 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMomentum Boosted Episodic Memory for Improving Learning in Long-Tailed RL Environments
Apr 08, 2025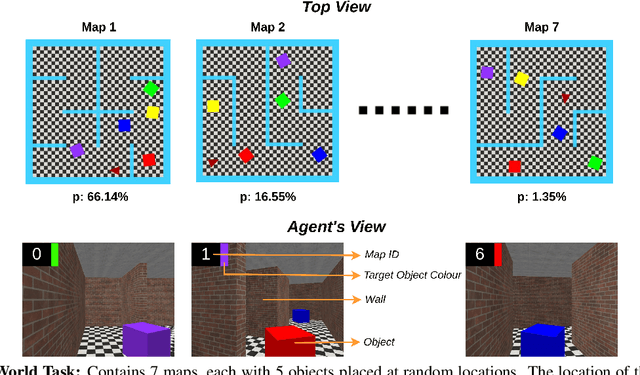
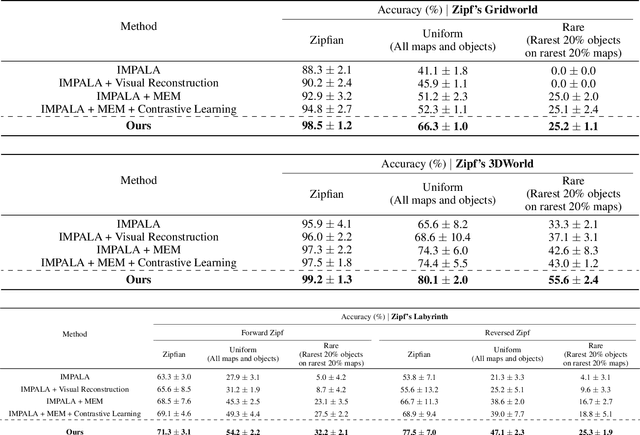
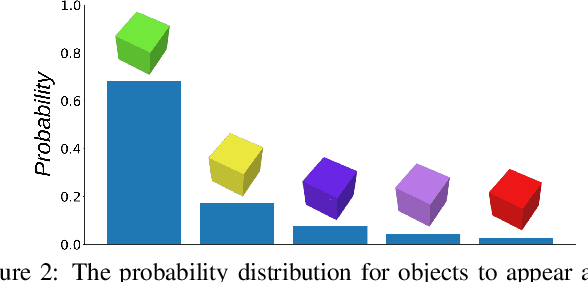
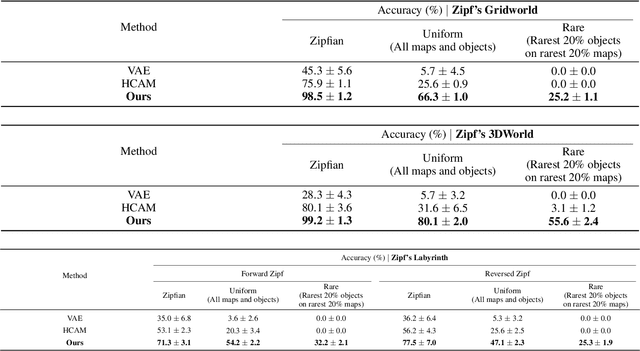
Traditional Reinforcement Learning (RL) algorithms assume the distribution of the data to be uniform or mostly uniform. However, this is not the case with most real-world applications like autonomous driving or in nature where animals roam. Some experiences are encountered frequently, and most of the remaining experiences occur rarely; the resulting distribution is called Zipfian. Taking inspiration from the theory of complementary learning systems, an architecture for learning from Zipfian distributions is proposed where important long tail trajectories are discovered in an unsupervised manner. The proposal comprises an episodic memory buffer containing a prioritised memory module to ensure important rare trajectories are kept longer to address the Zipfian problem, which needs credit assignment to happen in a sample efficient manner. The experiences are then reinstated from episodic memory and given weighted importance forming the trajectory to be executed. Notably, the proposed architecture is modular, can be incorporated in any RL architecture and yields improved performance in multiple Zipfian tasks over traditional architectures. Our method outperforms IMPALA by a significant margin on all three tasks and all three evaluation metrics (Zipfian, Uniform, and Rare Accuracy) and also gives improvements on most Atari environments that are considered challenging
Multi-State-Action Tokenisation in Decision Transformers for Multi-Discrete Action Spaces
Jul 01, 2024



Decision Transformers, in their vanilla form, struggle to perform on image-based environments with multi-discrete action spaces. Although enhanced Decision Transformer architectures have been developed to improve performance, these methods have not specifically addressed this problem of multi-discrete action spaces which hampers existing Decision Transformer architectures from learning good representations. To mitigate this, we propose Multi-State Action Tokenisation (M-SAT), an approach for tokenising actions in multi-discrete action spaces that enhances the model's performance in such environments. Our approach involves two key changes: disentangling actions to the individual action level and tokenising the actions with auxiliary state information. These two key changes also improve individual action level interpretability and visibility within the attention layers. We demonstrate the performance gains of M-SAT on challenging ViZDoom environments with multi-discrete action spaces and image-based state spaces, including the Deadly Corridor and My Way Home scenarios, where M-SAT outperforms the baseline Decision Transformer without any additional data or heavy computational overheads. Additionally, we find that removing positional encoding does not adversely affect M-SAT's performance and, in some cases, even improves it.
