 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYour Privacy Depends on Others: Collusion Vulnerabilities in Individual Differential Privacy
Jan 19, 2026Individual Differential Privacy (iDP) promises users control over their privacy, but this promise can be broken in practice. We reveal a previously overlooked vulnerability in sampling-based iDP mechanisms: while conforming to the iDP guarantees, an individual's privacy risk is not solely governed by their own privacy budget, but critically depends on the privacy choices of all other data contributors. This creates a mismatch between the promise of individual privacy control and the reality of a system where risk is collectively determined. We demonstrate empirically that certain distributions of privacy preferences can unintentionally inflate the privacy risk of individuals, even when their formal guarantees are met. Moreover, this excess risk provides an exploitable attack vector. A central adversary or a set of colluding adversaries can deliberately choose privacy budgets to amplify vulnerabilities of targeted individuals. Most importantly, this attack operates entirely within the guarantees of DP, hiding this excess vulnerability. Our empirical evaluation demonstrates successful attacks against 62% of targeted individuals, substantially increasing their membership inference susceptibility. To mitigate this, we propose $(\varepsilon_i,δ_i,\overlineΔ)$-iDP a privacy contract that uses $Δ$-divergences to provide users with a hard upper bound on their excess vulnerability, while offering flexibility to mechanism design. Our findings expose a fundamental challenge to the current paradigm, demanding a re-evaluation of how iDP systems are designed, audited, communicated, and deployed to make excess risks transparent and controllable.
Sensitivity, Specificity, and Consistency: A Tripartite Evaluation of Privacy Filters for Synthetic Data Generation
Oct 02, 2025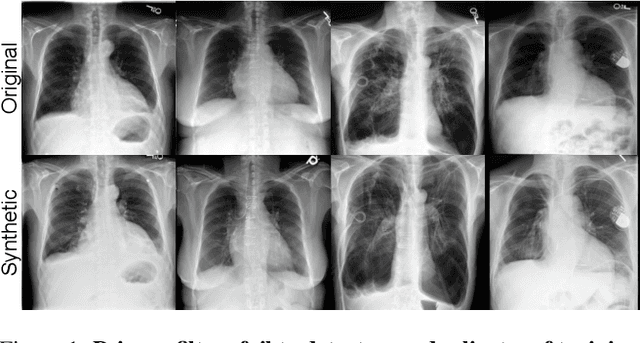
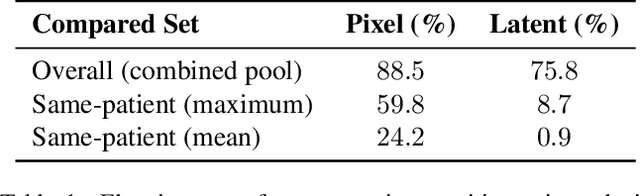
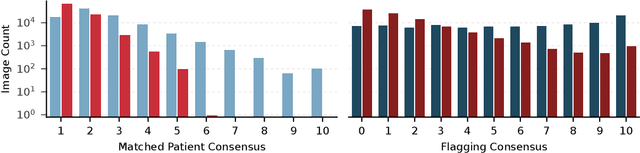
The generation of privacy-preserving synthetic datasets is a promising avenue for overcoming data scarcity in medical AI research. Post-hoc privacy filtering techniques, designed to remove samples containing personally identifiable information, have recently been proposed as a solution. However, their effectiveness remains largely unverified. This work presents a rigorous evaluation of a filtering pipeline applied to chest X-ray synthesis. Contrary to claims from the original publications, our results demonstrate that current filters exhibit limited specificity and consistency, achieving high sensitivity only for real images while failing to reliably detect near-duplicates generated from training data. These results demonstrate a critical limitation of post-hoc filtering: rather than effectively safeguarding patient privacy, these methods may provide a false sense of security while leaving unacceptable levels of patient information exposed. We conclude that substantial advances in filter design are needed before these methods can be confidently deployed in sensitive applications.
