 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge4D Gaussian Splatting as a Learned Dynamical System
Dec 22, 2025We reinterpret 4D Gaussian Splatting as a continuous-time dynamical system, where scene motion arises from integrating a learned neural dynamical field rather than applying per-frame deformations. This formulation, which we call EvoGS, treats the Gaussian representation as an evolving physical system whose state evolves continuously under a learned motion law. This unlocks capabilities absent in deformation-based approaches:(1) sample-efficient learning from sparse temporal supervision by modeling the underlying motion law; (2) temporal extrapolation enabling forward and backward prediction beyond observed time ranges; and (3) compositional dynamics that allow localized dynamics injection for controllable scene synthesis. Experiments on dynamic scene benchmarks show that EvoGS achieves better motion coherence and temporal consistency compared to deformation-field baselines while maintaining real-time rendering
CAViAR: Critic-Augmented Video Agentic Reasoning
Sep 09, 2025Video understanding has seen significant progress in recent years, with models' performance on perception from short clips continuing to rise. Yet, multiple recent benchmarks, such as LVBench, Neptune, and ActivityNet-RTL, show performance wanes for tasks requiring complex reasoning on videos as queries grow more complex and videos grow longer. In this work, we ask: can existing perception capabilities be leveraged to successfully perform more complex video reasoning? In particular, we develop a large language model agent given access to video modules as subagents or tools. Rather than following a fixed procedure to solve queries as in previous work such as Visual Programming, ViperGPT, and MoReVQA, the agent uses the results of each call to a module to determine subsequent steps. Inspired by work in the textual reasoning domain, we introduce a critic to distinguish between instances of successful and unsuccessful sequences from the agent. We show that the combination of our agent and critic achieve strong performance on the previously-mentioned datasets.
Video Generators are Robot Policies
Aug 01, 2025Despite tremendous progress in dexterous manipulation, current visuomotor policies remain fundamentally limited by two challenges: they struggle to generalize under perceptual or behavioral distribution shifts, and their performance is constrained by the size of human demonstration data. In this paper, we use video generation as a proxy for robot policy learning to address both limitations simultaneously. We propose Video Policy, a modular framework that combines video and action generation that can be trained end-to-end. Our results demonstrate that learning to generate videos of robot behavior allows for the extraction of policies with minimal demonstration data, significantly improving robustness and sample efficiency. Our method shows strong generalization to unseen objects, backgrounds, and tasks, both in simulation and the real world. We further highlight that task success is closely tied to the generated video, with action-free video data providing critical benefits for generalizing to novel tasks. By leveraging large-scale video generative models, we achieve superior performance compared to traditional behavior cloning, paving the way for more scalable and data-efficient robot policy learning.
MINERVA: Evaluating Complex Video Reasoning
May 01, 2025Multimodal LLMs are turning their focus to video benchmarks, however most video benchmarks only provide outcome supervision, with no intermediate or interpretable reasoning steps. This makes it challenging to assess if models are truly able to combine perceptual and temporal information to reason about videos, or simply get the correct answer by chance or by exploiting linguistic biases. To remedy this, we provide a new video reasoning dataset called MINERVA for modern multimodal models. Each question in the dataset comes with 5 answer choices, as well as detailed, hand-crafted reasoning traces. Our dataset is multimodal, diverse in terms of video domain and length, and consists of complex multi-step questions. Extensive benchmarking shows that our dataset provides a challenge for frontier open-source and proprietary models. We perform fine-grained error analysis to identify common failure modes across various models, and create a taxonomy of reasoning errors. We use this to explore both human and LLM-as-a-judge methods for scoring video reasoning traces, and find that failure modes are primarily related to temporal localization, followed by visual perception errors, as opposed to logical or completeness errors. The dataset, along with questions, answer candidates and reasoning traces will be publicly available under https://github.com/google-deepmind/neptune?tab=readme-ov-file\#minerva.
