 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBiologically-Informed Hybrid Membership Inference Attacks on Generative Genomic Models
Nov 13, 2025The increased availability of genetic data has transformed genomics research, but raised many privacy concerns regarding its handling due to its sensitive nature. This work explores the use of language models (LMs) for the generation of synthetic genetic mutation profiles, leveraging differential privacy (DP) for the protection of sensitive genetic data. We empirically evaluate the privacy guarantees of our DP modes by introducing a novel Biologically-Informed Hybrid Membership Inference Attack (biHMIA), which combines traditional black box MIA with contextual genomics metrics for enhanced attack power. Our experiments show that both small and large transformer GPT-like models are viable synthetic variant generators for small-scale genomics, and that our hybrid attack leads, on average, to higher adversarial success compared to traditional metric-based MIAs.
Efficient and Private: Memorisation under differentially private parameter-efficient fine-tuning in language models
Nov 24, 2024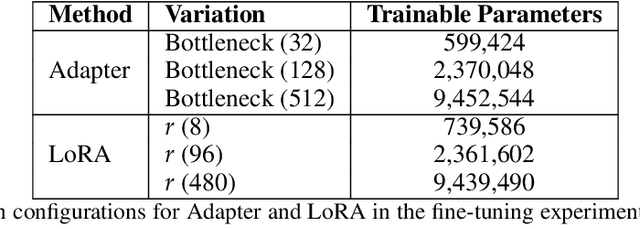
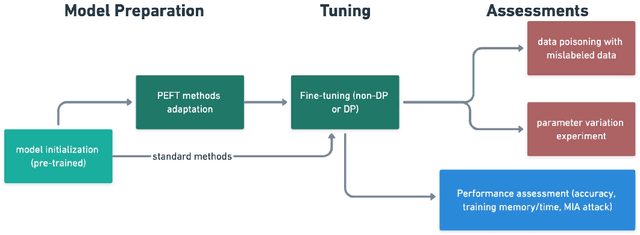

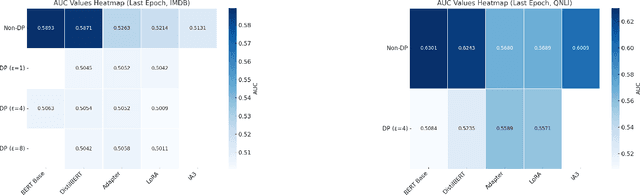
Fine-tuning large language models (LLMs) for specific tasks introduces privacy risks, as models may inadvertently memorise and leak sensitive training data. While Differential Privacy (DP) offers a solution to mitigate these risks, it introduces significant computational and performance trade-offs, particularly with standard fine-tuning approaches. Previous work has primarily focused on full-parameter updates, which are computationally intensive and may not fully leverage DPs potential in large models. In this work, we address these shortcomings by investigating Parameter-Efficient Fine-Tuning (PEFT) methods under DP constraints. We show that PEFT methods achieve comparable performance to standard fine-tuning while requiring fewer parameters and significantly reducing privacy leakage. Furthermore, we incorporate a data poisoning experiment involving intentional mislabelling to assess model memorisation and directly measure privacy risks. Our findings indicate that PEFT methods not only provide a promising alternative but also serve as a complementary approach for privacy-preserving, resource-efficient fine-tuning of LLMs.
