 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMask$^2$DiT: Dual Mask-based Diffusion Transformer for Multi-Scene Long Video Generation
Mar 25, 2025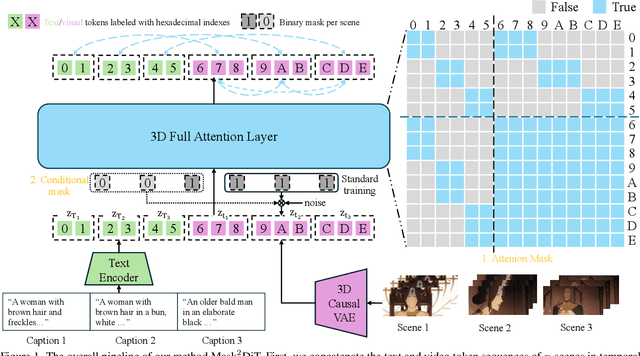

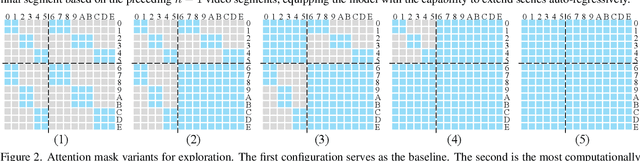
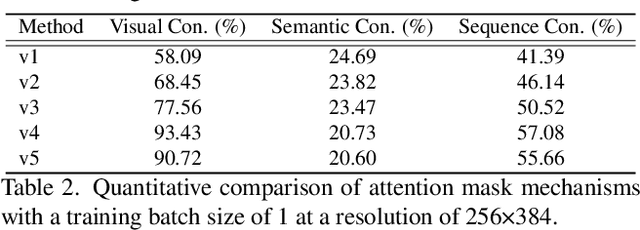
Sora has unveiled the immense potential of the Diffusion Transformer (DiT) architecture in single-scene video generation. However, the more challenging task of multi-scene video generation, which offers broader applications, remains relatively underexplored. To bridge this gap, we propose Mask$^2$DiT, a novel approach that establishes fine-grained, one-to-one alignment between video segments and their corresponding text annotations. Specifically, we introduce a symmetric binary mask at each attention layer within the DiT architecture, ensuring that each text annotation applies exclusively to its respective video segment while preserving temporal coherence across visual tokens. This attention mechanism enables precise segment-level textual-to-visual alignment, allowing the DiT architecture to effectively handle video generation tasks with a fixed number of scenes. To further equip the DiT architecture with the ability to generate additional scenes based on existing ones, we incorporate a segment-level conditional mask, which conditions each newly generated segment on the preceding video segments, thereby enabling auto-regressive scene extension. Both qualitative and quantitative experiments confirm that Mask$^2$DiT excels in maintaining visual consistency across segments while ensuring semantic alignment between each segment and its corresponding text description. Our project page is https://tianhao-qi.github.io/Mask2DiTProject.
I2VControl: Disentangled and Unified Video Motion Synthesis Control
Nov 26, 2024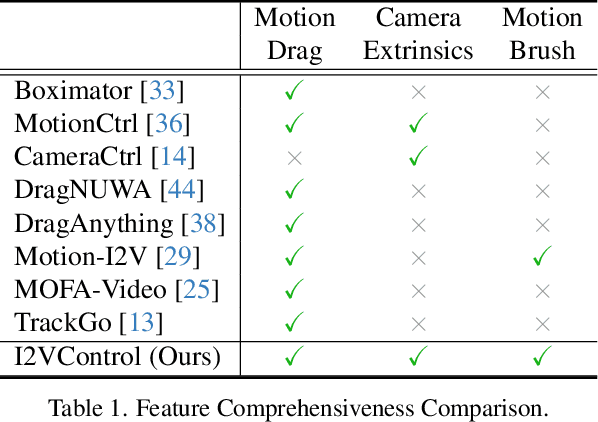
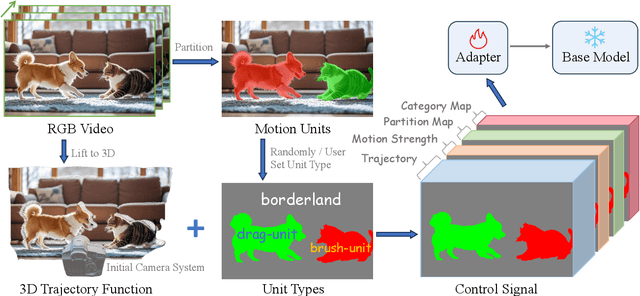
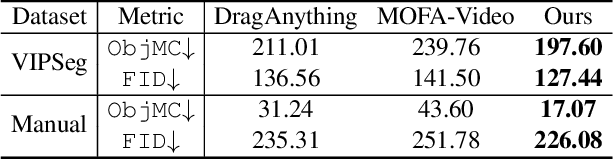

Video synthesis techniques are undergoing rapid progress, with controllability being a significant aspect of practical usability for end-users. Although text condition is an effective way to guide video synthesis, capturing the correct joint distribution between text descriptions and video motion remains a substantial challenge. In this paper, we present a disentangled and unified framework, namely I2VControl, that unifies multiple motion control tasks in image-to-video synthesis. Our approach partitions the video into individual motion units and represents each unit with disentangled control signals, which allows for various control types to be flexibly combined within our single system. Furthermore, our methodology seamlessly integrates as a plug-in for pre-trained models and remains agnostic to specific model architectures. We conduct extensive experiments, achieving excellent performance on various control tasks, and our method further facilitates user-driven creative combinations, enhancing innovation and creativity. The project page is: https://wanquanf.github.io/I2VControl .
