 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan collaborative learning be private, robust and scalable?
May 05, 2022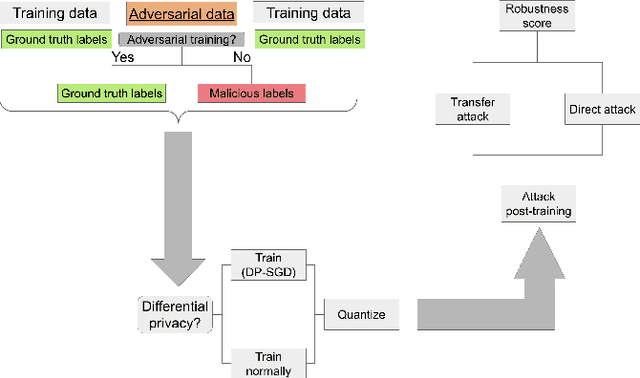



We investigate the effectiveness of combining differential privacy, model compression and adversarial training to improve the robustness of models against adversarial samples in train- and inference-time attacks. We explore the applications of these techniques as well as their combinations to determine which method performs best, without a significant utility trade-off. Our investigation provides a practical overview of various methods that allow one to achieve a competitive model performance, a significant reduction in model's size and an improved empirical adversarial robustness without a severe performance degradation.
Differentially private training of residual networks with scale normalisation
Mar 01, 2022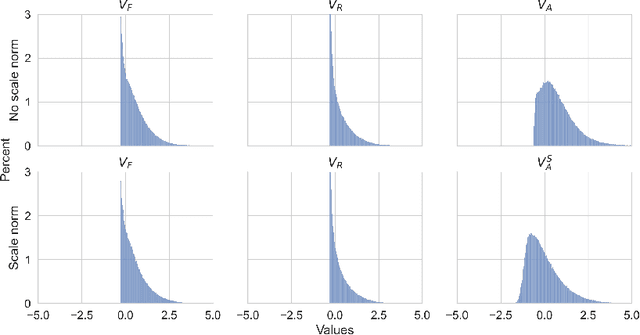
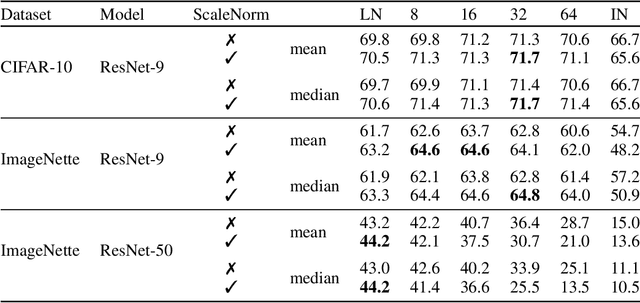
We investigate the optimal choice of replacement layer for Batch Normalisation (BN) in residual networks (ResNets) for training with Differentially Private Stochastic Gradient Descent (DP-SGD) and study the phenomenon of scale mixing in residual blocks, whereby the activations on the two branches are scaled differently. Our experimental evaluation indicates that a hyperparameter search over 1-64 Group Normalisation (GN) groups improves the accuracy of ResNet-9 and ResNet-50 considerably in both benchmark (CIFAR-10) and large-image (ImageNette) tasks. Moreover, Scale Normalisation, a simple modification to the model architecture by which an additional normalisation layer is introduced after the residual block's addition operation further improves the utility of ResNets allowing us to achieve state-of-the-art results on CIFAR-10.