 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Factored MDP Approach To Moving Target Defense With Dynamic Threat Modeling and Cost Efficiency
Aug 16, 2024Moving Target Defense (MTD) has emerged as a proactive and dynamic framework to counteract evolving cyber threats. Traditional MTD approaches often rely on assumptions about the attackers knowledge and behavior. However, real-world scenarios are inherently more complex, with adaptive attackers and limited prior knowledge of their payoffs and intentions. This paper introduces a novel approach to MTD using a Markov Decision Process (MDP) model that does not rely on predefined attacker payoffs. Our framework integrates the attackers real-time responses into the defenders MDP using a dynamic Bayesian Network. By employing a factored MDP model, we provide a comprehensive and realistic system representation. We also incorporate incremental updates to an attack response predictor as new data emerges. This ensures an adaptive and robust defense mechanism. Additionally, we consider the costs of switching configurations in MTD, integrating them into the reward structure to balance execution and defense costs. We first highlight the challenges of the problem through a theoretical negative result on regret. However, empirical evaluations demonstrate the frameworks effectiveness in scenarios marked by high uncertainty and dynamically changing attack landscapes.
Preserving the Privacy of Reward Functions in MDPs through Deception
Jul 13, 2024

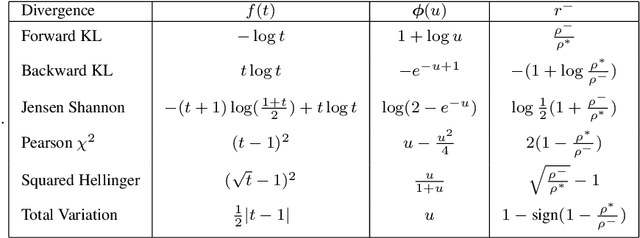

Preserving the privacy of preferences (or rewards) of a sequential decision-making agent when decisions are observable is crucial in many physical and cybersecurity domains. For instance, in wildlife monitoring, agents must allocate patrolling resources without revealing animal locations to poachers. This paper addresses privacy preservation in planning over a sequence of actions in MDPs, where the reward function represents the preference structure to be protected. Observers can use Inverse RL (IRL) to learn these preferences, making this a challenging task. Current research on differential privacy in reward functions fails to ensure guarantee on the minimum expected reward and offers theoretical guarantees that are inadequate against IRL-based observers. To bridge this gap, we propose a novel approach rooted in the theory of deception. Deception includes two models: dissimulation (hiding the truth) and simulation (showing the wrong). Our first contribution theoretically demonstrates significant privacy leaks in existing dissimulation-based methods. Our second contribution is a novel RL-based planning algorithm that uses simulation to effectively address these privacy concerns while ensuring a guarantee on the expected reward. Experiments on multiple benchmark problems show that our approach outperforms previous methods in preserving reward function privacy.
Multi-State-Action Tokenisation in Decision Transformers for Multi-Discrete Action Spaces
Jul 01, 2024