Exploring Value Biases: How LLMs Deviate Towards the Ideal
Feb 21, 2024



Large-Language-Models (LLMs) are deployed in a wide range of applications, and their response has an increasing social impact. Understanding the non-deliberate(ive) mechanism of LLMs in giving responses is essential in explaining their performance and discerning their biases in real-world applications. This is analogous to human studies, where such inadvertent responses are referred to as sampling. We study this sampling of LLMs in light of value bias and show that the sampling of LLMs tends to favour high-value options. Value bias corresponds to this shift of response from the most likely towards an ideal value represented in the LLM. In fact, this effect can be reproduced even with new entities learnt via in-context prompting. We show that this bias manifests in unexpected places and has implications on relevant application scenarios, like choosing exemplars. The results show that value bias is strong in LLMs across different categories, similar to the results found in human studies.
A Conservative Q-Learning approach for handling distribution shift in sepsis treatment strategies
Mar 25, 2022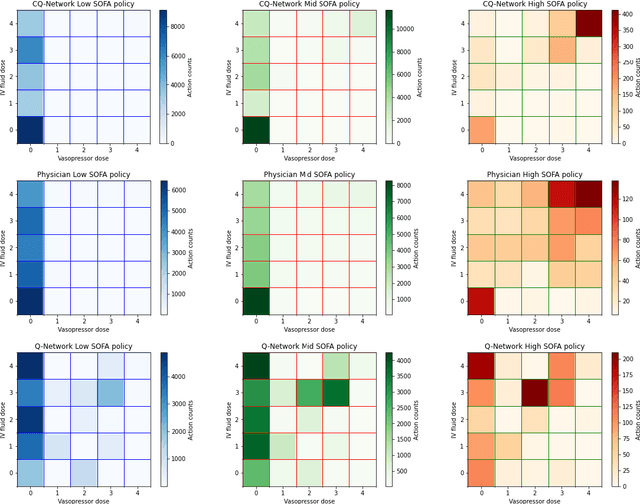
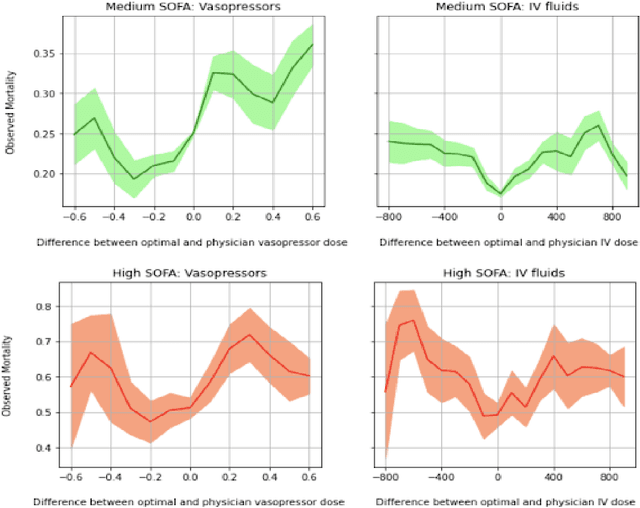
Sepsis is a leading cause of mortality and its treatment is very expensive. Sepsis treatment is also very challenging because there is no consensus on what interventions work best and different patients respond very differently to the same treatment. Deep Reinforcement Learning methods can be used to come up with optimal policies for treatment strategies mirroring physician actions. In the healthcare scenario, the available data is mostly collected offline with no interaction with the environment, which necessitates the use of offline RL techniques. The Offline RL paradigm suffers from action distribution shifts which in turn negatively affects learning an optimal policy for the treatment. In this work, a Conservative-Q Learning (CQL) algorithm is used to mitigate this shift and its corresponding policy reaches closer to the physicians policy than conventional deep Q Learning. The policy learned could help clinicians in Intensive Care Units to make better decisions while treating septic patients and improve survival rate.