 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Gradients: Exploiting Adversarial Priors in Model Inversion Attacks
Paper and Code
Mar 01, 2022
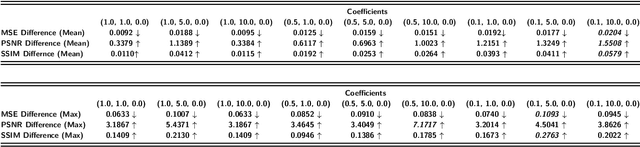
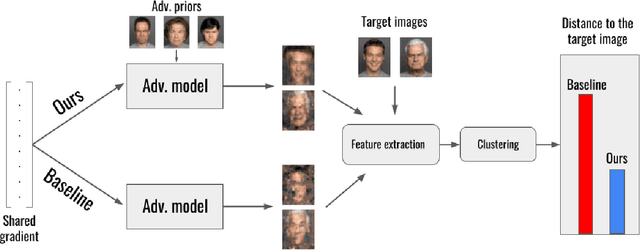
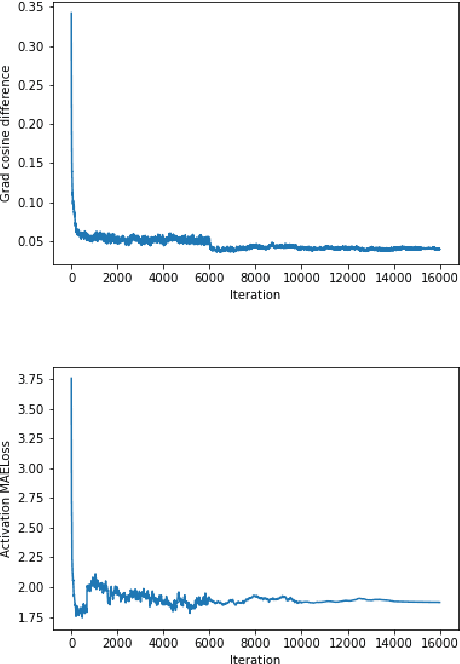
Collaborative machine learning settings like federated learning can be susceptible to adversarial interference and attacks. One class of such attacks is termed model inversion attacks, characterised by the adversary reverse-engineering the model to extract representations and thus disclose the training data. Prior implementations of this attack typically only rely on the captured data (i.e. the shared gradients) and do not exploit the data the adversary themselves control as part of the training consortium. In this work, we propose a novel model inversion framework that builds on the foundations of gradient-based model inversion attacks, but additionally relies on matching the features and the style of the reconstructed image to data that is controlled by an adversary. Our technique outperforms existing gradient-based approaches both qualitatively and quantitatively, while still maintaining the same honest-but-curious threat model, allowing the adversary to obtain enhanced reconstructions while remaining concealed.