Visual Privacy Auditing with Diffusion Models
Mar 12, 2024Image reconstruction attacks on machine learning models pose a significant risk to privacy by potentially leaking sensitive information. Although defending against such attacks using differential privacy (DP) has proven effective, determining appropriate DP parameters remains challenging. Current formal guarantees on data reconstruction success suffer from overly theoretical assumptions regarding adversary knowledge about the target data, particularly in the image domain. In this work, we empirically investigate this discrepancy and find that the practicality of these assumptions strongly depends on the domain shift between the data prior and the reconstruction target. We propose a reconstruction attack based on diffusion models (DMs) that assumes adversary access to real-world image priors and assess its implications on privacy leakage under DP-SGD. We show that (1) real-world data priors significantly influence reconstruction success, (2) current reconstruction bounds do not model the risk posed by data priors well, and (3) DMs can serve as effective auditing tools for visualizing privacy leakage.
Bounding Reconstruction Attack Success of Adversaries Without Data Priors
Feb 20, 2024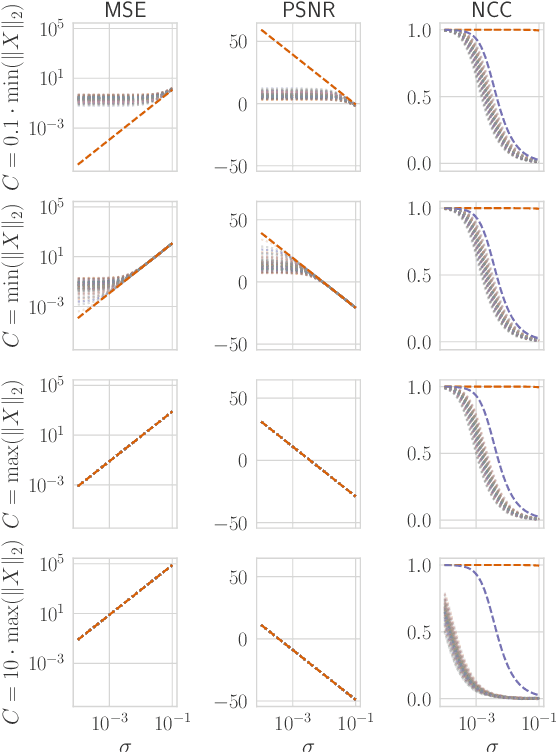
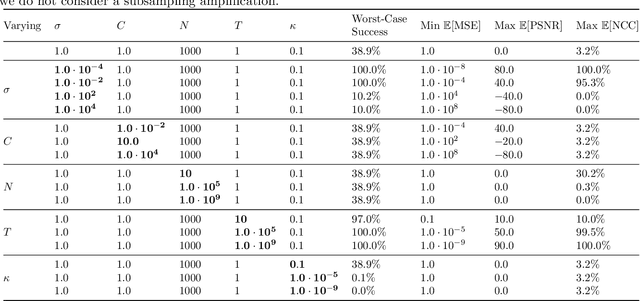
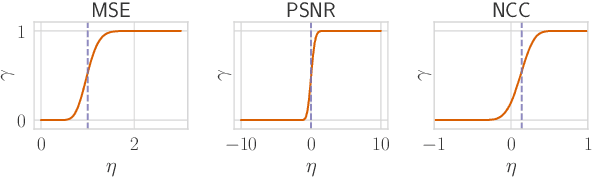
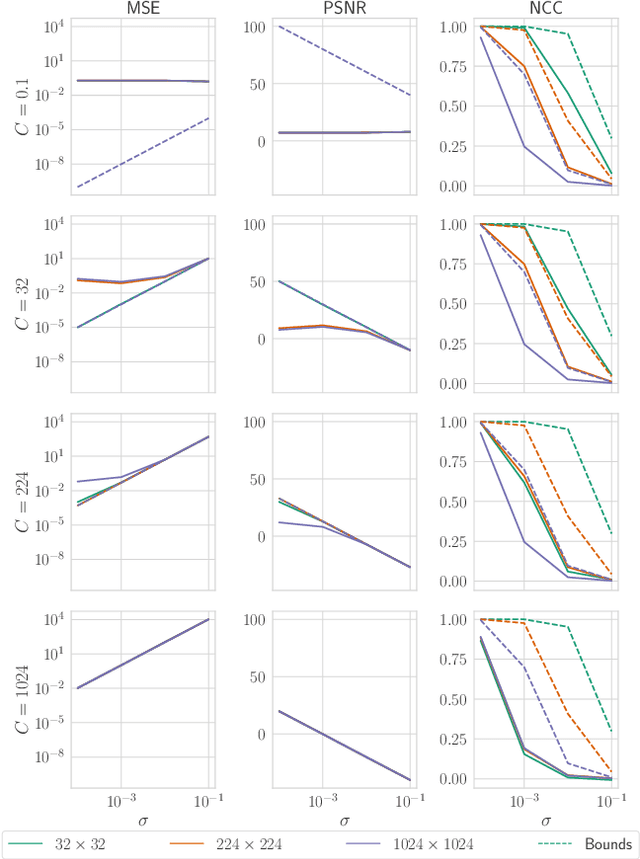
Reconstruction attacks on machine learning (ML) models pose a strong risk of leakage of sensitive data. In specific contexts, an adversary can (almost) perfectly reconstruct training data samples from a trained model using the model's gradients. When training ML models with differential privacy (DP), formal upper bounds on the success of such reconstruction attacks can be provided. So far, these