Mitigating Backdoor Attacks using Activation-Guided Model Editing
Jul 10, 2024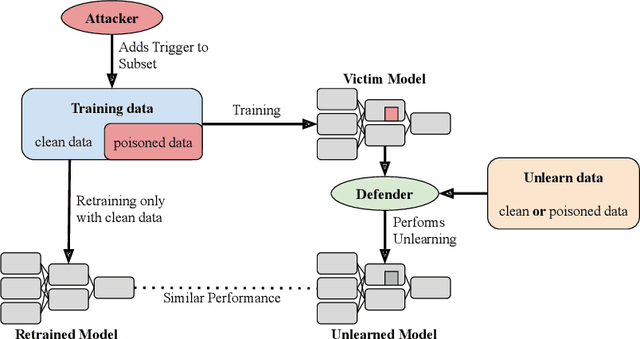
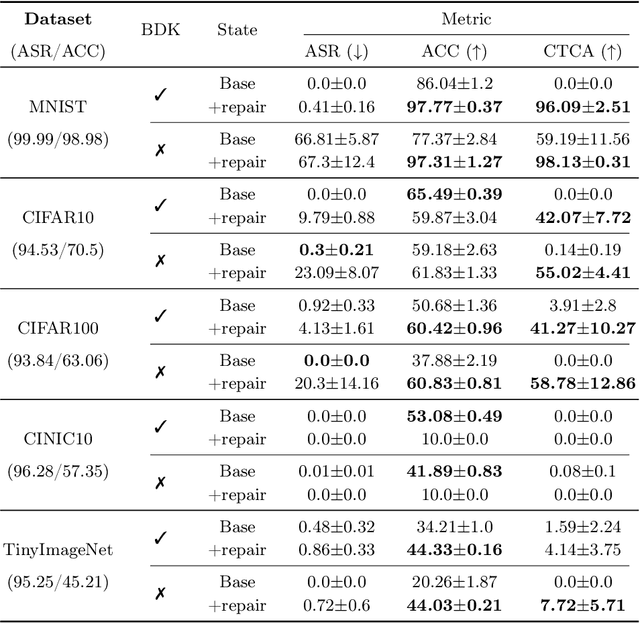

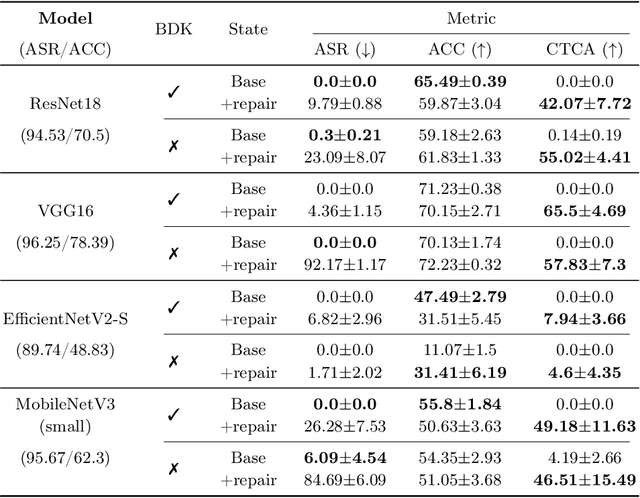
Backdoor attacks compromise the integrity and reliability of machine learning models by embedding a hidden trigger during the training process, which can later be activated to cause unintended misbehavior. We propose a novel backdoor mitigation approach via machine unlearning to counter such backdoor attacks. The proposed method utilizes model activation of domain-equivalent unseen data to guide the editing of the model's weights. Unlike the previous unlearning-based mitigation methods, ours is computationally inexpensive and achieves state-of-the-art performance while only requiring a handful of unseen samples for unlearning. In addition, we also point out that unlearning the backdoor may cause the whole targeted class to be unlearned, thus introducing an additional repair step to preserve the model's utility after editing the model. Experiment results show that the proposed method is effective in unlearning the backdoor on different datasets and trigger patterns.
Naturally Private Recommendations with Determinantal Point Processes
May 22, 2024Often we consider machine learning models or statistical analysis methods which we endeavour to alter, by introducing a randomized mechanism, to make the model conform to a differential privacy constraint. However, certain models can often be implicitly differentially private or require significantly fewer alterations. In this work, we discuss Determinantal Point Processes (DPPs) which are dispersion models that balance recommendations based on both the popularity and the diversity of the content. We introduce DPPs, derive and discuss the alternations required for them to satisfy epsilon-Differential Privacy and provide an analysis of their sensitivity. We conclude by proposing simple alternatives to DPPs which would make them more efficient with respect to their privacy-utility trade-off.
