 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReferEverything: Towards Segmenting Everything We Can Speak of in Videos
Paper and Code



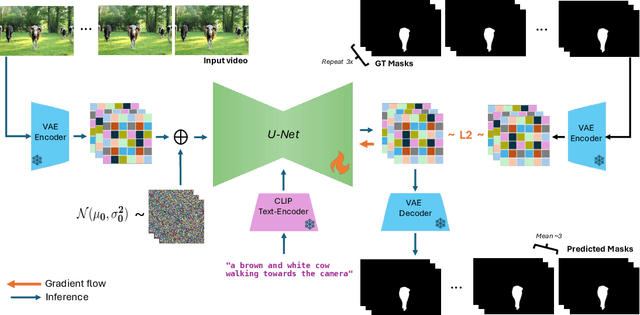
We present REM, a framework for segmenting a wide range of concepts in video that can be described through natural language. Our method capitalizes on visual-language representations learned by video diffusion models on Internet-scale datasets. A key insight of our approach is preserving as much of the generative model's original representation as possible, while fine-tuning it on narrow-domain Referral Object Segmentation datasets. As a result, our framework can accurately segment and track rare and unseen objects, despite being trained on object masks from a limited set of categories. Additionally, it can generalize to non-object dynamic concepts, such as waves crashing in the ocean, as demonstrated in our newly introduced benchmark for Referral Video Process Segmentation (Ref-VPS). Our experiments show that REM performs on par with state-of-the-art approaches on in-domain datasets, like Ref-DAVIS, while outperforming them by up to twelve points in terms of region similarity on out-of-domain data, leveraging the power of Internet-scale pre-training.