 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLevel Up: Defining and Exploiting Transitional Problems for Curriculum Learning
Mar 14, 2026Curriculum learning--ordering training examples in a sequence to aid machine learning--takes inspiration from human learning, but has not gained widespread acceptance. Static strategies for scoring item difficulty rely on indirect proxy scores of varying quality and produce curricula that are not specific to the learner at hand. Dynamic approaches base difficulty estimates on gradient information, requiring considerable extra computation during training. We introduce a novel method for measuring the difficulty of individual problem instances directly relative to the ability of a given model, and identify transitional problems that are consistently easier as model ability increases. Applying this method to chess and mathematics, we find that training on a curriculum that "levels up" from easier to harder transitional problems most efficiently improves a model to the next tier of competence. These problems induce a natural progression from easier to harder items, which outperforms other training strategies. By measuring difficulty directly relative to model competence, our method yields interpretable problems, learner-specific curricula, and a principled basis for step-by-step improvement.
Tell Me What To Learn: Generalizing Neural Memory to be Controllable in Natural Language
Feb 26, 2026Modern machine learning models are deployed in diverse, non-stationary environments where they must continually adapt to new tasks and evolving knowledge. Continual fine-tuning and in-context learning are costly and brittle, whereas neural memory methods promise lightweight updates with minimal forgetting. However, existing neural memory models typically assume a single fixed objective and homogeneous information streams, leaving users with no control over what the model remembers or ignores over time. To address this challenge, we propose a generalized neural memory system that performs flexible updates based on learning instructions specified in natural language. Our approach enables adaptive agents to learn selectively from heterogeneous information sources, supporting settings, such as healthcare and customer service, where fixed-objective memory updates are insufficient.
Whom to Query for What: Adaptive Group Elicitation via Multi-Turn LLM Interactions
Feb 15, 2026Eliciting information to reduce uncertainty about latent group-level properties from surveys and other collective assessments requires allocating limited questioning effort under real costs and missing data. Although large language models enable adaptive, multi-turn interactions in natural language, most existing elicitation methods optimize what to ask with a fixed respondent pool, and do not adapt respondent selection or leverage population structure when responses are partial or incomplete. To address this gap, we study adaptive group elicitation, a multi-round setting where an agent adaptively selects both questions and respondents under explicit query and participation budgets. We propose a theoretically grounded framework that combines (i) an LLM-based expected information gain objective for scoring candidate questions with (ii) heterogeneous graph neural network propagation that aggregates observed responses and participant attributes to impute missing responses and guide per-round respondent selection. This closed-loop procedure queries a small, informative subset of individuals while inferring population-level responses via structured similarity. Across three real-world opinion datasets, our method consistently improves population-level response prediction under constrained budgets, including a >12% relative gain on CES at a 10% respondent budget.
Few-Shot Design Optimization by Exploiting Auxiliary Information
Feb 12, 2026Many real-world design problems involve optimizing an expensive black-box function $f(x)$, such as hardware design or drug discovery. Bayesian Optimization has emerged as a sample-efficient framework for this problem. However, the basic setting considered by these methods is simplified compared to real-world experimental setups, where experiments often generate a wealth of useful information. We introduce a new setting where an experiment generates high-dimensional auxiliary information $h(x)$ along with the performance measure $f(x)$; moreover, a history of previously solved tasks from the same task family is available for accelerating optimization. A key challenge of our setting is learning how to represent and utilize $h(x)$ for efficiently solving new optimization tasks beyond the task history. We develop a novel approach for this setting based on a neural model which predicts $f(x)$ for unseen designs given a few-shot context containing observations of $h(x)$. We evaluate our method on two challenging domains, robotic hardware design and neural network hyperparameter tuning, and introduce a novel design problem and large-scale benchmark for the former. On both domains, our method utilizes auxiliary feedback effectively to achieve more accurate few-shot prediction and faster optimization of design tasks, significantly outperforming several methods for multi-task optimization.
