 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRoboDream: Compositional World Models for Scalable Robot Data Synthesis
Jun 01, 2026Scaling robot learning requires large-scale, diverse demonstrations, yet real-world data collection via teleoperation remains prohibitively expensive and time-consuming. While video diffusion models offer a promising avenue for data scaling, existing generative approaches are often limited to superficial visual augmentation, or suffer from embodiment hallucinations that yield physically infeasible motions. We present a generalizable embodiment-centric world model that achieves scalable data generation by synthesizing photorealistic demonstrations with novel objects, in novel scenes, and from novel viewpoints. Our approach anchors generation to rendered robot motion while conditioning on explicit scene and object priors, effectively decoupling trajectory execution from environment synthesis. This formulation has the potential to unlock two powerful data scaling capabilities: (1) retrieval and rebirth, which repurposes existing trajectories into entirely new contexts without new motion data; and (2) prop-free teleoperation, where operators manipulate empty air and the model hallucinates the target objects and scene afterwards, eliminating reset time. We demonstrate with real-world experiments that our generated data consistently improves downstream policy performance and significantly reduces real-world data requirements across diverse manipulation tasks.
Capturing Visual Environment Structure Correlates with Control Performance
Feb 04, 2026The choice of visual representation is key to scaling generalist robot policies. However, direct evaluation via policy rollouts is expensive, even in simulation. Existing proxy metrics focus on the representation's capacity to capture narrow aspects of the visual world, like object shape, limiting generalization across environments. In this paper, we take an analytical perspective: we probe pretrained visual encoders by measuring how well they support decoding of environment state -- including geometry, object structure, and physical attributes -- from images. Leveraging simulation environments with access to ground-truth state, we show that this probing accuracy strongly correlates with downstream policy performance across diverse environments and learning settings, significantly outperforming prior metrics and enabling efficient representation selection. More broadly, our study provides insight into the representational properties that support generalizable manipulation, suggesting that learning to encode the latent physical state of the environment is a promising objective for control.
AnyView: Synthesizing Any Novel View in Dynamic Scenes
Jan 23, 2026Modern generative video models excel at producing convincing, high-quality outputs, but struggle to maintain multi-view and spatiotemporal consistency in highly dynamic real-world environments. In this work, we introduce \textbf{AnyView}, a diffusion-based video generation framework for \emph{dynamic view synthesis} with minimal inductive biases or geometric assumptions. We leverage multiple data sources with various levels of supervision, including monocular (2D), multi-view static (3D) and multi-view dynamic (4D) datasets, to train a generalist spatiotemporal implicit representation capable of producing zero-shot novel videos from arbitrary camera locations and trajectories. We evaluate AnyView on standard benchmarks, showing competitive results with the current state of the art, and propose \textbf{AnyViewBench}, a challenging new benchmark tailored towards \emph{extreme} dynamic view synthesis in diverse real-world scenarios. In this more dramatic setting, we find that most baselines drastically degrade in performance, as they require significant overlap between viewpoints, while AnyView maintains the ability to produce realistic, plausible, and spatiotemporally consistent videos when prompted from \emph{any} viewpoint. Results, data, code, and models can be viewed at: https://tri-ml.github.io/AnyView/
Walk through Paintings: Egocentric World Models from Internet Priors
Jan 21, 2026What if a video generation model could not only imagine a plausible future, but the correct one, accurately reflecting how the world changes with each action? We address this question by presenting the Egocentric World Model (EgoWM), a simple, architecture-agnostic method that transforms any pretrained video diffusion model into an action-conditioned world model, enabling controllable future prediction. Rather than training from scratch, we repurpose the rich world priors of Internet-scale video models and inject motor commands through lightweight conditioning layers. This allows the model to follow actions faithfully while preserving realism and strong generalization. Our approach scales naturally across embodiments and action spaces, ranging from 3-DoF mobile robots to 25-DoF humanoids, where predicting egocentric joint-angle-driven dynamics is substantially more challenging. The model produces coherent rollouts for both navigation and manipulation tasks, requiring only modest fine-tuning. To evaluate physical correctness independently of visual appearance, we introduce the Structural Consistency Score (SCS), which measures whether stable scene elements evolve consistently with the provided actions. EgoWM improves SCS by up to 80 percent over prior state-of-the-art navigation world models, while achieving up to six times lower inference latency and robust generalization to unseen environments, including navigation inside paintings.
AnchorDream: Repurposing Video Diffusion for Embodiment-Aware Robot Data Synthesis
Dec 12, 2025The collection of large-scale and diverse robot demonstrations remains a major bottleneck for imitation learning, as real-world data acquisition is costly and simulators offer limited diversity and fidelity with pronounced sim-to-real gaps. While generative models present an attractive solution, existing methods often alter only visual appearances without creating new behaviors, or suffer from embodiment inconsistencies that yield implausible motions. To address these limitations, we introduce AnchorDream, an embodiment-aware world model that repurposes pretrained video diffusion models for robot data synthesis. AnchorDream conditions the diffusion process on robot motion renderings, anchoring the embodiment to prevent hallucination while synthesizing objects and environments consistent with the robot's kinematics. Starting from only a handful of human teleoperation demonstrations, our method scales them into large, diverse, high-quality datasets without requiring explicit environment modeling. Experiments show that the generated data leads to consistent improvements in downstream policy learning, with relative gains of 36.4% in simulator benchmarks and nearly double performance in real-world studies. These results suggest that grounding generative world models in robot motion provides a practical path toward scaling imitation learning.
