 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWalk through Paintings: Egocentric World Models from Internet Priors
Jan 21, 2026What if a video generation model could not only imagine a plausible future, but the correct one, accurately reflecting how the world changes with each action? We address this question by presenting the Egocentric World Model (EgoWM), a simple, architecture-agnostic method that transforms any pretrained video diffusion model into an action-conditioned world model, enabling controllable future prediction. Rather than training from scratch, we repurpose the rich world priors of Internet-scale video models and inject motor commands through lightweight conditioning layers. This allows the model to follow actions faithfully while preserving realism and strong generalization. Our approach scales naturally across embodiments and action spaces, ranging from 3-DoF mobile robots to 25-DoF humanoids, where predicting egocentric joint-angle-driven dynamics is substantially more challenging. The model produces coherent rollouts for both navigation and manipulation tasks, requiring only modest fine-tuning. To evaluate physical correctness independently of visual appearance, we introduce the Structural Consistency Score (SCS), which measures whether stable scene elements evolve consistently with the provided actions. EgoWM improves SCS by up to 80 percent over prior state-of-the-art navigation world models, while achieving up to six times lower inference latency and robust generalization to unseen environments, including navigation inside paintings.
ReferEverything: Towards Segmenting Everything We Can Speak of in Videos
Oct 30, 2024


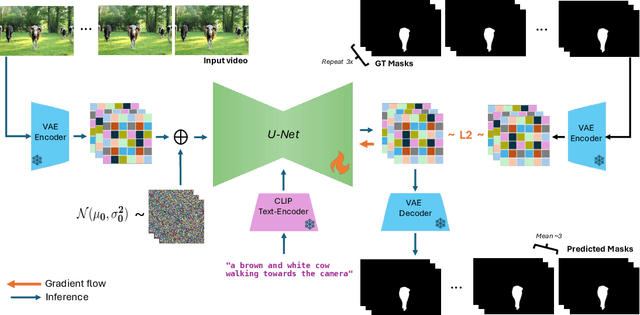
We present REM, a framework for segmenting a wide range of concepts in video that can be described through natural language. Our method capitalizes on visual-language representations learned by video diffusion models on Internet-scale datasets. A key insight of our approach is preserving as much of the generative model's original representation as possible, while fine-tuning it on narrow-domain Referral Object Segmentation datasets. As a result, our framework can accurately segment and track rare and unseen objects, despite being trained on object masks from a limited set of categories. Additionally, it can generalize to non-object dynamic concepts, such as waves crashing in the ocean, as demonstrated in our newly introduced benchmark for Referral Video Process Segmentation (Ref-VPS). Our experiments show that REM performs on par with state-of-the-art approaches on in-domain datasets, like Ref-DAVIS, while outperforming them by up to twelve points in terms of region similarity on out-of-domain data, leveraging the power of Internet-scale pre-training.
Hear Me Out: Fusional Approaches for Audio Augmented Temporal Action Localization
Jul 06, 2021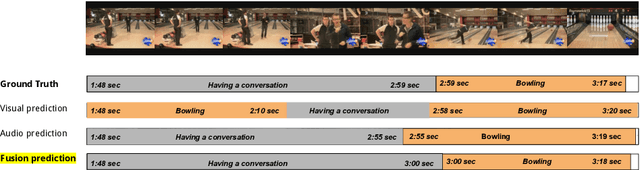
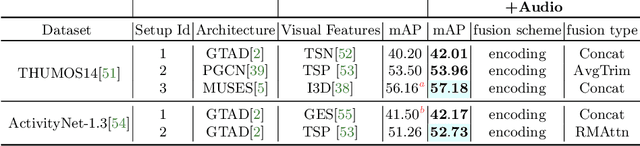
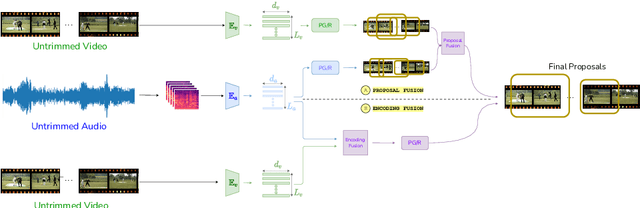

State of the art architectures for untrimmed video Temporal Action Localization (TAL) have only considered RGB and Flow modalities, leaving the information-rich audio modality totally unexploited. Audio fusion has been explored for the related but arguably easier problem of trimmed (clip-level) action recognition. However, TAL poses a unique set of challenges. In this paper, we propose simple but effective fusion-based approaches for TAL. To the best of our knowledge, our work is the first to jointly consider audio and video modalities for supervised TAL. We experimentally show that our schemes consistently improve performance for state of the art video-only TAL approaches. Specifically, they help achieve new state of the art performance on large-scale benchmark datasets - ActivityNet-1.3 (54.34 mAP@0.5) and THUMOS14 (57.18 mAP@0.5). Our experiments include ablations involving multiple fusion schemes, modality combinations and TAL architectures. Our code, models and associated data will be made available.