 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrame-Level Captions for Long Video Generation with Complex Multi Scenes
May 27, 2025Generating long videos that can show complex stories, like movie scenes from scripts, has great promise and offers much more than short clips. However, current methods that use autoregression with diffusion models often struggle because their step-by-step process naturally leads to a serious error accumulation (drift). Also, many existing ways to make long videos focus on single, continuous scenes, making them less useful for stories with many events and changes. This paper introduces a new approach to solve these problems. First, we propose a novel way to annotate datasets at the frame-level, providing detailed text guidance needed for making complex, multi-scene long videos. This detailed guidance works with a Frame-Level Attention Mechanism to make sure text and video match precisely. A key feature is that each part (frame) within these windows can be guided by its own distinct text prompt. Our training uses Diffusion Forcing to provide the model with the ability to handle time flexibly. We tested our approach on difficult VBench 2.0 benchmarks ("Complex Plots" and "Complex Landscapes") based on the WanX2.1-T2V-1.3B model. The results show our method is better at following instructions in complex, changing scenes and creates high-quality long videos. We plan to share our dataset annotation methods and trained models with the research community. Project page: https://zgctroy.github.io/frame-level-captions .
Generative Pre-trained Autoregressive Diffusion Transformer
May 15, 2025In this work, we present GPDiT, a Generative Pre-trained Autoregressive Diffusion Transformer that unifies the strengths of diffusion and autoregressive modeling for long-range video synthesis, within a continuous latent space. Instead of predicting discrete tokens, GPDiT autoregressively predicts future latent frames using a diffusion loss, enabling natural modeling of motion dynamics and semantic consistency across frames. This continuous autoregressive framework not only enhances generation quality but also endows the model with representation capabilities. Additionally, we introduce a lightweight causal attention variant and a parameter-free rotation-based time-conditioning mechanism, improving both the training and inference efficiency. Extensive experiments demonstrate that GPDiT achieves strong performance in video generation quality, video representation ability, and few-shot learning tasks, highlighting its potential as an effective framework for video modeling in continuous space.
STORYANCHORS: Generating Consistent Multi-Scene Story Frames for Long-Form Narratives
May 13, 2025This paper introduces StoryAnchors, a unified framework for generating high-quality, multi-scene story frames with strong temporal consistency. The framework employs a bidirectional story generator that integrates both past and future contexts to ensure temporal consistency, character continuity, and smooth scene transitions throughout the narrative. Specific conditions are introduced to distinguish story frame generation from standard video synthesis, facilitating greater scene diversity and enhancing narrative richness. To further improve generation quality, StoryAnchors integrates Multi-Event Story Frame Labeling and Progressive Story Frame Training, enabling the model to capture both overarching narrative flow and event-level dynamics. This approach supports the creation of editable and expandable story frames, allowing for manual modifications and the generation of longer, more complex sequences. Extensive experiments show that StoryAnchors outperforms existing open-source models in key areas such as consistency, narrative coherence, and scene diversity. Its performance in narrative consistency and story richness is also on par with GPT-4o. Ultimately, StoryAnchors pushes the boundaries of story-driven frame generation, offering a scalable, flexible, and highly editable foundation for future research.
