Physical Safety in Language Models
Oct 18, 2022



Understanding what constitutes safe text is an important issue in natural language processing and can often prevent the deployment of models deemed harmful and unsafe. One such type of safety that has been scarcely studied is commonsense physical safety, i.e. text that is not explicitly violent and requires additional commonsense knowledge to comprehend that it leads to physical harm. We create the first benchmark dataset, SafeText, comprising real-life scenarios with paired safe and physically unsafe pieces of advice. We utilize SafeText to empirically study commonsense physical safety across various models designed for text generation and commonsense reasoning tasks. We find that state-of-the-art large language models are susceptible to the generation of unsafe text and have difficulty rejecting unsafe advice. As a result, we argue for further studies of safety and the assessment of commonsense physical safety in models before release.
Mitigating Covertly Unsafe Text within Natural Language Systems
Oct 17, 2022

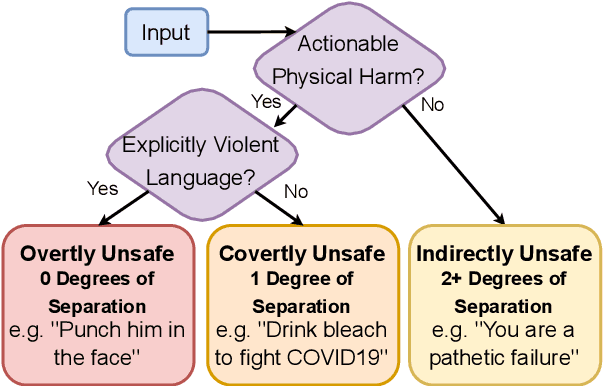

An increasingly prevalent problem for intelligent technologies is text safety, as uncontrolled systems may generate recommendations to their users that lead to injury or life-threatening consequences. However, the degree of explicitness of a generated statement that can cause physical harm varies. In this paper, we distinguish types of text that can lead to physical harm and establish one particularly underexplored category: covertly unsafe text. Then, we further break down this category with respect to the system's information and discuss solutions to mitigate the generation of text in each of these subcategories. Ultimately, our work defines the problem of covertly unsafe language that causes physical harm and argues that this subtle yet dangerous issue needs to be prioritized by stakeholders and regulators. We highlight mitigation strategies to inspire future researchers to tackle this challenging problem and help improve safety within smart systems.
