 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeADVISER: AI-Driven Vaccination Intervention Optimiser for Increasing Vaccine Uptake in Nigeria
Apr 28, 2022

More than 5 million children under five years die from largely preventable or treatable medical conditions every year, with an overwhelmingly large proportion of deaths occurring in under-developed countries with low vaccination uptake. One of the United Nations' sustainable development goals (SDG 3) aims to end preventable deaths of newborns and children under five years of age. We focus on Nigeria, where the rate of infant mortality is appalling. We collaborate with HelpMum, a large non-profit organization in Nigeria to design and optimize the allocation of heterogeneous health interventions under uncertainty to increase vaccination uptake, the first such collaboration in Nigeria. Our framework, ADVISER: AI-Driven Vaccination Intervention Optimiser, is based on an integer linear program that seeks to maximize the cumulative probability of successful vaccination. Our optimization formulation is intractable in practice. We present a heuristic approach that enables us to solve the problem for real-world use-cases. We also present theoretical bounds for the heuristic method. Finally, we show that the proposed approach outperforms baseline methods in terms of vaccination uptake through experimental evaluation. HelpMum is currently planning a pilot program based on our approach to be deployed in the largest city of Nigeria, which would be the first deployment of an AI-driven vaccination uptake program in the country and hopefully, pave the way for other data-driven programs to improve health outcomes in Nigeria.
How Private Is Your RL Policy? An Inverse RL Based Analysis Framework
Dec 10, 2021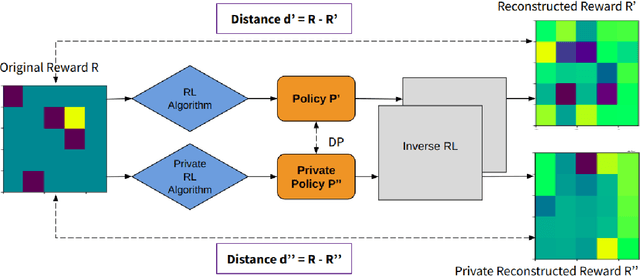


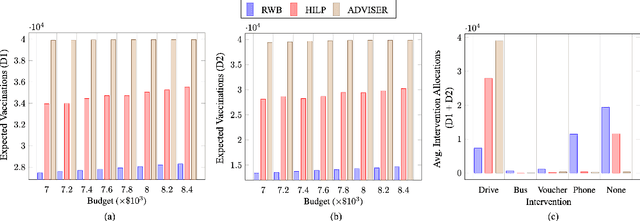
Reinforcement Learning (RL) enables agents to learn how to perform various tasks from scratch. In domains like autonomous driving, recommendation systems, and more, optimal RL policies learned could cause a privacy breach if the policies memorize any part of the private reward. We study the set of existing differentially-private RL policies derived from various RL algorithms such as Value Iteration, Deep Q Networks, and Vanilla Proximal Policy Optimization. We propose a new Privacy-Aware Inverse RL (PRIL) analysis framework, that performs reward reconstruction as an adversarial attack on private policies that the agents may deploy. For this, we introduce the reward reconstruction attack, wherein we seek to reconstruct the original reward from a privacy-preserving policy using an Inverse RL algorithm. An adversary must do poorly at reconstructing the original reward function if the agent uses a tightly private policy. Using this framework, we empirically test the effectiveness of the privacy guarantee offered by the private algorithms on multiple instances of the FrozenLake domain of varying complexities. Based on the analysis performed, we infer a gap between the current standard of privacy offered and the standard of privacy needed to protect reward functions in RL. We do so by quantifying the extent to which each private policy protects the reward function by measuring distances between the original and reconstructed rewards.
Towards General-purpose Infrastructure for Protecting Scientific Data Under Study
Oct 04, 2021

