 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePoint-Wise Geometry-Aware Transformer for Partial-to-Full Point Cloud Registration in Computer-Assisted Surgery
Jun 11, 2026Partial-to-full registration remains challenging due to varying overlap ratios, fluctuating point densities, and the presence of noise. While transformers have shown strong potential for point cloud processing, prior methods typically confine them to global context aggregation, overlooking fine-grained local geometry crucial for accurate correspondence. We propose \emph{GAPR-Net}, a learning-based point cloud registration framework with a coarse-to-fine architecture that combines convolution and transformer modules, in which local and global information is fused between the partial and full point clouds using a cross-attention mechanism. To achieve this, a transformation-invariant point-wise geometric feature representation is proposed, which can robustly capture relative geometric features for individual points with respect to their neighboring points. To evaluate the effectiveness of the proposed approach, experiments are conducted on four geometrically distinct bones, including the tibia, femur, pelvis, and thoracic cartilage. The overall registration recall reaches 94.2\%, the method results in a low RMSE of 1.992 mm and $R^2$ values of 0.908 and 0.974 for rotation and translation, respectively. The results demonstrate that the proposed method effectively addresses the partial-to-full point cloud registration problem. The proposed method enables highly accurate 3D point cloud registration using partial observation, providing a critical foundation for precise surgical navigation and robotic interventions in computer-assisted surgery. The code will be accessed after the double-blind review process.
FVG-PT: Adaptive Foreground View-Guided Prompt Tuning for Vision-Language Models
Mar 09, 2026CLIP-based prompt tuning enables pretrained Vision-Language Models (VLMs) to efficiently adapt to downstream tasks. Although existing studies have made significant progress, they pay limited attention to changes in the internal attention representations of VLMs during the tuning process. In this paper, we attribute the failure modes of prompt tuning predictions to shifts in foreground attention of the visual encoder, and propose Foreground View-Guided Prompt Tuning (FVG-PT), an adaptive plug-and-play foreground attention guidance module, to alleviate the shifts. Concretely, FVG-PT introduces a learnable Foreground Reliability Gate to automatically enhance the foreground view quality, applies a Foreground Distillation Compensation module to guide visual attention toward the foreground, and further introduces a Prior Calibration module to mitigate generalization degradation caused by excessive focus on the foreground. Experiments on multiple backbone models and datasets show the effectiveness and compatibility of FVG-PT. Codes are available at: https://github.com/JREion/FVG-PT
Neuro-Symbolic Synergy for Interactive World Modeling
Feb 12, 2026Large language models (LLMs) exhibit strong general-purpose reasoning capabilities, yet they frequently hallucinate when used as world models (WMs), where strict compliance with deterministic transition rules--particularly in corner cases--is essential. In contrast, Symbolic WMs provide logical consistency but lack semantic expressivity. To bridge this gap, we propose Neuro-Symbolic Synergy (NeSyS), a framework that integrates the probabilistic semantic priors of LLMs with executable symbolic rules to achieve both expressivity and robustness. NeSyS alternates training between the two models using trajectories inadequately explained by the other. Unlike rule-based prompting, the symbolic WM directly constrains the LLM by modifying its output probability distribution. The neural WM is fine-tuned only on trajectories not covered by symbolic rules, reducing training data by 50% without loss of accuracy. Extensive experiments on three distinct interactive environments, i.e., ScienceWorld, Webshop, and Plancraft, demonstrate NeSyS's consistent advantages over baselines in both WM prediction accuracy and data efficiency.
DreaMontage: Arbitrary Frame-Guided One-Shot Video Generation
Dec 24, 2025The "one-shot" technique represents a distinct and sophisticated aesthetic in filmmaking. However, its practical realization is often hindered by prohibitive costs and complex real-world constraints. Although emerging video generation models offer a virtual alternative, existing approaches typically rely on naive clip concatenation, which frequently fails to maintain visual smoothness and temporal coherence. In this paper, we introduce DreaMontage, a comprehensive framework designed for arbitrary frame-guided generation, capable of synthesizing seamless, expressive, and long-duration one-shot videos from diverse user-provided inputs. To achieve this, we address the challenge through three primary dimensions. (i) We integrate a lightweight intermediate-conditioning mechanism into the DiT architecture. By employing an Adaptive Tuning strategy that effectively leverages base training data, we unlock robust arbitrary-frame control capabilities. (ii) To enhance visual fidelity and cinematic expressiveness, we curate a high-quality dataset and implement a Visual Expression SFT stage. In addressing critical issues such as subject motion rationality and transition smoothness, we apply a Tailored DPO scheme, which significantly improves the success rate and usability of the generated content. (iii) To facilitate the production of extended sequences, we design a Segment-wise Auto-Regressive (SAR) inference strategy that operates in a memory-efficient manner. Extensive experiments demonstrate that our approach achieves visually striking and seamlessly coherent one-shot effects while maintaining computational efficiency, empowering users to transform fragmented visual materials into vivid, cohesive one-shot cinematic experiences.