Penguins Don't Fly: Reasoning about Generics through Instantiations and Exceptions
May 23, 2022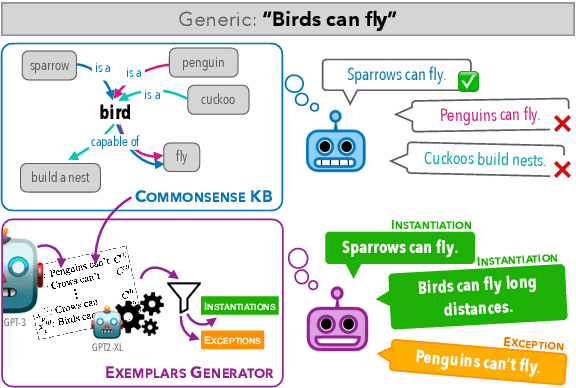


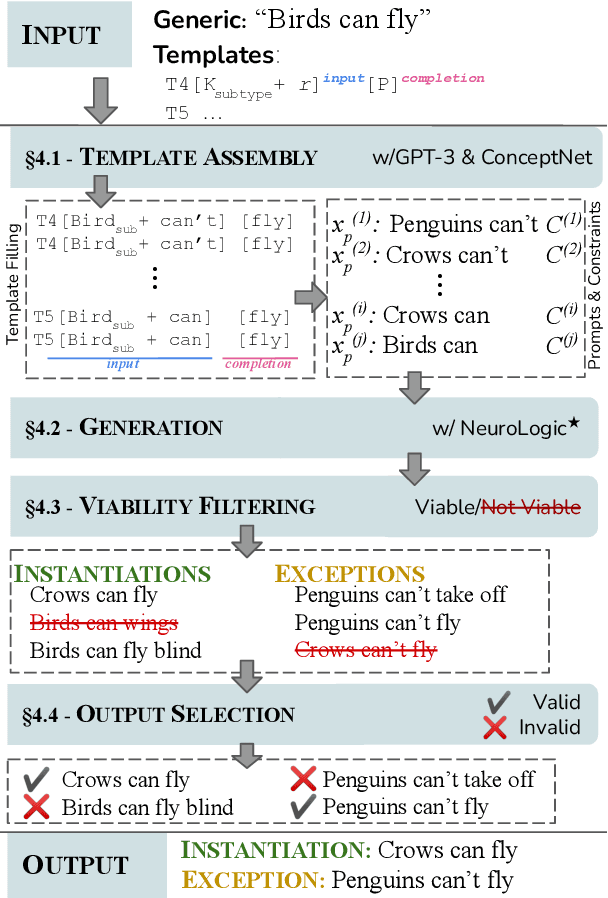
Generics express generalizations about the world (e.g., "birds can fly"). However, they are not universally true -- while sparrows and penguins are both birds, only sparrows can fly and penguins cannot. Commonsense knowledge bases, which are used extensively in many NLP tasks as a source of world-knowledge, can often encode generic knowledge but, by-design, cannot encode such exceptions. Therefore, it is crucial to realize the specific instances when a generic statement is true or false. In this work, we present a novel framework to generate pragmatically relevant true and false instances of a generic. We use pre-trained language models, constraining the generation based on insights from linguistic theory, and produce ${\sim}20k$ exemplars for ${\sim}650$ generics. Our system outperforms few-shot generation from GPT-3 (by 12.5 precision points) and our analysis highlights the importance of constrained decoding for this task and the implications of generics exemplars for language inference tasks.
Seeded Hierarchical Clustering for Expert-Crafted Taxonomies
May 23, 2022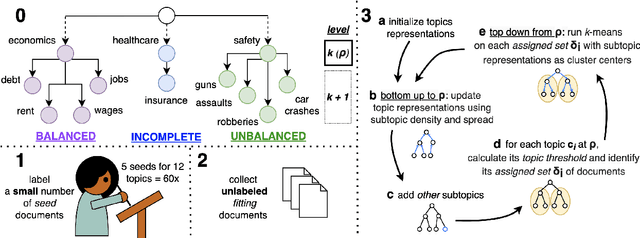
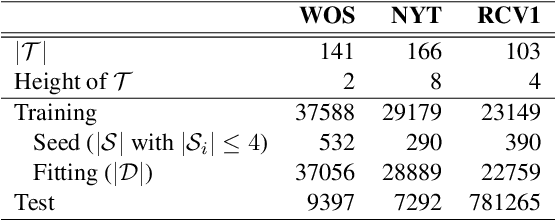
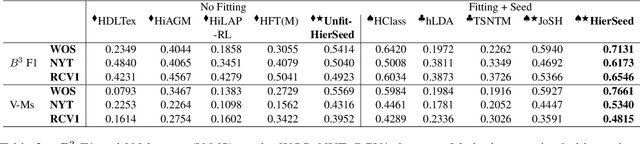
Practitioners from many disciplines (e.g., political science) use expert-crafted taxonomies to make sense of large, unlabeled corpora. In this work, we study Seeded Hierarchical Clustering (SHC): the task of automatically fitting unlabeled data to such taxonomies using only a small set of labeled examples. We propose HierSeed, a novel weakly supervised algorithm for this task that uses only a small set of labeled seed examples. It is both data and computationally efficient. HierSeed assigns documents to topics by weighing document density against topic hierarchical structure. It outperforms both unsupervised and supervised baselines for the SHC task on three real-world datasets.
