 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMomentum Boosted Episodic Memory for Improving Learning in Long-Tailed RL Environments
Apr 08, 2025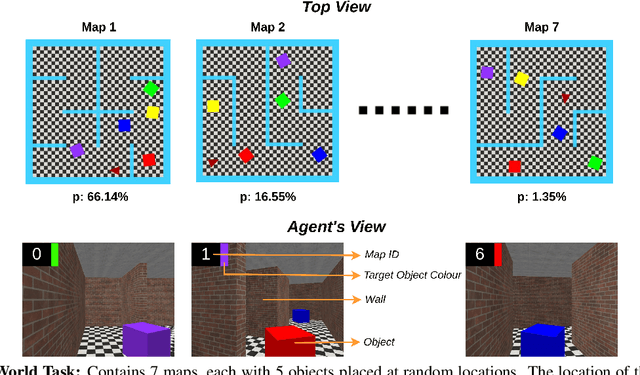
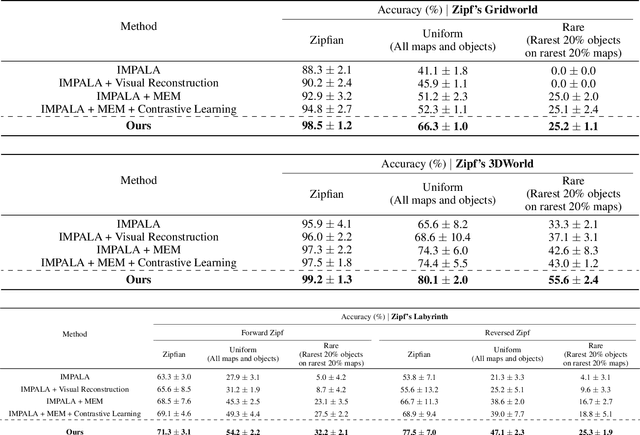
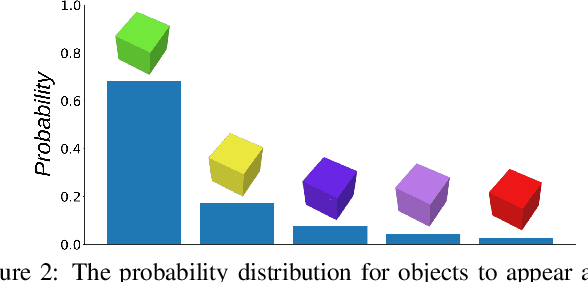
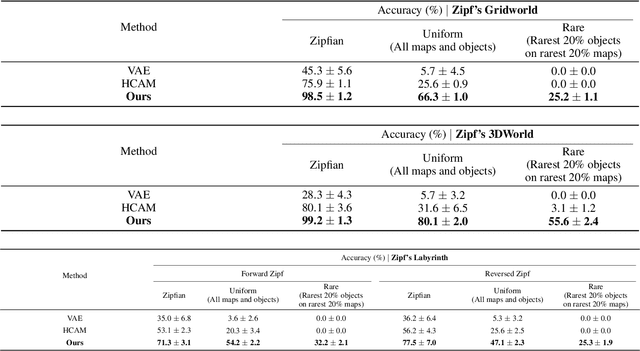
Traditional Reinforcement Learning (RL) algorithms assume the distribution of the data to be uniform or mostly uniform. However, this is not the case with most real-world applications like autonomous driving or in nature where animals roam. Some experiences are encountered frequently, and most of the remaining experiences occur rarely; the resulting distribution is called Zipfian. Taking inspiration from the theory of complementary learning systems, an architecture for learning from Zipfian distributions is proposed where important long tail trajectories are discovered in an unsupervised manner. The proposal comprises an episodic memory buffer containing a prioritised memory module to ensure important rare trajectories are kept longer to address the Zipfian problem, which needs credit assignment to happen in a sample efficient manner. The experiences are then reinstated from episodic memory and given weighted importance forming the trajectory to be executed. Notably, the proposed architecture is modular, can be incorporated in any RL architecture and yields improved performance in multiple Zipfian tasks over traditional architectures. Our method outperforms IMPALA by a significant margin on all three tasks and all three evaluation metrics (Zipfian, Uniform, and Rare Accuracy) and also gives improvements on most Atari environments that are considered challenging
Hear Me Out: Fusional Approaches for Audio Augmented Temporal Action Localization
Jul 06, 2021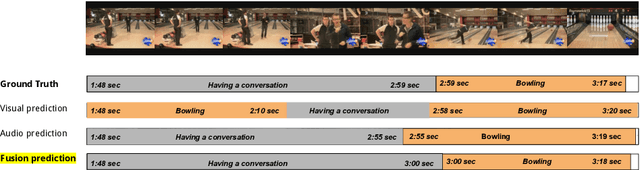
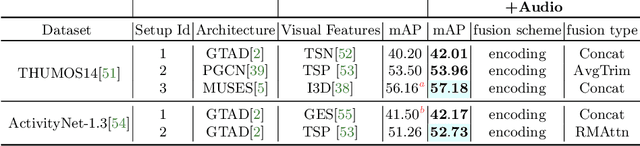
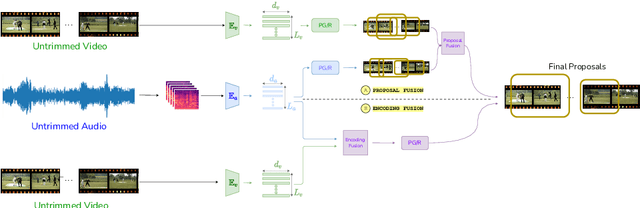

State of the art architectures for untrimmed video Temporal Action Localization (TAL) have only considered RGB and Flow modalities, leaving the information-rich audio modality totally unexploited. Audio fusion has been explored for the related but arguably easier problem of trimmed (clip-level) action recognition. However, TAL poses a unique set of challenges. In this paper, we propose simple but effective fusion-based approaches for TAL. To the best of our knowledge, our work is the first to jointly consider audio and video modalities for supervised TAL. We experimentally show that our schemes consistently improve performance for state of the art video-only TAL approaches. Specifically, they help achieve new state of the art performance on large-scale benchmark datasets - ActivityNet-1.3 (54.34 mAP@0.5) and THUMOS14 (57.18 mAP@0.5). Our experiments include ablations involving multiple fusion schemes, modality combinations and TAL architectures. Our code, models and associated data will be made available.