bounds have been formulated under worst-case assumptions that might not hold high realistic practicality. In this work, we provide formal upper bounds on reconstruction success under realistic adversarial settings against ML models trained with DP and support these bounds with empirical results. With this, we show that in realistic scenarios, (a) the expected reconstruction success can be bounded appropriately in different contexts and by different metrics, which (b) allows for a more educated choice of a privacy parameter.
How Low Can You Go? Surfacing Prototypical In-Distribution Samples for Unsupervised Anomaly Detection
Dec 06, 2023
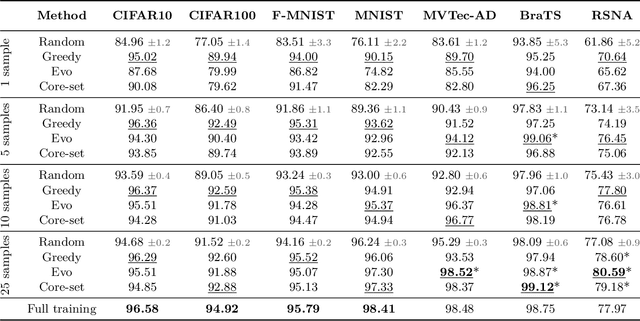
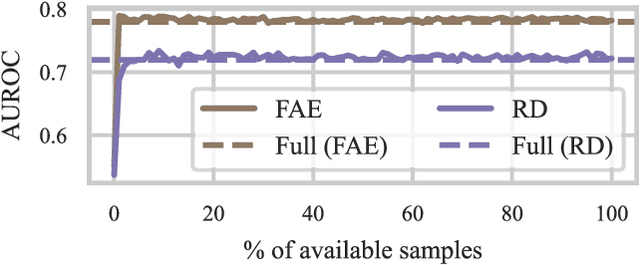
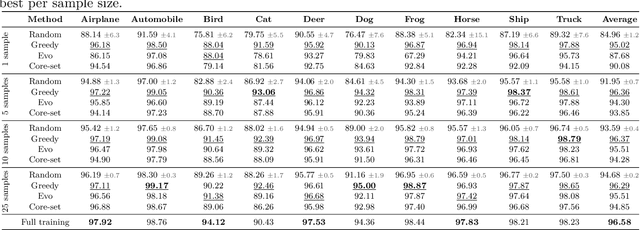
Unsupervised anomaly detection (UAD) alleviates large labeling efforts by training exclusively on unlabeled in-distribution data and detecting outliers as anomalies. Generally, the assumption prevails that large training datasets allow the training of higher-performing UAD models. However, in this work, we show that using only very few training samples can already match - and in some cases even improve - anomaly detection compared to training with the whole training dataset. We propose three methods to identify prototypical samples from a large dataset of in-distribution samples. We demonstrate that by training with a subset of just ten such samples, we achieve an area under the receiver operating characteristics curve (AUROC) of $96.37 \%$ on CIFAR10, $92.59 \%$ on CIFAR100, $95.37 \%$ on MNIST, $95.38 \%$ on Fashion-MNIST, $96.37 \%$ on MVTec-AD, $98.81 \%$ on BraTS, and $81.95 \%$ on RSNA pneumonia detection, even exceeding the performance of full training in $25/67$ classes we tested. Additionally, we show that the prototypical