Towards LLM Agents for Earth Observation
Apr 16, 2025Earth Observation (EO) provides critical planetary data for environmental monitoring, disaster management, climate science, and other scientific domains. Here we ask: Are AI systems ready for reliable Earth Observation? We introduce \datasetnamenospace, a benchmark of 140 yes/no questions from NASA Earth Observatory articles across 13 topics and 17 satellite sensors. Using Google Earth Engine API as a tool, LLM agents can only achieve an accuracy of 33% because the code fails to run over 58% of the time. We improve the failure rate for open models by fine-tuning synthetic data, allowing much smaller models (Llama-3.1-8B) to achieve comparable accuracy to much larger ones (e.g., DeepSeek-R1). Taken together, our findings identify significant challenges to be solved before AI agents can automate earth observation, and suggest paths forward. The project page is available at https://iandrover.github.io/UnivEarth.
Can LLM feedback enhance review quality? A randomized study of 20K reviews at ICLR 2025
Apr 13, 2025Peer review at AI conferences is stressed by rapidly rising submission volumes, leading to deteriorating review quality and increased author dissatisfaction. To address these issues, we developed Review Feedback Agent, a system leveraging multiple large language models (LLMs) to improve review clarity and actionability by providing automated feedback on vague comments, content misunderstandings, and unprofessional remarks to reviewers. Implemented at ICLR 2025 as a large randomized control study, our system provided optional feedback to more than 20,000 randomly selected reviews. To ensure high-quality feedback for reviewers at this scale, we also developed a suite of automated reliability tests powered by LLMs that acted as guardrails to ensure feedback quality, with feedback only being sent to reviewers if it passed all the tests. The results show that 27% of reviewers who received feedback updated their reviews, and over 12,000 feedback suggestions from the agent were incorporated by those reviewers. This suggests that many reviewers found the AI-generated feedback sufficiently helpful to merit updating their reviews. Incorporating AI feedback led to significantly longer reviews (an average increase of 80 words among those who updated after receiving feedback) and more informative reviews, as evaluated by blinded researchers. Moreover, reviewers who were selected to receive AI feedback were also more engaged during paper rebuttals, as seen in longer author-reviewer discussions. This work demonstrates that carefully designed LLM-generated review feedback can enhance peer review quality by making reviews more specific and actionable while increasing engagement between reviewers and authors. The Review Feedback Agent is publicly available at https://github.com/zou-group/review_feedback_agent.
Teaching Humans Subtle Differences with DIFFusion
Apr 10, 2025
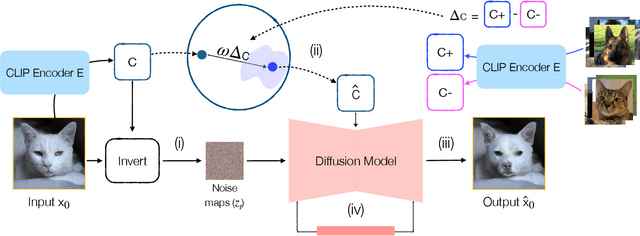


Human expertise depends on the ability to recognize subtle visual differences, such as distinguishing diseases, species, or celestial phenomena. We propose a new method to teach novices how to differentiate between nuanced categories in specialized domains. Our method uses generative models to visualize the minimal change in features to transition between classes, i.e., counterfactuals, and performs well even in domains where data is sparse, examples are unpaired, and category boundaries are not easily explained by text. By manipulating the conditioning space of diffusion models, our proposed method DIFFusion disentangles category structure from instance identity, enabling high-fidelity synthesis even in challenging domains. Experiments across six domains show accurate transitions even with limited and unpaired examples across categories. User studies confirm that our generated counterfactuals outperform unpaired examples in teaching perceptual expertise, showing the potential of generative models for specialized visual learning.
