 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMask$^2$DiT: Dual Mask-based Diffusion Transformer for Multi-Scene Long Video Generation
Paper and Code
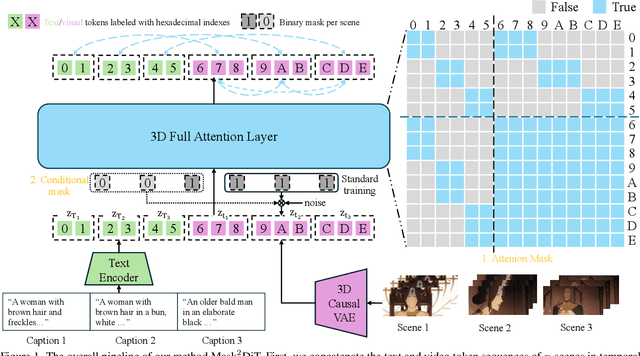

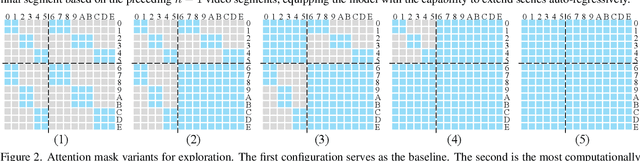
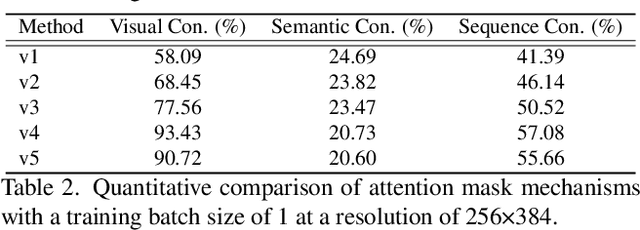
Sora has unveiled the immense potential of the Diffusion Transformer (DiT) architecture in single-scene video generation. However, the more challenging task of multi-scene video generation, which offers broader applications, remains relatively underexplored. To bridge this gap, we propose Mask$^2$DiT, a novel approach that establishes fine-grained, one-to-one alignment between video segments and their corresponding text annotations. Specifically, we introduce a symmetric binary mask at each attention layer within the DiT architecture, ensuring that each text annotation applies exclusively to its respective video segment while preserving temporal coherence across visual tokens. This attention mechanism enables precise segment-level textual-to-visual alignment, allowing the DiT architecture to effectively handle video generation tasks with a fixed number of scenes. To further equip the DiT architecture with the ability to generate additional scenes based on existing ones, we incorporate a segment-level conditional mask, which conditions each newly generated segment on the preceding video segments, thereby enabling auto-regressive scene extension. Both qualitative and quantitative experiments confirm that Mask$^2$DiT excels in maintaining visual consistency across segments while ensuring semantic alignment between each segment and its corresponding text description. Our project page is https://tianhao-qi.github.io/Mask2DiTProject.