 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhiteboard-of-Thought: Thinking Step-by-Step Across Modalities
Paper and Code
Jun 20, 2024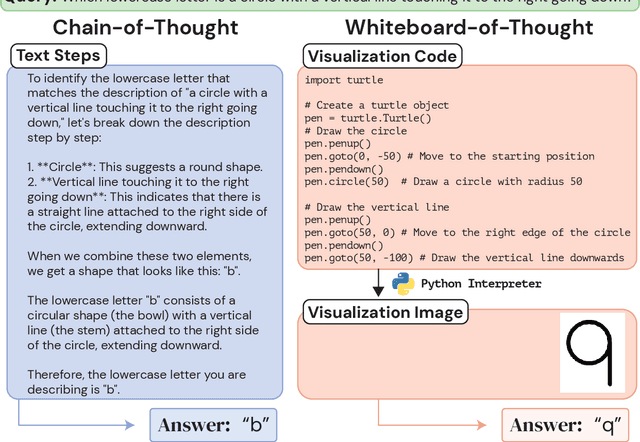
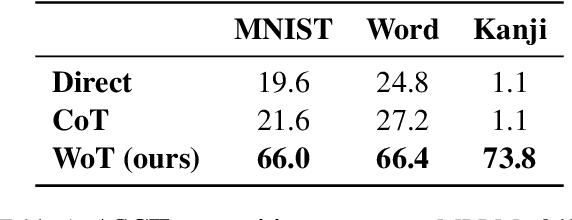

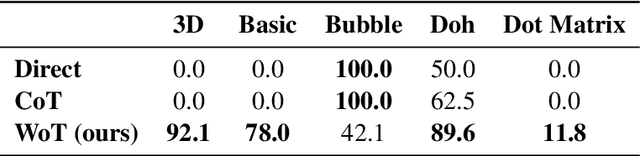
When presented with questions involving visual thinking, humans naturally switch reasoning modalities, often forming mental images or drawing visual aids. Large language models have shown promising results in arithmetic and symbolic reasoning by expressing intermediate reasoning in text as a chain of thought, yet struggle to extend this capability to answer text queries that are easily solved by visual reasoning, even with extensive multimodal pretraining. We introduce a simple method, whiteboard-of-thought prompting, to unlock the visual reasoning capabilities of multimodal large language models across modalities. Whiteboard-of-thought prompting provides multimodal large language models with a metaphorical `whiteboard' to draw out reasoning steps as images, then returns these images back to the model for further processing. We find this can be accomplished with no demonstrations or specialized modules, instead leveraging models' existing ability to write code with libraries such as Matplotlib and Turtle. This simple approach shows state-of-the-art results on four difficult natural language tasks that involve visual and spatial reasoning. We identify multiple settings where GPT-4o using chain-of-thought fails dramatically, including more than one where it achieves $0\%$ accuracy, while whiteboard-of-thought enables up to $92\%$ accuracy in these same settings. We present a detailed exploration of where the technique succeeds as well as its sources of error.