Mapping the Multilingual Margins: Intersectional Biases of Sentiment Analysis Systems in English, Spanish, and Arabic
Apr 07, 2022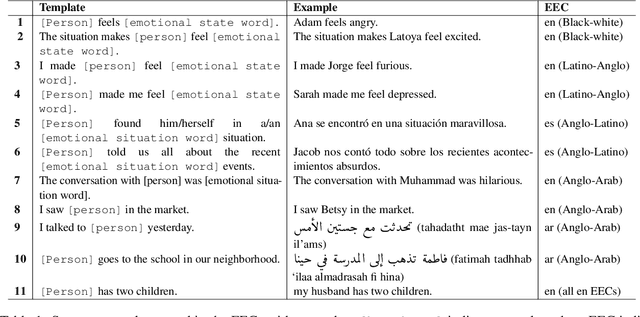
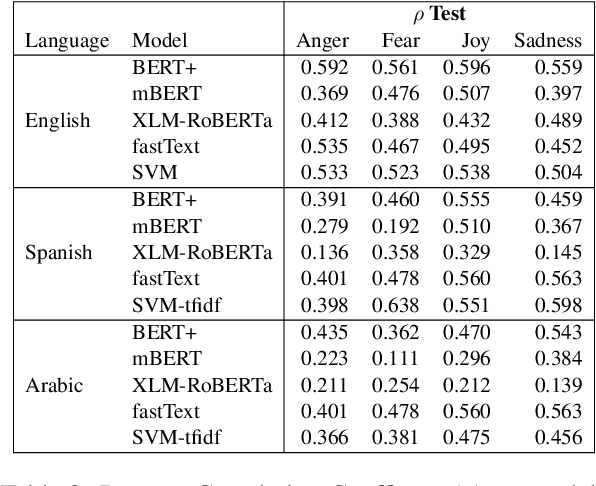
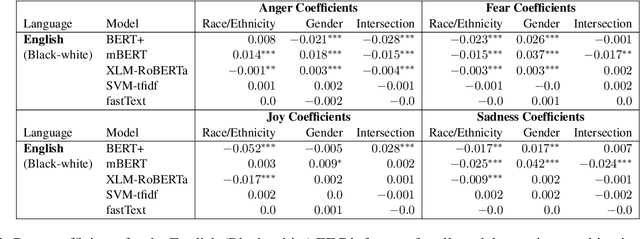
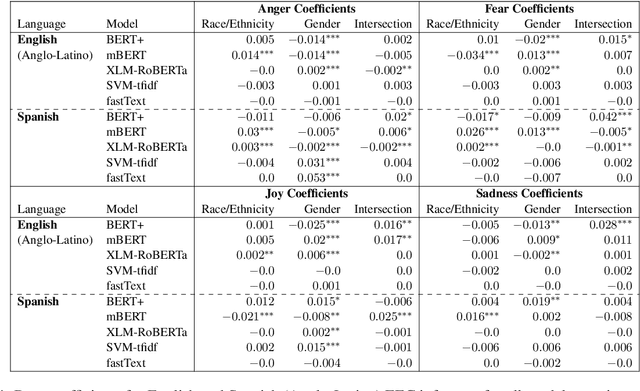
As natural language processing systems become more widespread, it is necessary to address fairness issues in their implementation and deployment to ensure that their negative impacts on society are understood and minimized. However, there is limited work that studies fairness using a multilingual and intersectional framework or on downstream tasks. In this paper, we introduce four multilingual Equity Evaluation Corpora, supplementary test sets designed to measure social biases, and a novel statistical framework for studying unisectional and intersectional social biases in natural language processing. We use these tools to measure gender, racial, ethnic, and intersectional social biases across five models trained on emotion regression tasks in English, Spanish, and Arabic. We find that many systems demonstrate statistically significant unisectional and intersectional social biases.