Let the Experts Speak: Improving Survival Prediction & Calibration via Mixture-of-Experts Heads
Nov 11, 2025Deep mixture-of-experts models have attracted a lot of attention for survival analysis problems, particularly for their ability to cluster similar patients together. In practice, grouping often comes at the expense of key metrics such calibration error and predictive accuracy. This is due to the restrictive inductive bias that mixture-of-experts imposes, that predictions for individual patients must look like predictions for the group they're assigned to. Might we be able to discover patient group structure, where it exists, while improving calibration and predictive accuracy? In this work, we introduce several discrete-time deep mixture-of-experts (MoE) based architectures for survival analysis problems, one of which achieves all desiderata: clustering, calibration, and predictive accuracy. We show that a key differentiator between this array of MoEs is how expressive their experts are. We find that more expressive experts that tailor predictions per patient outperform experts that rely on fixed group prototypes.
Confidence Calibration in Vision-Language-Action Models
Jul 23, 2025Trustworthy robot behavior requires not only high levels of task success but also that the robot can reliably quantify how likely it is to succeed. To this end, we present the first systematic study of confidence calibration in vision-language-action (VLA) foundation models, which map visual observations and natural-language instructions to low-level robot motor commands. We begin with extensive benchmarking to understand the critical relationship between task success and calibration error across multiple datasets and VLA variants, finding that task performance and calibration are not in tension. Next, we introduce prompt ensembles for VLAs, a lightweight, Bayesian-inspired algorithm that averages confidence across paraphrased instructions and consistently improves calibration. We further analyze calibration over the task time horizon, showing that confidence is often most reliable after making some progress, suggesting natural points for risk-aware intervention. Finally, we reveal differential miscalibration across action dimensions and propose action-wise Platt scaling, a method to recalibrate each action dimension independently to produce better confidence estimates. Our aim in this study is to begin to develop the tools and conceptual understanding necessary to render VLAs both highly performant and highly trustworthy via reliable uncertainty quantification.
Guiding LLM Decision-Making with Fairness Reward Models
Jul 15, 2025



Large language models are increasingly used to support high-stakes decisions, potentially influencing who is granted bail or receives a loan. Naive chain-of-thought sampling can improve average decision accuracy, but has also been shown to amplify unfair bias. To address this challenge and enable the trustworthy use of reasoning models in high-stakes decision-making, we propose a framework for training a generalizable Fairness Reward Model (FRM). Our model assigns a fairness score to LLM reasoning, enabling the system to down-weight biased trajectories and favor equitable ones when aggregating decisions across reasoning chains. We show that a single Fairness Reward Model, trained on weakly supervised, LLM-annotated examples of biased versus unbiased reasoning, transfers across tasks, domains, and model families without additional fine-tuning. Applied to real-world decision-making tasks including recidivism prediction and social media moderation, we show that our approach consistently improves fairness while matching, or even surpassing, baseline accuracy.
Replay Can Provably Increase Forgetting
Jun 04, 2025Continual learning seeks to enable machine learning systems to solve an increasing corpus of tasks sequentially. A critical challenge for continual learning is forgetting, where the performance on previously learned tasks decreases as new tasks are introduced. One of the commonly used techniques to mitigate forgetting, sample replay, has been shown empirically to reduce forgetting by retaining some examples from old tasks and including them in new training episodes. In this work, we provide a theoretical analysis of sample replay in an over-parameterized continual linear regression setting, where each task is given by a linear subspace and with enough replay samples, one would be able to eliminate forgetting. Our analysis focuses on sample replay and highlights the role of the replayed samples and the relationship between task subspaces. Surprisingly, we find that, even in a noiseless setting, forgetting can be non-monotonic with respect to the number of replay samples. We present tasks where replay can be harmful with respect to worst-case settings, and also in distributional settings where replay of randomly selected samples increases forgetting in expectation. We also give empirical evidence that harmful replay is not limited to training with linear models by showing similar behavior for a neural networks equipped with SGD. Through experiments on a commonly used benchmark, we provide additional evidence that, even in seemingly benign scenarios, performance of the replay heavily depends on the choice of replay samples and the relationship between tasks.
