 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMapping the Multilingual Margins: Intersectional Biases of Sentiment Analysis Systems in English, Spanish, and Arabic
Apr 07, 2022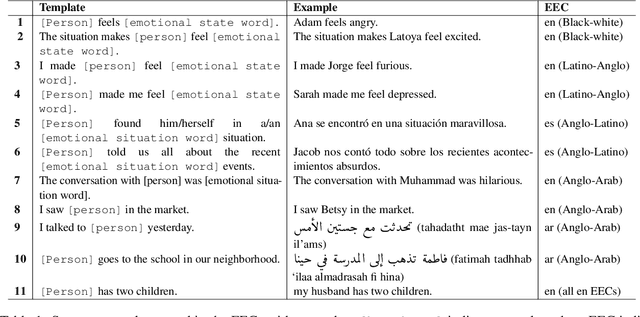
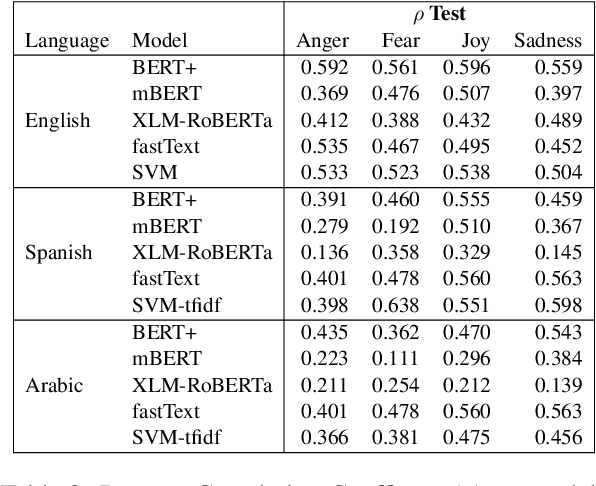
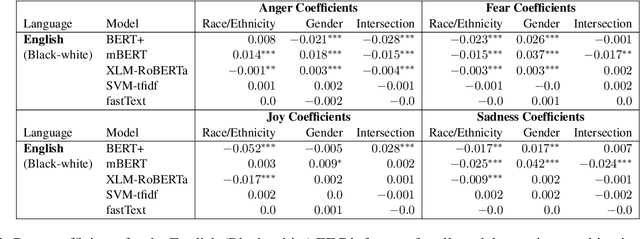
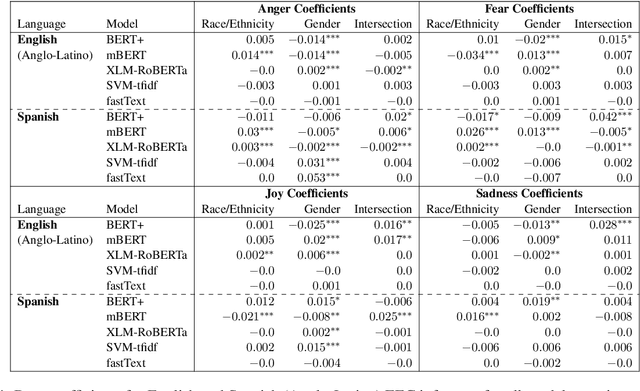
As natural language processing systems become more widespread, it is necessary to address fairness issues in their implementation and deployment to ensure that their negative impacts on society are understood and minimized. However, there is limited work that studies fairness using a multilingual and intersectional framework or on downstream tasks. In this paper, we introduce four multilingual Equity Evaluation Corpora, supplementary test sets designed to measure social biases, and a novel statistical framework for studying unisectional and intersectional social biases in natural language processing. We use these tools to measure gender, racial, ethnic, and intersectional social biases across five models trained on emotion regression tasks in English, Spanish, and Arabic. We find that many systems demonstrate statistically significant unisectional and intersectional social biases.