SoK: Memorisation in machine learning
Nov 06, 2023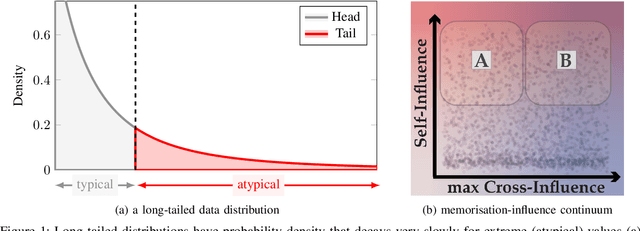


Quantifying the impact of individual data samples on machine learning models is an open research problem. This is particularly relevant when complex and high-dimensional relationships have to be learned from a limited sample of the data generating distribution, such as in deep learning. It was previously shown that, in these cases, models rely not only on extracting patterns which are helpful for generalisation, but also seem to be required to incorporate some of the training data more or less as is, in a process often termed memorisation. This raises the question: if some memorisation is a requirement for effective learning, what are its privacy implications? In this work we unify a broad range of previous definitions and perspectives on memorisation in ML, discuss their interplay with model generalisation and their implications of these phenomena on data privacy. Moreover, we systematise methods allowing practitioners to detect the occurrence of memorisation or quantify it and contextualise our findings in a broad range of ML learning settings. Finally, we discuss memorisation in the context of privacy attacks, differential privacy (DP) and adversarial actors.
Leveraging gradient-derived metrics for data selection and valuation in differentially private training
May 05, 2023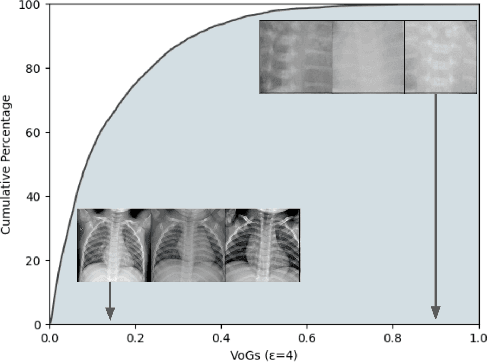
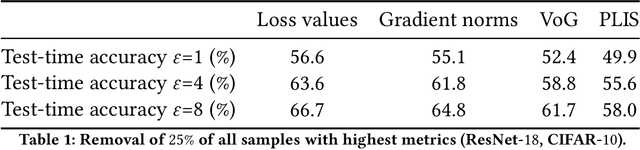

Obtaining high-quality data for collaborative training of machine learning models can be a challenging task due to A) the regulatory concerns and B) lack of incentive to participate. The first issue can be addressed through the use of privacy enhancing technologies (PET), one of the most frequently used one being differentially private (DP) training. The second challenge can be addressed by identifying which data points can be beneficial for model training and rewarding data owners for sharing this data. However, DP in deep learning typically adversely affects atypical (often informative) data samples, making it difficult to assess the usefulness of individual contributions. In this work we investigate how to leverage gradient information to identify training samples of interest in private training settings. We show that there exist techniques which are able to provide the clients with the tools for principled data selection even in strictest privacy settings.
How Do Input Attributes Impact the Privacy Loss in Differential Privacy?