I2VControl-Camera: Precise Video Camera Control with Adjustable Motion Strength
Nov 26, 2024

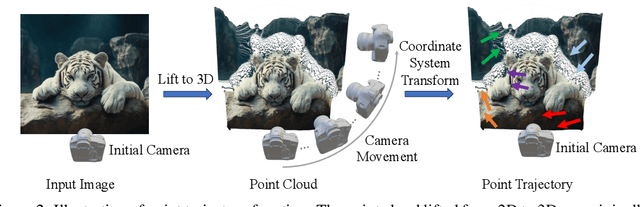
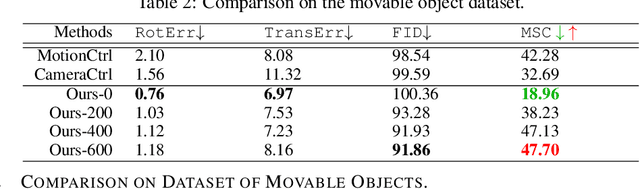
Video generation technologies are developing rapidly and have broad potential applications. Among these technologies, camera control is crucial for generating professional-quality videos that accurately meet user expectations. However, existing camera control methods still suffer from several limitations, including control precision and the neglect of the control for subject motion dynamics. In this work, we propose I2VControl-Camera, a novel camera control method that significantly enhances controllability while providing adjustability over the strength of subject motion. To improve control precision, we employ point trajectory in the camera coordinate system instead of only extrinsic matrix information as our control signal. To accurately control and adjust the strength of subject motion, we explicitly model the higher-order components of the video trajectory expansion, not merely the linear terms, and design an operator that effectively represents the motion strength. We use an adapter architecture that is independent of the base model structure. Experiments on static and dynamic scenes show that our framework outperformances previous methods both quantitatively and qualitatively. The project page is: https://wanquanf.github.io/I2VControlCamera .