in-distribution samples identified by our proposed methods translate well to different models and other datasets and that using their characteristics as guidance allows for successful manual selection of small subsets of high-performing samples. Our code is available at https://anonymous.4open.science/r/uad_prototypical_samples/
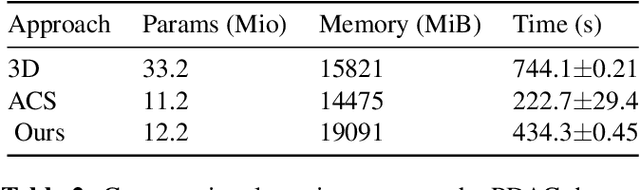
Reconciling AI Performance and Data Reconstruction Resilience for Medical Imaging
Dec 05, 2023



Artificial Intelligence (AI) models are vulnerable to information leakage of their training data, which can be highly sensitive, for example in medical imaging. Privacy Enhancing Technologies (PETs), such as Differential Privacy (DP), aim to circumvent these susceptibilities. DP is the strongest possible protection for training models while bounding the risks of inferring the inclusion of training samples or reconstructing the original data. DP achieves this by setting a quantifiable privacy budget. Although a lower budget decreases the risk of information leakage, it typically also reduces the performance of such models. This imposes a trade-off between robust performance and stringent privacy. Additionally, the interpretation of a privacy budget remains abstract and challenging to contextualize. In this study, we contrast the performance of AI models at various privacy budgets against both, theoretical risk bounds and empirical success of reconstruction attacks. We show that using very large privacy budgets can render reconstruction attacks impossible, while drops in performance are negligible. We thus conclude that not using DP -- at all -- is negligent when applying AI models to sensitive data. We deem those results to lie a foundation for further debates on striking a balance between privacy risks and model performance.