Mask$^2$DiT: Dual Mask-based Diffusion Transformer for Multi-Scene Long Video Generation
Mar 25, 2025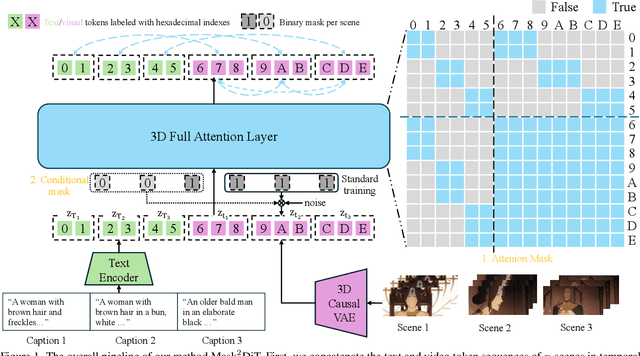

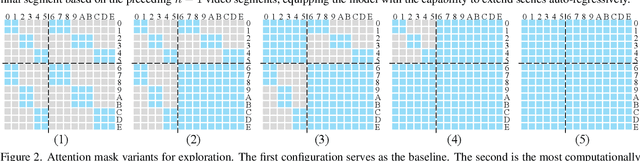
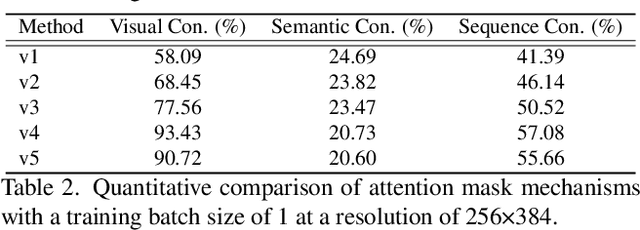
Sora has unveiled the immense potential of the Diffusion Transformer (DiT) architecture in single-scene video generation. However, the more challenging task of multi-scene video generation, which offers broader applications, remains relatively underexplored. To bridge this gap, we propose Mask$^2$DiT, a novel approach that establishes fine-grained, one-to-one alignment between video segments and their corresponding text annotations. Specifically, we introduce a symmetric binary mask at each attention layer within the DiT architecture, ensuring that each text annotation applies exclusively to its respective video segment while preserving temporal coherence across visual tokens. This attention mechanism enables precise segment-level textual-to-visual alignment, allowing the DiT architecture to effectively handle video generation tasks with a fixed number of scenes. To further equip the DiT architecture with the ability to generate additional scenes based on existing ones, we incorporate a segment-level conditional mask, which conditions each newly generated segment on the preceding video segments, thereby enabling auto-regressive scene extension. Both qualitative and quantitative experiments confirm that Mask$^2$DiT excels in maintaining visual consistency across segments while ensuring semantic alignment between each segment and its corresponding text description. Our project page is https://tianhao-qi.github.io/Mask2DiTProject.
Step-Video-TI2V Technical Report: A State-of-the-Art Text-Driven Image-to-Video Generation Model
Mar 14, 2025We present Step-Video-TI2V, a state-of-the-art text-driven image-to-video generation model with 30B parameters, capable of generating videos up to 102 frames based on both text and image inputs. We build Step-Video-TI2V-Eval as a new benchmark for the text-driven image-to-video task and compare Step-Video-TI2V with open-source and commercial TI2V engines using this dataset. Experimental results demonstrate the state-of-the-art performance of Step-Video-TI2V in the image-to-video generation task. Both Step-Video-TI2V and Step-Video-TI2V-Eval are available at https://github.com/stepfun-ai/Step-Video-TI2V.
MovieDreamer: Hierarchical Generation for Coherent Long Visual Sequence
Jul 23, 2024



Recent advancements in video generation have primarily leveraged diffusion models for short-duration content. However, these approaches often fall short in modeling complex narratives and maintaining character consistency over extended periods, which is essential for long-form video production like movies. We propose MovieDreamer, a novel hierarchical framework that integrates the strengths of autoregressive models with diffusion-based rendering to pioneer long-duration video generation with intricate plot progressions and high visual fidelity. Our approach utilizes autoregressive models for global narrative coherence, predicting sequences of visual tokens that are subsequently transformed into high-quality video frames through diffusion rendering. This method is akin to traditional movie production processes, where complex stories are factorized down into manageable scene capturing. Further, we employ a multimodal script that enriches scene descriptions with detailed character information and visual style, enhancing continuity and character identity across scenes. We present extensive experiments across various movie genres, demonstrating that our approach not only achieves superior visual and narrative quality but also effectively extends the duration of generated content significantly beyond current capabilities. Homepage: https://aim-uofa.github.io/MovieDreamer/.