Nov 18, 2022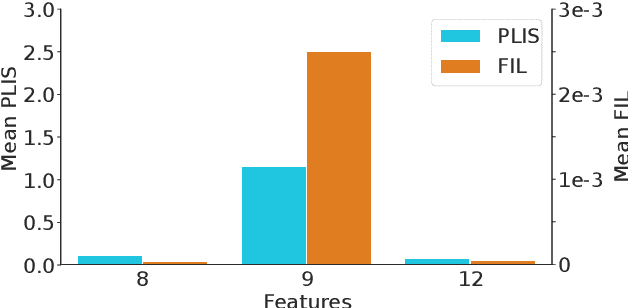

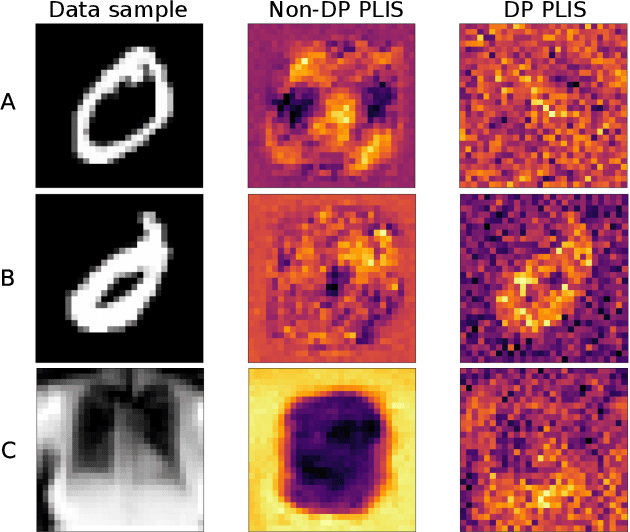

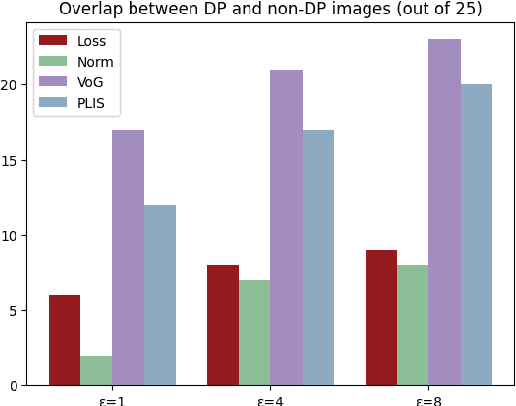
Differential privacy (DP) is typically formulated as a worst-case privacy guarantee over all individuals in a database. More recently, extensions to individual subjects or their attributes, have been introduced. Under the individual/per-instance DP interpretation, we study the connection between the per-subject gradient norm in DP neural networks and individual privacy loss and introduce a novel metric termed the Privacy Loss-Input Susceptibility (PLIS), which allows one to apportion the subject's privacy loss to their input attributes. We experimentally show how this enables the identification of sensitive attributes and of subjects at high risk of data reconstruction.
Can collaborative learning be private, robust and scalable?
May 05, 2022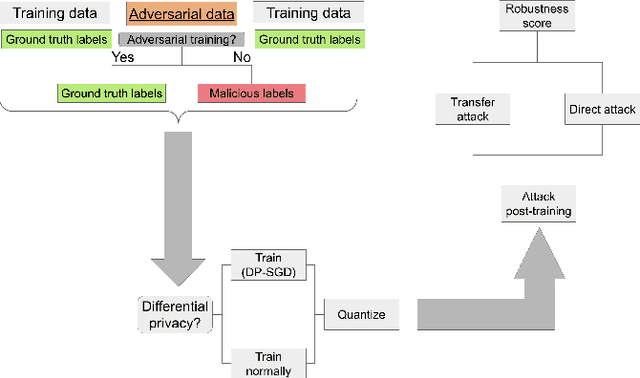



We investigate the effectiveness of combining differential privacy, model compression and adversarial training to improve the robustness of models against adversarial samples in train- and inference-time attacks. We explore the applications of these techniques as well as their combinations to determine which method performs best, without a significant utility trade-off. Our investigation provides a practical overview of various methods that allow one to achieve a competitive model performance, a significant reduction in model's size and an improved empirical adversarial robustness without a severe performance degradation.