Bias-Aware Minimisation: Understanding and Mitigating Estimator Bias in Private SGD
Aug 23, 2023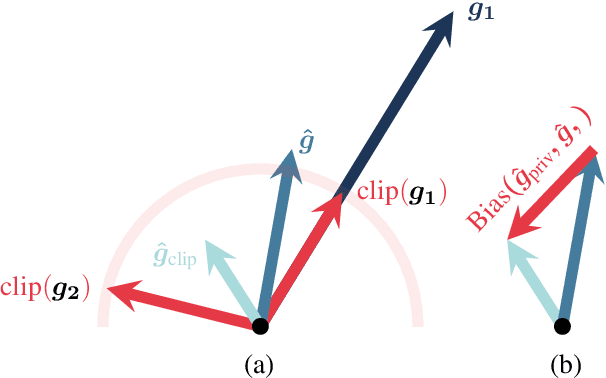
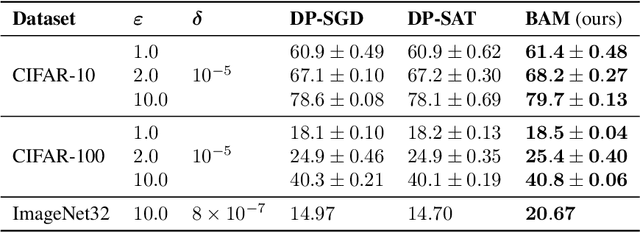
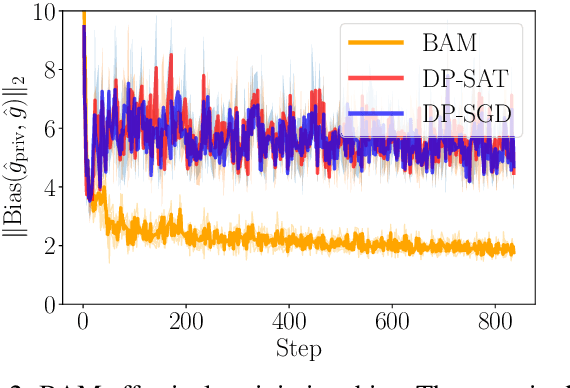
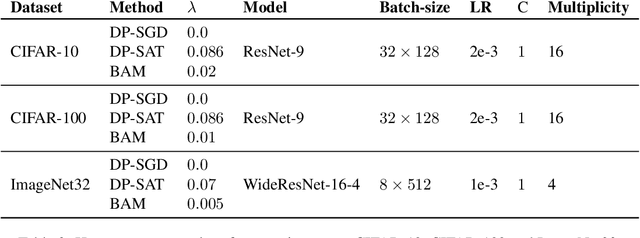
Differentially private SGD (DP-SGD) holds the promise of enabling the safe and responsible application of machine learning to sensitive datasets. However, DP-SGD only provides a biased, noisy estimate of a mini-batch gradient. This renders optimisation steps less effective and limits model utility as a result. With this work, we show a connection between per-sample gradient norms and the estimation bias of the private gradient oracle used in DP-SGD. Here, we propose Bias-Aware Minimisation (BAM) that allows for the provable reduction of private gradient estimator bias. We show how to efficiently compute quantities needed for BAM to scale to large neural networks and highlight similarities to closely related methods such as Sharpness-Aware Minimisation. Finally, we provide empirical evidence that BAM not only reduces bias but also substantially improves privacy-utility trade-offs on the CIFAR-10, CIFAR-100, and ImageNet-32 datasets.
Explainable 2D Vision Models for 3D Medical Data
Jul 13, 2023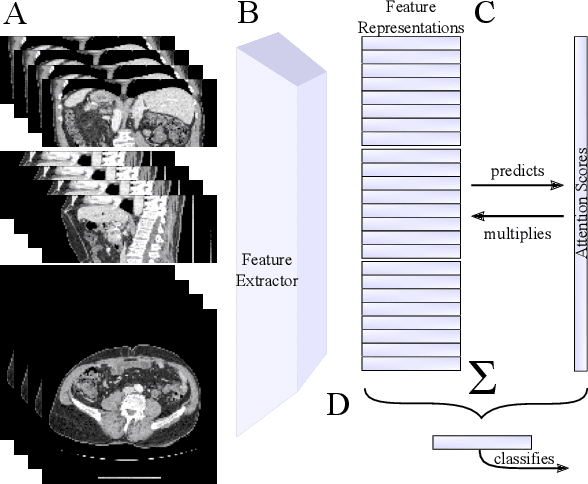
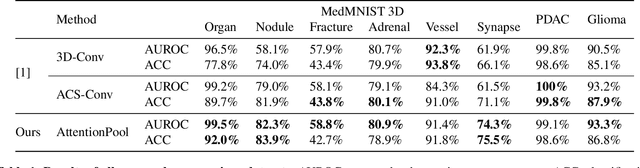
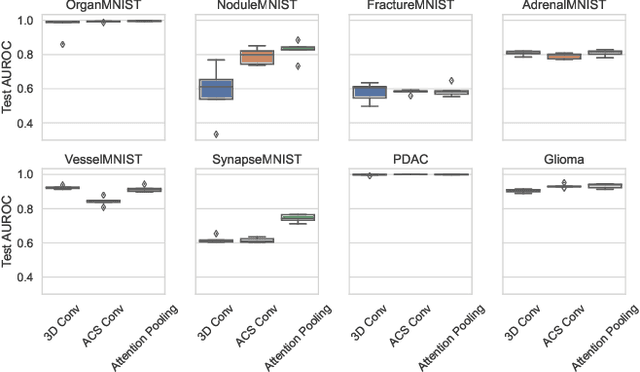
Training Artificial Intelligence (AI) models on three-dimensional image data presents unique challenges compared to the two-dimensional case: Firstly, the computational resources are significantly higher, and secondly, the availability of large pretraining datasets is often limited, impeding training success. In this study, we propose a simple approach of adapting 2D networks with an intermediate feature representation for processing 3D volumes. Our method involves