Viewpoint Integration and Registration with Vision Language Foundation Model for Image Change Understanding
Sep 15, 2023



Recently, the development of pre-trained vision language foundation models (VLFMs) has led to remarkable performance in many tasks. However, these models tend to have strong single-image understanding capability but lack the ability to understand multiple images. Therefore, they cannot be directly applied to cope with image change understanding (ICU), which requires models to capture actual changes between multiple images and describe them in language. In this paper, we discover that existing VLFMs perform poorly when applied directly to ICU because of the following problems: (1) VLFMs generally learn the global representation of a single image, while ICU requires capturing nuances between multiple images. (2) The ICU performance of VLFMs is significantly affected by viewpoint variations, which is caused by the altered relationships between objects when viewpoint changes. To address these problems, we propose a Viewpoint Integration and Registration method. Concretely, we introduce a fused adapter image encoder that fine-tunes pre-trained encoders by inserting designed trainable adapters and fused adapters, to effectively capture nuances between image pairs. Additionally, a viewpoint registration flow and a semantic emphasizing module are designed to reduce the performance degradation caused by viewpoint variations in the visual and semantic space, respectively. Experimental results on CLEVR-Change and Spot-the-Diff demonstrate that our method achieves state-of-the-art performance in all metrics.
RSGPT: A Remote Sensing Vision Language Model and Benchmark
Jul 28, 2023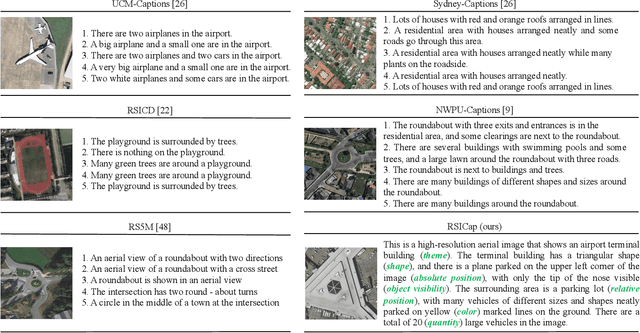



The emergence of large-scale large language models, with GPT-4 as a prominent example, has significantly propelled the rapid advancement of artificial general intelligence and sparked the revolution of Artificial Intelligence 2.0. In the realm of remote sensing (RS), there is a growing interest in developing large vision language models (VLMs) specifically tailored for data analysis in this domain. However, current research predominantly revolves around visual recognition tasks, lacking comprehensive, large-scale image-text datasets that are aligned and suitable for training large VLMs, which poses significant challenges to effectively training such models for RS applications. In computer vision, recent research has demonstrated that fine-tuning large vision language models on small-scale, high-quality datasets can yield impressive performance in visual and language understanding. These results are comparable to state-of-the-art VLMs trained from scratch on massive amounts of data, such as GPT-4. Inspired by this captivating idea, in this work, we build a high-quality Remote Sensing Image Captioning dataset (RSICap) that facilitates the development of large VLMs in the RS field. Unlike previous RS datasets that either employ model-generated captions or short descriptions, RSICap comprises 2,585 human-annotated captions with rich and high-quality information. This dataset offers detailed descriptions for each image, encompassing scene descriptions (e.g., residential area, airport, or farmland) as well as object information (e.g., color, shape, quantity, absolute position, etc). To facilitate the evaluation of VLMs in the field of RS, we also provide a benchmark evaluation dataset called RSIEval. This dataset consists of human-annotated captions and visual question-answer pairs, allowing for a comprehensive assessment of VLMs in the context of RS.