Generative Data Mining with Longtail-Guided Diffusion
Feb 04, 2025
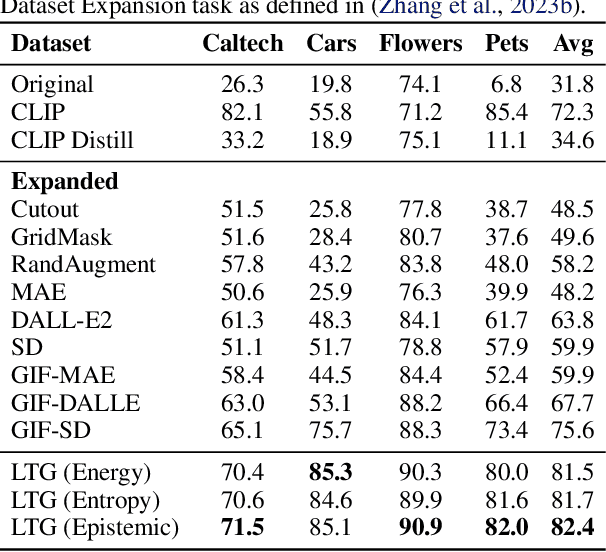
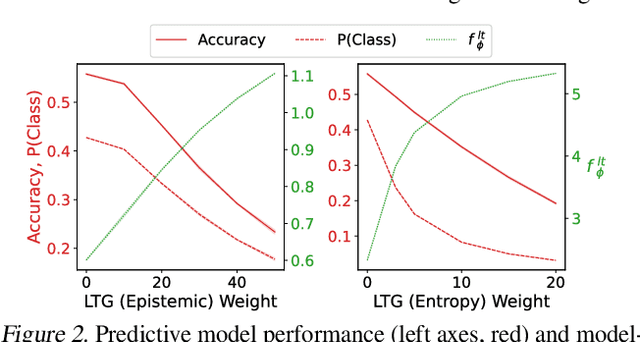
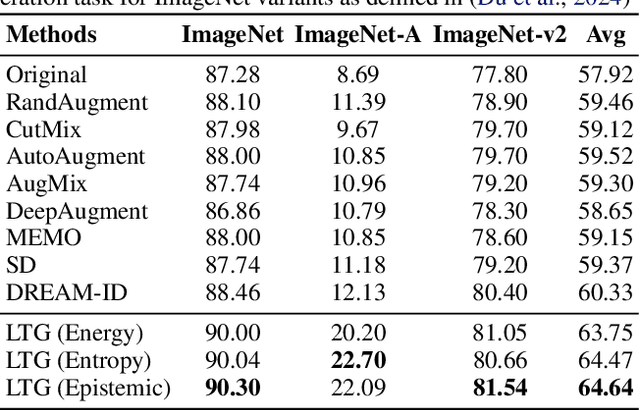
It is difficult to anticipate the myriad challenges that a predictive model will encounter once deployed. Common practice entails a reactive, cyclical approach: model deployment, data mining, and retraining. We instead develop a proactive longtail discovery process by imagining additional data during training. In particular, we develop general model-based longtail signals, including a differentiable, single forward pass formulation of epistemic uncertainty that does not impact model parameters or predictive performance but can flag rare or hard inputs. We leverage these signals as guidance to generate additional training data from a latent diffusion model in a process we call Longtail Guidance (LTG). Crucially, we can perform LTG without retraining the diffusion model or the predictive model, and we do not need to expose the predictive model to intermediate diffusion states. Data generated by LTG exhibit semantically meaningful variation, yield significant generalization improvements on image classification benchmarks, and can be analyzed to proactively discover, explain, and address conceptual gaps in a predictive model.