Towards Safety Reasoning in LLMs: AI-agentic Deliberation for Policy-embedded CoT Data Creation
May 27, 2025Safety reasoning is a recent paradigm where LLMs reason over safety policies before generating responses, thereby mitigating limitations in existing safety measures such as over-refusal and jailbreak vulnerabilities. However, implementing this paradigm is challenging due to the resource-intensive process of creating high-quality policy-embedded chain-of-thought (CoT) datasets while ensuring reasoning remains accurate and free from hallucinations or policy conflicts. To tackle this, we propose AIDSAFE: Agentic Iterative Deliberation for Safety Reasoning, a novel data generation recipe that leverages multi-agent deliberation to iteratively expand reasoning on safety policies. A data refiner stage in AIDSAFE ensures high-quality outputs by eliminating repetitive, redundant, and deceptive thoughts. AIDSAFE-generated CoTs provide a strong foundation for supervised fine-tuning (SFT)-based safety training. Additionally, to address the need of preference data in alignment stages, such as DPO training, we introduce a supplemental recipe that uses belief augmentation to create distinct selected and rejected CoT samples. Our evaluations demonstrate that AIDSAFE-generated CoTs achieve superior policy adherence and reasoning quality. Consequently, we show that fine-tuning open-source LLMs on these CoTs can significantly improve safety generalization and jailbreak robustness while maintaining acceptable utility and over-refusal accuracy. AIDSAFE-generated CoT datasets can be found here: https://huggingface.co/datasets/AmazonScience/AIDSAFE
Adaptive Elicitation of Latent Information Using Natural Language
Apr 05, 2025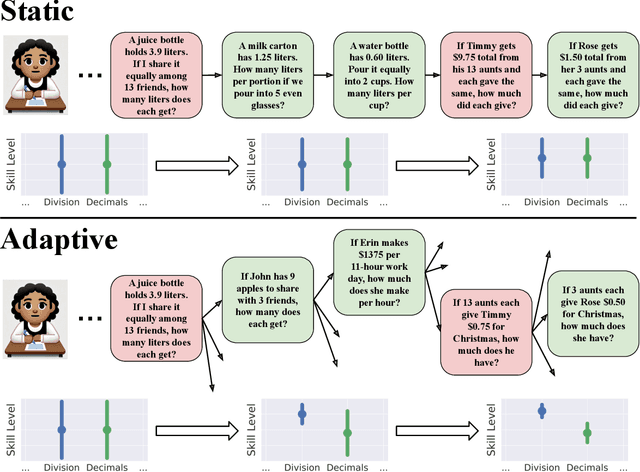

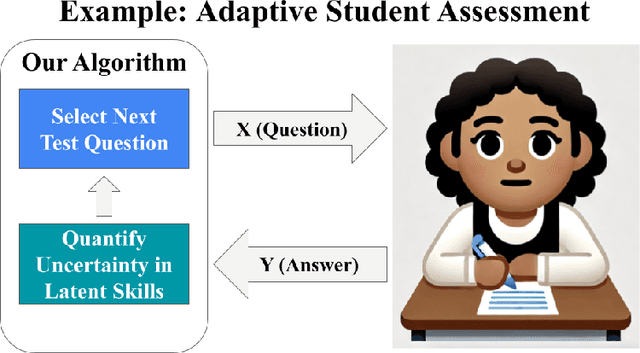

Eliciting information to reduce uncertainty about a latent entity is a critical task in many application domains, e.g., assessing individual student learning outcomes, diagnosing underlying diseases, or learning user preferences. Though natural language is a powerful medium for this purpose, large language models (LLMs) and existing fine-tuning algorithms lack mechanisms for strategically gathering information to refine their own understanding of the latent entity. To harness the generalization power and world knowledge of LLMs in developing effective information-gathering strategies, we propose an adaptive elicitation framework that actively reduces uncertainty on the latent entity. Since probabilistic modeling of an abstract latent entity is difficult, our framework adopts a predictive view of uncertainty, using a meta-learned language model to simulate future observations and enable scalable uncertainty quantification over complex natural language. Through autoregressive forward simulation, our model quantifies how new questions reduce epistemic uncertainty, enabling the development of sophisticated information-gathering strategies to choose the most informative next queries. In experiments on the 20 questions game, dynamic opinion polling, and adaptive student assessment, our method consistently outperforms baselines in identifying critical unknowns and improving downstream predictions, illustrating the promise of strategic information gathering in natural language settings.