Decision Transformers, in their vanilla form, struggle to perform on image-based environments with multi-discrete action spaces. Although enhanced Decision Transformer architectures have been developed to improve performance, these methods have not specifically addressed this problem of multi-discrete action spaces which hampers existing Decision Transformer architectures from learning good representations. To mitigate this, we propose Multi-State Action Tokenisation (M-SAT), an approach for tokenising actions in multi-discrete action spaces that enhances the model's performance in such environments. Our approach involves two key changes: disentangling actions to the individual action level and tokenising the actions with auxiliary state information. These two key changes also improve individual action level interpretability and visibility within the attention layers. We demonstrate the performance gains of M-SAT on challenging ViZDoom environments with multi-discrete action spaces and image-based state spaces, including the Deadly Corridor and My Way Home scenarios, where M-SAT outperforms the baseline Decision Transformer without any additional data or heavy computational overheads. Additionally, we find that removing positional encoding does not adversely affect M-SAT's performance and, in some cases, even improves it.
Safety through feedback in Constrained RL
Jun 28, 2024In safety-critical RL settings, the inclusion of an additional cost function is often favoured over the arduous task of modifying the reward function to ensure the agent's safe behaviour. However, designing or evaluating such a cost function can be prohibitively expensive. For instance, in the domain of self-driving, designing a cost function that encompasses all unsafe behaviours (e.g. aggressive lane changes) is inherently complex. In such scenarios, the cost function can be learned from feedback collected offline in between training rounds. This feedback can be system generated or elicited from a human observing the training process. Previous approaches have not been able to scale to complex environments and are constrained to receiving feedback at the state level which can be expensive to collect. To this end, we introduce an approach that scales to more complex domains and extends to beyond state-level feedback, thus, reducing the burden on the evaluator. Inferring the cost function in such settings poses challenges, particularly in assigning credit to individual states based on trajectory-level feedback. To address this, we propose a surrogate objective that transforms the problem into a state-level supervised classification task with noisy labels, which can be solved efficiently. Additionally, it is often infeasible to collect feedback on every trajectory generated by the agent, hence, two fundamental questions arise: (1) Which trajectories should be presented to the human? and (2) How many trajectories are necessary for effective learning? To address these questions, we introduce \textit{novelty-based sampling} that selectively involves the evaluator only when the the agent encounters a \textit{novel} trajectory. We showcase the efficiency of our method through experimentation on several benchmark Safety Gymnasium environments and realistic self-driving scenarios.
City-scale Pollution Aware Traffic Routing by Sampling Max Flows using MCMC
Feb 28, 2023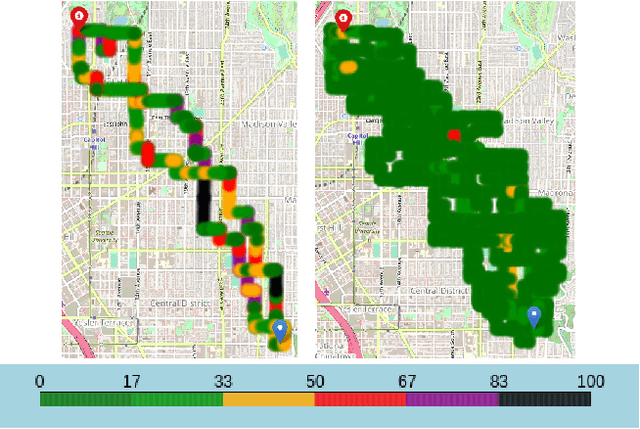
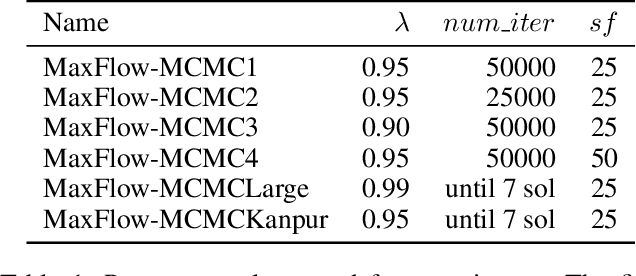
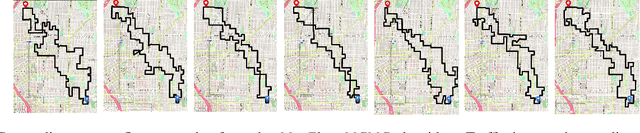
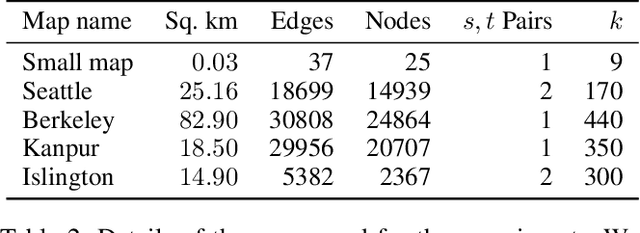
A significant cause of air pollution in urban areas worldwide is the high volume of road traffic. Long-term exposure to severe pollution can cause serious health issues. One approach towards tackling this problem is to design a pollution-aware traffic routing policy that balances multiple objectives of i) avoiding extreme pollution in any area ii) enabling short transit times, and iii) making effective use of the road capacities. We propose a novel sampling-based approach for this problem. We provide the first construction of a Markov Chain that can sample integer max flow solutions of a planar graph, with theoretical guarantees that the probabilities depend on the aggregate transit length. We designed a traffic policy using diverse samples and simulated traffic on real-world road maps using the SUMO traffic simulator. We observe a considerable decrease in areas with severe pollution when experimented with maps of large cities across the world compared to other approaches.
How Private Is Your RL Policy? An Inverse RL Based Analysis Framework
Dec 10, 2021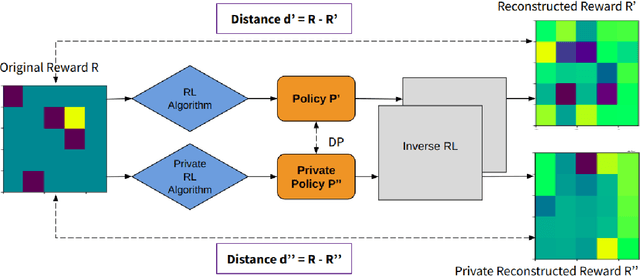


Reinforcement Learning (RL) enables agents to learn how to perform various tasks from scratch. In domains like autonomous driving, recommendation systems, and more, optimal RL policies learned could cause a privacy breach if the policies memorize any part of the private reward. We study the set of existing differentially-private RL policies derived from various RL algorithms such as Value Iteration, Deep Q Networks, and Vanilla Proximal Policy Optimization. We propose a new Privacy-Aware Inverse RL (PRIL) analysis framework, that performs reward reconstruction as an adversarial attack on private policies that the agents may deploy. For this, we introduce the reward reconstruction attack, wherein we seek to reconstruct the original reward from a privacy-preserving policy using an Inverse RL algorithm. An adversary must do poorly at reconstructing the original reward function if the agent uses a tightly private policy. Using this framework, we empirically test the effectiveness of the privacy guarantee offered by the private algorithms on multiple instances of the FrozenLake domain of varying complexities. Based on the analysis performed, we infer a gap between the current standard of privacy offered and the standard of privacy needed to protect reward functions in RL. We do so by quantifying the extent to which each private policy protects the reward function by measuring distances between the original and reconstructed rewards.