The scientific method presents a key challenge to privacy because it requires many samples to support a claim. When samples are commercially valuable or privacy-sensitive enough, their owners have strong reasons to avoid releasing them for scientific study. Privacy techniques seek to mitigate this tension by enforcing limits on one's ability to use studied samples for secondary purposes. Recent work has begun combining these techniques into end-to-end systems for protecting data. In this work, we assemble the first such combination which is sufficient for a privacy-layman to use familiar tools to experiment over private data while the infrastructure automatically prohibits privacy leakage. We support this theoretical system with a prototype within the Syft privacy platform using the PyTorch framework.
Sensitivity analysis in differentially private machine learning using hybrid automatic differentiation
Jul 09, 2021In recent years, formal methods of privacy protection such as differential privacy (DP), capable of deployment to data-driven tasks such as machine learning (ML), have emerged. Reconciling large-scale ML with the closed-form reasoning required for the principled analysis of individual privacy loss requires the introduction of new tools for automatic sensitivity analysis and for tracking an individual's data and their features through the flow of computation. For this purpose, we introduce a novel \textit{hybrid} automatic differentiation (AD) system which combines the efficiency of reverse-mode AD with an ability to obtain a closed-form expression for any given quantity in the computational graph. This enables modelling the sensitivity of arbitrary differentiable function compositions, such as the training of neural networks on private data. We demonstrate our approach by analysing the individual DP guarantees of statistical database queries. Moreover, we investigate the application of our technique to the training of DP neural networks. Our approach can enable the principled reasoning about privacy loss in the setting of data processing, and further the development of automatic sensitivity analysis and privacy budgeting systems.
Syft 0.5: A Platform for Universally Deployable Structured Transparency
Apr 27, 2021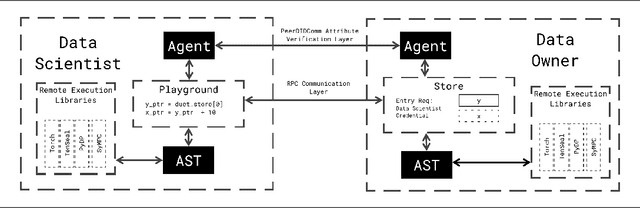
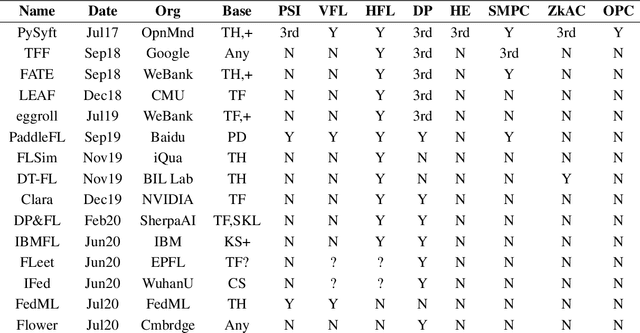
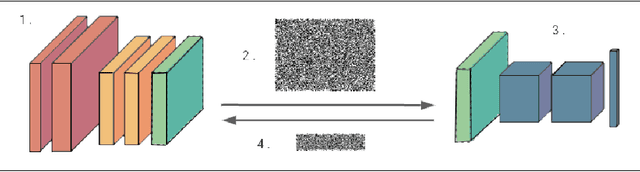
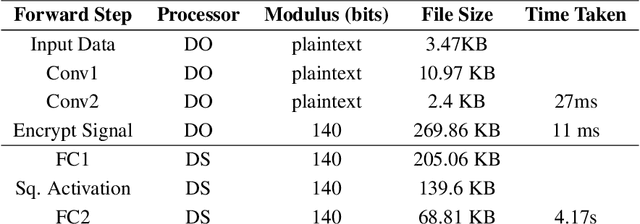
We present Syft 0.5, a general-purpose framework that combines a core group of privacy-enhancing technologies that facilitate a universal set of structured transparency systems. This framework is demonstrated through the design and implementation of a novel privacy-preserving inference information flow where we pass homomorphically encrypted activation signals through a split neural network for inference. We show that splitting the model further up the computation chain significantly reduces the computation time of inference and the payload size of activation signals at the cost of model secrecy. We evaluate our proposed flow with respect to its provision of the core structural transparency principles.