DEADiff: An Efficient Stylization Diffusion Model with Disentangled Representations
Mar 12, 2024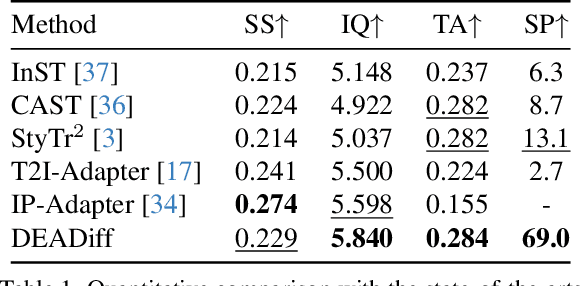
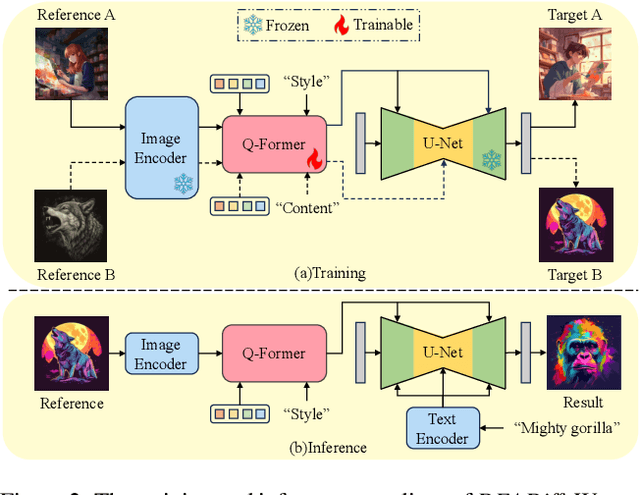
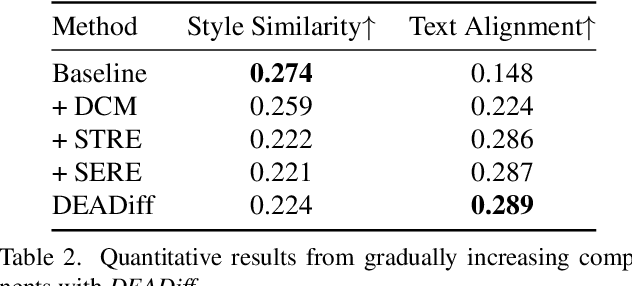
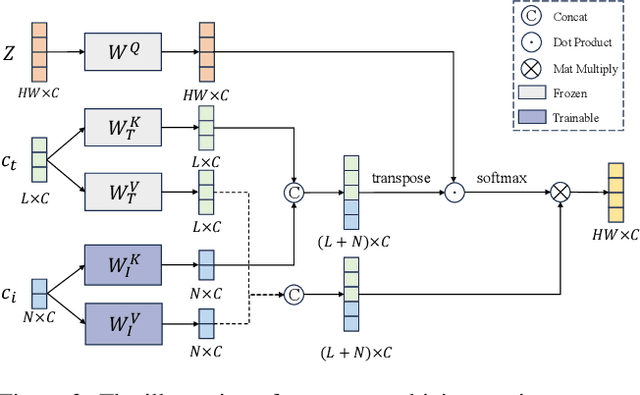
The diffusion-based text-to-image model harbors immense potential in transferring reference style. However, current encoder-based approaches significantly impair the text controllability of text-to-image models while transferring styles. In this paper, we introduce DEADiff to address this issue using the following two strategies: 1) a mechanism to decouple the style and semantics of reference images. The decoupled feature representations are first extracted by Q-Formers which are instructed by different text descriptions. Then they are injected into mutually exclusive subsets of cross-attention layers for better disentanglement. 2) A non-reconstructive learning method. The Q-Formers are trained using paired images rather than the identical target, in which the reference image and the ground-truth image are with the same style or semantics. We show that DEADiff attains the best visual stylization results and optimal balance between the text controllability inherent in the text-to-image model and style similarity to the reference image, as demonstrated both quantitatively and qualitatively. Our project page is https://tianhao-qi.github.io/DEADiff/.
Balanced Classification: A Unified Framework for Long-Tailed Object Detection
Aug 04, 2023Conventional detectors suffer from performance degradation when dealing with long-tailed data due to a classification bias towards the majority head categories. In this paper, we contend that the learning bias originates from two factors: 1) the unequal competition arising from the imbalanced distribution of foreground categories, and 2) the lack of sample diversity in tail categories. To tackle these issues, we introduce a unified framework called BAlanced CLassification (BACL), which enables adaptive rectification of inequalities caused by disparities in category distribution and dynamic intensification of sample diversities in a synchronized manner. Specifically, a novel foreground classification balance loss (FCBL) is developed to ameliorate the domination of head categories and shift attention to difficult-to-differentiate categories by introducing pairwise class-aware margins and auto-adjusted weight terms, respectively. This loss prevents the over-suppression of tail categories in the context of unequal competition. Moreover, we propose a dynamic feature hallucination module (FHM), which enhances the representation of tail categories in the feature space by synthesizing hallucinated samples to introduce additional data variances. In this divide-and-conquer approach, BACL sets a new state-of-the-art on the challenging LVIS benchmark with a decoupled training pipeline, surpassing vanilla Faster R-CNN with ResNet-50-FPN by 5.8% AP and 16.1% AP for overall and tail categories. Extensive experiments demonstrate that BACL consistently achieves performance improvements across various datasets with different backbones and architectures. Code and models are available at https://github.com/Tianhao-Qi/BACL.