sequentially applying these networks to slices of a 3D volume from all orientations. Subsequently, a feature reduction module combines the extracted slice features into a single representation, which is then used for classification. We evaluate our approach on medical classification benchmarks and a real-world clinical dataset, demonstrating comparable results to existing methods. Furthermore, by employing attention pooling as a feature reduction module we obtain weighted importance values for each slice during the forward pass. We show that slices deemed important by our approach allow the inspection of the basis of a model's prediction.
Body Fat Estimation from Surface Meshes using Graph Neural Networks
Jul 13, 2023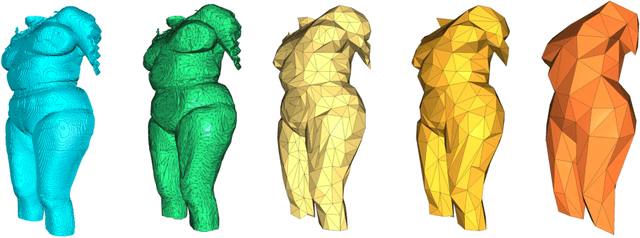

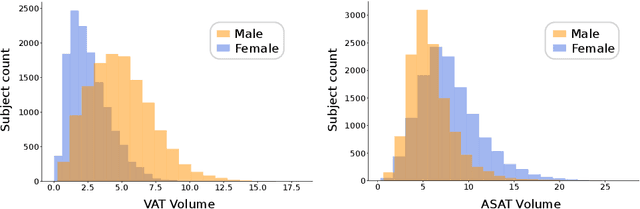

Body fat volume and distribution can be a strong indication for a person's overall health and the risk for developing diseases like type 2 diabetes and cardiovascular diseases. Frequently used measures for fat estimation are the body mass index (BMI), waist circumference, or the waist-hip-ratio. However, those are rather imprecise measures that do not allow for a discrimination between different types of fat or between fat and muscle tissue. The estimation of visceral (VAT) and abdominal subcutaneous (ASAT) adipose tissue volume has shown to be a more accurate measure for named risk factors. In this work, we show that triangulated body surface meshes can be used to accurately predict VAT and ASAT volumes using graph neural networks. Our methods achieve high performance while reducing training time and required resources compared to state-of-the-art convolutional neural networks in this area. We furthermore envision this method to be applicable to cheaper and easily accessible medical surface scans instead of expensive medical images.