Video Generators are Robot Policies
Aug 01, 2025Despite tremendous progress in dexterous manipulation, current visuomotor policies remain fundamentally limited by two challenges: they struggle to generalize under perceptual or behavioral distribution shifts, and their performance is constrained by the size of human demonstration data. In this paper, we use video generation as a proxy for robot policy learning to address both limitations simultaneously. We propose Video Policy, a modular framework that combines video and action generation that can be trained end-to-end. Our results demonstrate that learning to generate videos of robot behavior allows for the extraction of policies with minimal demonstration data, significantly improving robustness and sample efficiency. Our method shows strong generalization to unseen objects, backgrounds, and tasks, both in simulation and the real world. We further highlight that task success is closely tied to the generated video, with action-free video data providing critical benefits for generalizing to novel tasks. By leveraging large-scale video generative models, we achieve superior performance compared to traditional behavior cloning, paving the way for more scalable and data-efficient robot policy learning.
Generative 4D Scene Gaussian Splatting with Object View-Synthesis Priors
Jun 15, 2025We tackle the challenge of generating dynamic 4D scenes from monocular, multi-object videos with heavy occlusions, and introduce GenMOJO, a novel approach that integrates rendering-based deformable 3D Gaussian optimization with generative priors for view synthesis. While existing models perform well on novel view synthesis for isolated objects, they struggle to generalize to complex, cluttered scenes. To address this, GenMOJO decomposes the scene into individual objects, optimizing a differentiable set of deformable Gaussians per object. This object-wise decomposition allows leveraging object-centric diffusion models to infer unobserved regions in novel viewpoints. It performs joint Gaussian splatting to render the full scene, capturing cross-object occlusions, and enabling occlusion-aware supervision. To bridge the gap between object-centric priors and the global frame-centric coordinate system of videos, GenMOJO uses differentiable transformations that align generative and rendering constraints within a unified framework. The resulting model generates 4D object reconstructions over space and time, and produces accurate 2D and 3D point tracks from monocular input. Quantitative evaluations and perceptual human studies confirm that GenMOJO generates more realistic novel views of scenes and produces more accurate point tracks compared to existing approaches.
AllTracker: Efficient Dense Point Tracking at High Resolution
Jun 08, 2025We introduce AllTracker: a model that estimates long-range point tracks by way of estimating the flow field between a query frame and every other frame of a video. Unlike existing point tracking methods, our approach delivers high-resolution and dense (all-pixel) correspondence fields, which can be visualized as flow maps. Unlike existing optical flow methods, our approach corresponds one frame to hundreds of subsequent frames, rather than just the next frame. We develop a new architecture for this task, blending techniques from existing work in optical flow and point tracking: the model performs iterative inference on low-resolution grids of correspondence estimates, propagating information spatially via 2D convolution layers, and propagating information temporally via pixel-aligned attention layers. The model is fast and parameter-efficient (16 million parameters), and delivers state-of-the-art point tracking accuracy at high resolution (i.e., tracking 768x1024 pixels, on a 40G GPU). A benefit of our design is that we can train on a wider set of datasets, and we find that doing so is crucial for top performance. We provide an extensive ablation study on our architecture details and training recipe, making it clear which details matter most. Our code and model weights are available at https://alltracker.github.io .
Understanding Complexity in VideoQA via Visual Program Generation
May 19, 2025We propose a data-driven approach to analyzing query complexity in Video Question Answering (VideoQA). Previous efforts in benchmark design have relied on human expertise to design challenging questions, yet we experimentally show that humans struggle to predict which questions are difficult for machine learning models. Our automatic approach leverages recent advances in code generation for visual question answering, using the complexity of generated code as a proxy for question difficulty. We demonstrate that this measure correlates significantly better with model performance than human estimates. To operationalize this insight, we propose an algorithm for estimating question complexity from code. It identifies fine-grained primitives that correlate with the hardest questions for any given set of models, making it easy to scale to new approaches in the future. Finally, to further illustrate the utility of our method, we extend it to automatically generate complex questions, constructing a new benchmark that is 1.9 times harder than the popular NExT-QA.
ReferEverything: Towards Segmenting Everything We Can Speak of in Videos
Oct 30, 2024


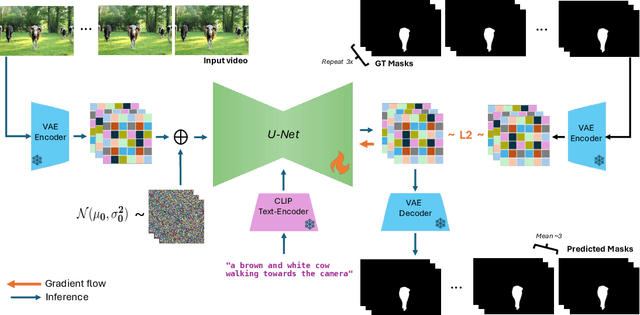
We present REM, a framework for segmenting a wide range of concepts in video that can be described through natural language. Our method capitalizes on visual-language representations learned by video diffusion models on Internet-scale datasets. A key insight of our approach is preserving as much of the generative model's original representation as possible, while fine-tuning it on narrow-domain Referral Object Segmentation datasets. As a result, our framework can accurately segment and track rare and unseen objects, despite being trained on object masks from a limited set of categories. Additionally, it can generalize to non-object dynamic concepts, such as waves crashing in the ocean, as demonstrated in our newly introduced benchmark for Referral Video Process Segmentation (Ref-VPS). Our experiments show that REM performs on par with state-of-the-art approaches on in-domain datasets, like Ref-DAVIS, while outperforming them by up to twelve points in terms of region similarity on out-of-domain data, leveraging the power of Internet-scale pre-training.