SoK: Differential Privacy on Graph-Structured Data
Mar 17, 2022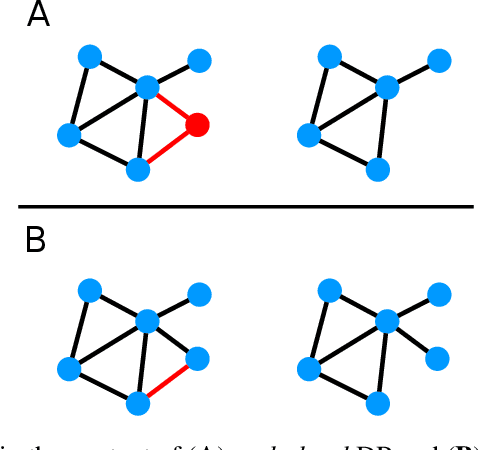
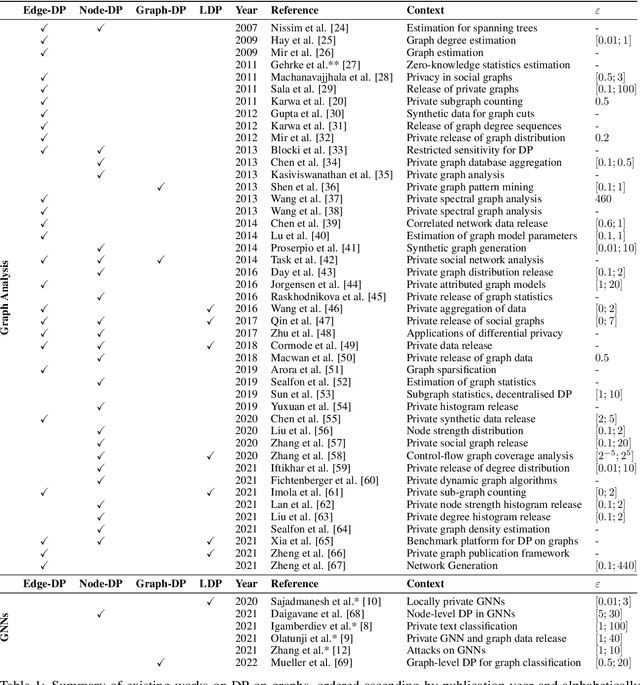
In this work, we study the applications of differential privacy (DP) in the context of graph-structured data. We discuss the formulations of DP applicable to the publication of graphs and their associated statistics as well as machine learning on graph-based data, including graph neural networks (GNNs). The formulation of DP in the context of graph-structured data is difficult, as individual data points are interconnected (often non-linearly or sparsely). This connectivity complicates the computation of individual privacy loss in differentially private learning. The problem is exacerbated by an absence of a single, well-established formulation of DP in graph settings. This issue extends to the domain of GNNs, rendering private machine learning on graph-structured data a challenging task. A lack of prior systematisation work motivated us to study graph-based learning from a privacy perspective. In this work, we systematise different formulations of DP on graphs, discuss challenges and promising applications, including the GNN domain. We compare and separate works into graph analysis tasks and graph learning tasks with GNNs. Finally, we conclude our work with a discussion of open questions and potential directions for further research in this area.
Beyond Gradients: Exploiting Adversarial Priors in Model Inversion Attacks
Mar 01, 2022
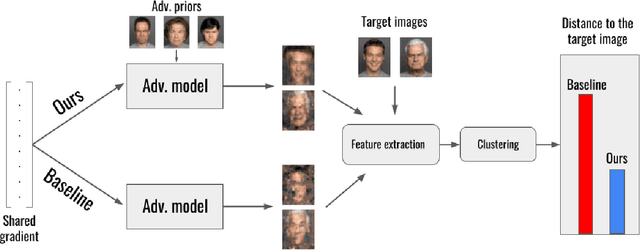
Collaborative machine learning settings like federated learning can be susceptible to adversarial interference and attacks. One class of such attacks is termed model inversion attacks, characterised by the adversary reverse-engineering the model to extract representations and thus disclose the training data. Prior implementations of this attack typically only rely on the captured data (i.e. the shared gradients) and do not exploit the data the adversary themselves control as part of the training consortium. In this work, we propose a novel model inversion framework that builds on the foundations of gradient-based model inversion attacks, but additionally relies on matching the features and the style of the reconstructed image to data that is controlled by an adversary. Our technique outperforms existing gradient-based approaches both qualitatively and quantitatively, while still maintaining the same honest-but-curious threat model, allowing the adversary to obtain enhanced reconstructions while remaining concealed.