MedAutoCorrect: Image-Conditioned Autocorrection in Medical Reporting
Dec 04, 2024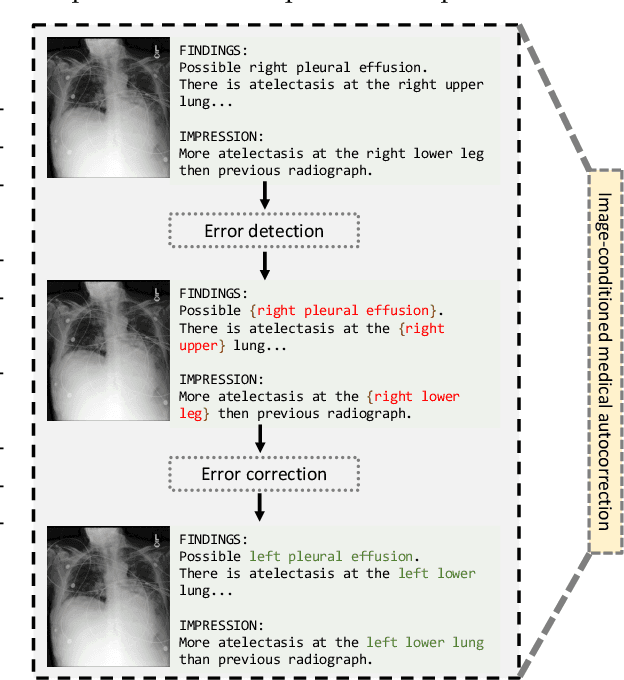
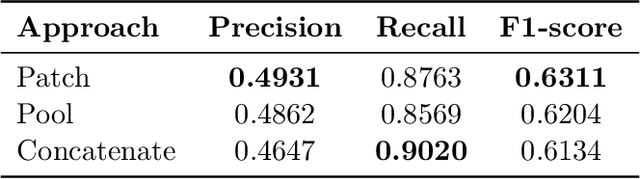
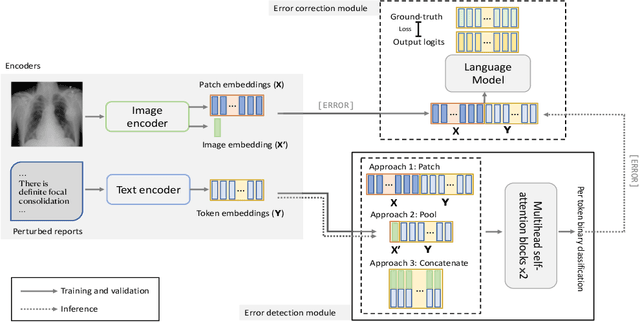

In medical reporting, the accuracy of radiological reports, whether generated by humans or machine learning algorithms, is critical. We tackle a new task in this paper: image-conditioned autocorrection of inaccuracies within these reports. Using the MIMIC-CXR dataset, we first intentionally introduce a diverse range of errors into reports. Subsequently, we propose a two-stage framework capable of pinpointing these errors and then making corrections, simulating an \textit{autocorrection} process. This method aims to address the shortcomings of existing automated medical reporting systems, like factual errors and incorrect conclusions, enhancing report reliability in vital healthcare applications. Importantly, our approach could serve as a guardrail, ensuring the accuracy and trustworthiness of automated report generation. Experiments on established datasets and state of the art report generation models validate this method's potential in correcting medical reporting errors.
Self-Improving Autonomous Underwater Manipulation
Oct 24, 2024

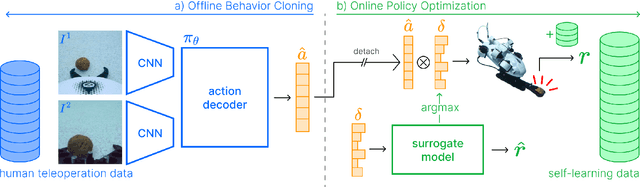
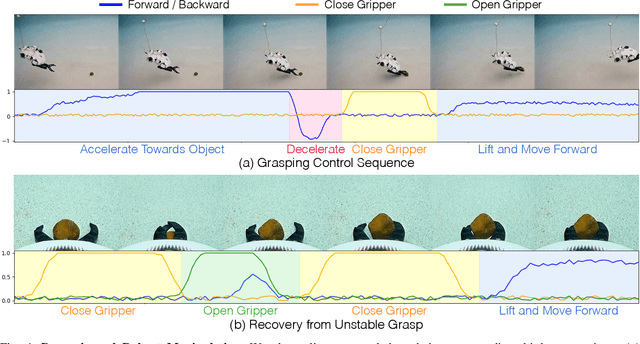
Underwater robotic manipulation faces significant challenges due to complex fluid dynamics and unstructured environments, causing most manipulation systems to rely heavily on human teleoperation. In this paper, we introduce AquaBot, a fully autonomous manipulation system that combines behavior cloning from human demonstrations with self-learning optimization to improve beyond human teleoperation performance. With extensive real-world experiments, we demonstrate AquaBot's versatility across diverse manipulation tasks, including object grasping, trash sorting, and rescue retrieval. Our real-world experiments show that AquaBot's self-optimized policy outperforms a human operator by 41% in speed. AquaBot represents a promising step towards autonomous and self-improving underwater manipulation systems. We open-source both hardware and software implementation details.