Bounding data reconstruction attacks with the hypothesis testing interpretation of differential privacy
Jul 08, 2023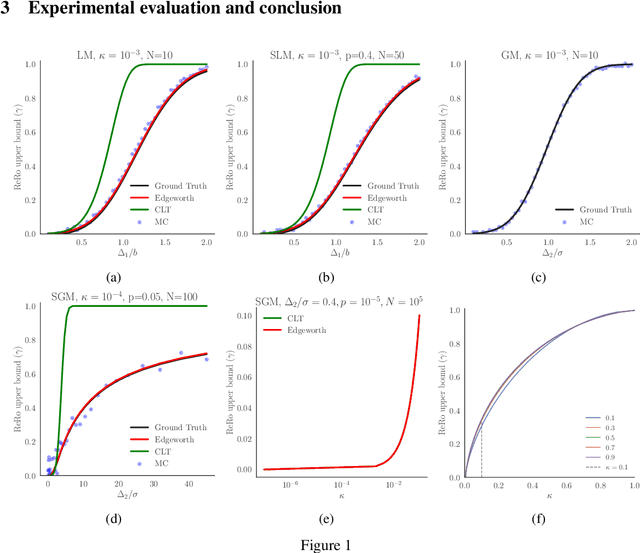
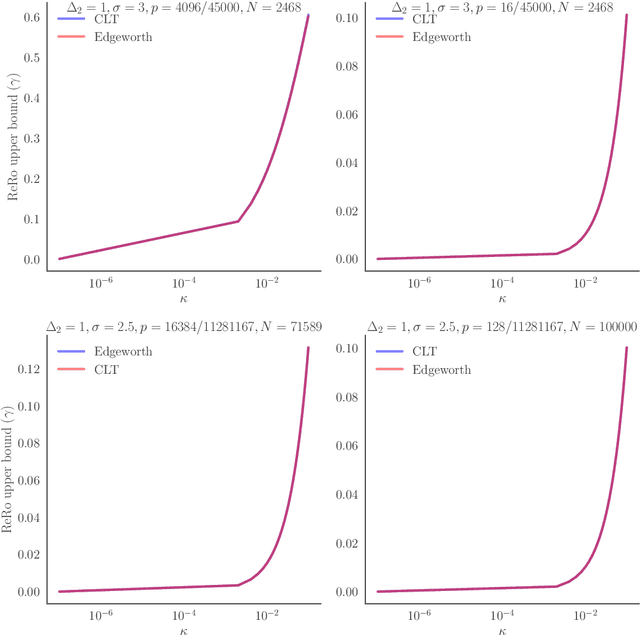
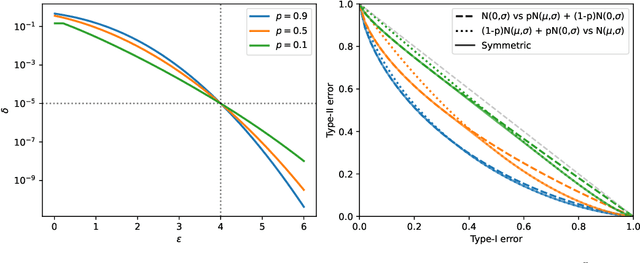
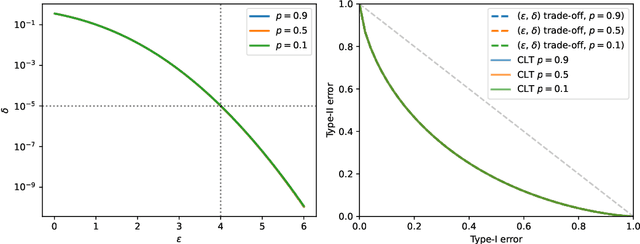
We explore Reconstruction Robustness (ReRo), which was recently proposed as an upper bound on the success of data reconstruction attacks against machine learning models. Previous research has demonstrated that differential privacy (DP) mechanisms also provide ReRo, but so far, only asymptotic Monte Carlo estimates of a tight ReRo bound have been shown. Directly computable ReRo bounds for general DP mechanisms are thus desirable. In this work, we establish a connection between hypothesis testing DP and ReRo and derive closed-form, analytic or numerical ReRo bounds for the Laplace and Gaussian mechanisms and their subsampled variants.