Phantom-Data : Towards a General Subject-Consistent Video Generation Dataset
Jun 23, 2025Subject-to-video generation has witnessed substantial progress in recent years. However, existing models still face significant challenges in faithfully following textual instructions. This limitation, commonly known as the copy-paste problem, arises from the widely used in-pair training paradigm. This approach inherently entangles subject identity with background and contextual attributes by sampling reference images from the same scene as the target video. To address this issue, we introduce \textbf{Phantom-Data, the first general-purpose cross-pair subject-to-video consistency dataset}, containing approximately one million identity-consistent pairs across diverse categories. Our dataset is constructed via a three-stage pipeline: (1) a general and input-aligned subject detection module, (2) large-scale cross-context subject retrieval from more than 53 million videos and 3 billion images, and (3) prior-guided identity verification to ensure visual consistency under contextual variation. Comprehensive experiments show that training with Phantom-Data significantly improves prompt alignment and visual quality while preserving identity consistency on par with in-pair baselines.
WALL-E 2.0: World Alignment by NeuroSymbolic Learning improves World Model-based LLM Agents
Apr 22, 2025Can we build accurate world models out of large language models (LLMs)? How can world models benefit LLM agents? The gap between the prior knowledge of LLMs and the specified environment's dynamics usually bottlenecks LLMs' performance as world models. To bridge the gap, we propose a training-free "world alignment" that learns an environment's symbolic knowledge complementary to LLMs. The symbolic knowledge covers action rules, knowledge graphs, and scene graphs, which are extracted by LLMs from exploration trajectories and encoded into executable codes to regulate LLM agents' policies. We further propose an RL-free, model-based agent "WALL-E 2.0" through the model-predictive control (MPC) framework. Unlike classical MPC requiring costly optimization on the fly, we adopt an LLM agent as an efficient look-ahead optimizer of future steps' actions by interacting with the neurosymbolic world model. While the LLM agent's strong heuristics make it an efficient planner in MPC, the quality of its planned actions is also secured by the accurate predictions of the aligned world model. They together considerably improve learning efficiency in a new environment. On open-world challenges in Mars (Minecraft like) and ALFWorld (embodied indoor environments), WALL-E 2.0 significantly outperforms existing methods, e.g., surpassing baselines in Mars by 16.1%-51.6% of success rate and by at least 61.7% in score. In ALFWorld, it achieves a new record 98% success rate after only 4 iterations.
I2VControl: Disentangled and Unified Video Motion Synthesis Control
Nov 26, 2024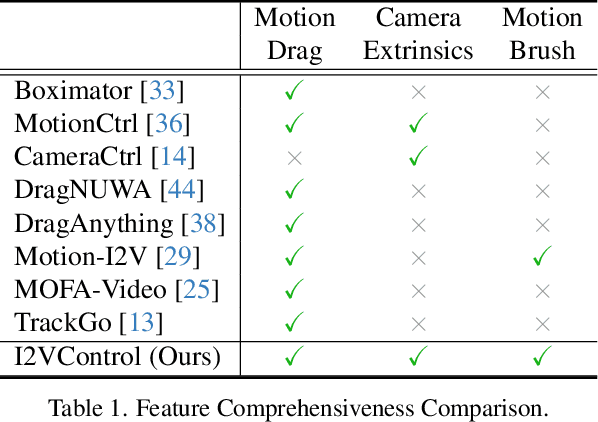
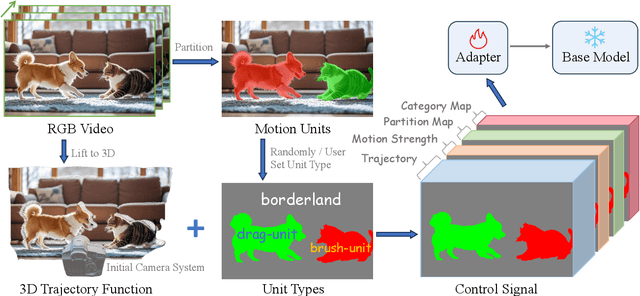
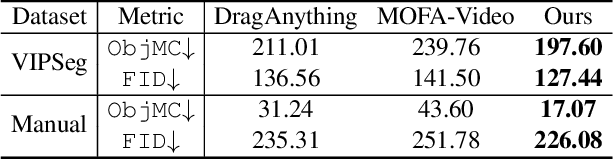

Video synthesis techniques are undergoing rapid progress, with controllability being a significant aspect of practical usability for end-users. Although text condition is an effective way to guide video synthesis, capturing the correct joint distribution between text descriptions and video motion remains a substantial challenge. In this paper, we present a disentangled and unified framework, namely I2VControl, that unifies multiple motion control tasks in image-to-video synthesis. Our approach partitions the video into individual motion units and represents each unit with disentangled control signals, which allows for various control types to be flexibly combined within our single system. Furthermore, our methodology seamlessly integrates as a plug-in for pre-trained models and remains agnostic to specific model architectures. We conduct extensive experiments, achieving excellent performance on various control tasks, and our method further facilitates user-driven creative combinations, enhancing innovation and creativity. The project page is: https://wanquanf.github.io/I2VControl .
I2VControl-Camera: Precise Video Camera Control with Adjustable Motion Strength
Nov 26, 2024

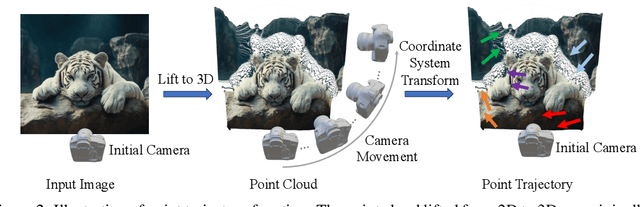
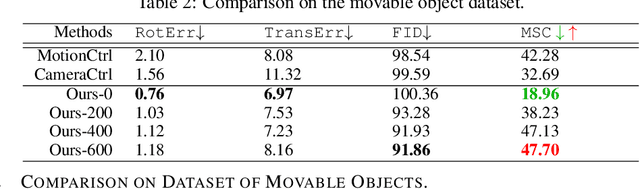
Video generation technologies are developing rapidly and have broad potential applications. Among these technologies, camera control is crucial for generating professional-quality videos that accurately meet user expectations. However, existing camera control methods still suffer from several limitations, including control precision and the neglect of the control for subject motion dynamics. In this work, we propose I2VControl-Camera, a novel camera control method that significantly enhances controllability while providing adjustability over the strength of subject motion. To improve control precision, we employ point trajectory in the camera coordinate system instead of only extrinsic matrix information as our control signal. To accurately control and adjust the strength of subject motion, we explicitly model the higher-order components of the video trajectory expansion, not merely the linear terms, and design an operator that effectively represents the motion strength. We use an adapter architecture that is independent of the base model structure. Experiments on static and dynamic scenes show that our framework outperformances previous methods both quantitatively and qualitatively. The project page is: https://wanquanf.github.io/I2VControlCamera .
Global Censored Quantile Random Forest
Oct 16, 2024



In recent years, censored quantile regression has enjoyed an increasing popularity for survival analysis while many existing works rely on linearity assumptions. In this work, we propose a Global Censored Quantile Random Forest (GCQRF) for predicting a conditional quantile process on data subject to right censoring, a forest-based flexible, competitive method able to capture complex nonlinear relationships. Taking into account the randomness in trees and connecting the proposed method to a randomized incomplete infinite degree U-process (IDUP), we quantify the prediction process' variation without assuming an infinite forest and establish its weak convergence. Moreover, feature importance ranking measures based on out-of-sample predictive accuracy are proposed. We demonstrate the superior predictive accuracy of the proposed method over a number of existing alternatives and illustrate the use of the proposed importance ranking measures on both simulated and real data.
WALL-E: World Alignment by Rule Learning Improves World Model-based LLM Agents
Oct 09, 2024



Can large language models (LLMs) directly serve as powerful world models for model-based agents? While the gaps between the prior knowledge of LLMs and the specified environment's dynamics do exist, our study reveals that the gaps can be bridged by aligning an LLM with its deployed environment and such "world alignment" can be efficiently achieved by rule learning on LLMs. Given the rich prior knowledge of LLMs, only a few additional rules suffice to align LLM predictions with the specified environment dynamics. To this end, we propose a neurosymbolic approach to learn these rules gradient-free through LLMs, by inducing, updating, and pruning rules based on comparisons of agent-explored trajectories and world model predictions. The resulting world model is composed of the LLM and the learned rules. Our embodied LLM agent "WALL-E" is built upon model-predictive control (MPC). By optimizing look-ahead actions based on the precise world model, MPC significantly improves exploration and learning efficiency. Compared to existing LLM agents, WALL-E's reasoning only requires a few principal rules rather than verbose buffered trajectories being included in the LLM input. On open-world challenges in Minecraft and ALFWorld, WALL-E achieves higher success rates than existing methods, with lower costs on replanning time and the number of tokens used for reasoning. In Minecraft, WALL-E exceeds baselines by 15-30% in success rate while costing 8-20 fewer replanning rounds and only 60-80% of tokens. In ALFWorld, its success rate surges to a new record high of 95% only after 6 iterations.