UniNeXt: Exploring A Unified Architecture for Vision Recognition
May 01, 2023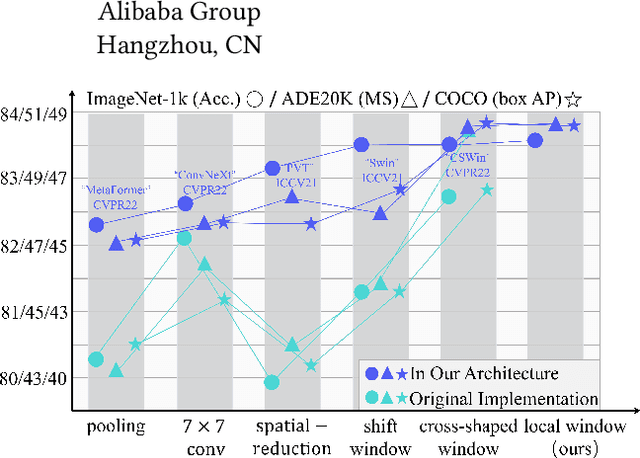

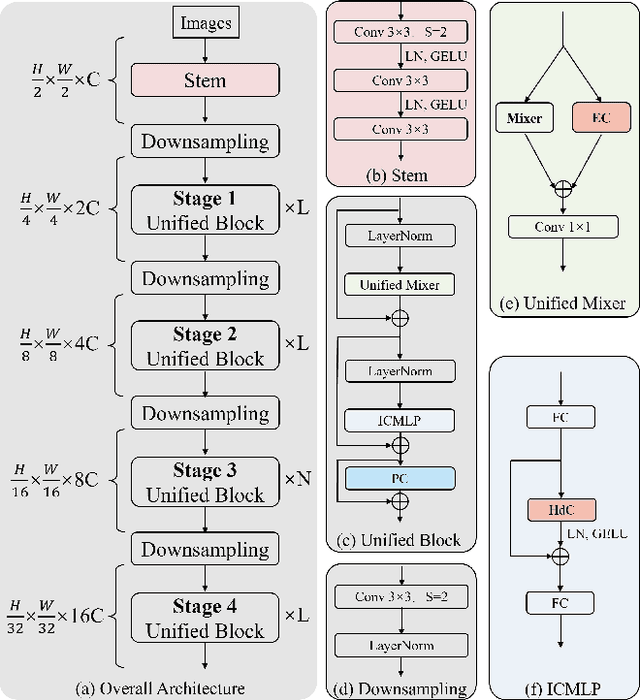

Vision Transformers have shown great potential in computer vision tasks. Most recent works have focused on elaborating the spatial token mixer for performance gains. However, we observe that a well-designed general architecture can significantly improve the performance of the entire backbone, regardless of which spatial token mixer is equipped. In this paper, we propose UniNeXt, an improved general architecture for the vision backbone. To verify its effectiveness, we instantiate the spatial token mixer with various typical and modern designs, including both convolution and attention modules. Compared with the architecture in which they are first proposed, our UniNeXt architecture can steadily boost the performance of all the spatial token mixers, and narrows the performance gap among them. Surprisingly, our UniNeXt equipped with naive local window attention even outperforms the previous state-of-the-art. Interestingly, the ranking of these spatial token mixers also changes under our UniNeXt, suggesting that an excellent spatial token mixer may be stifled due to a suboptimal general architecture, which further shows the importance of the study on the general architecture of vision backbone. All models and codes will be publicly available.
Foundation Model Drives Weakly Incremental Learning for Semantic Segmentation
Feb 28, 2023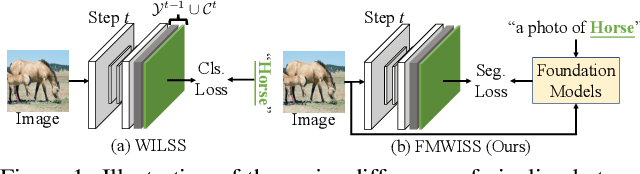
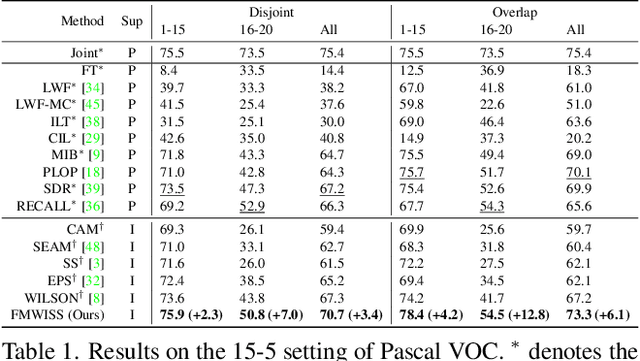
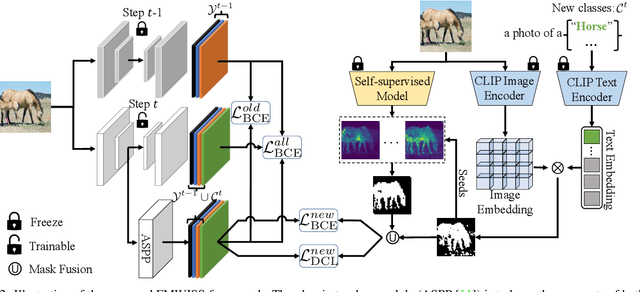
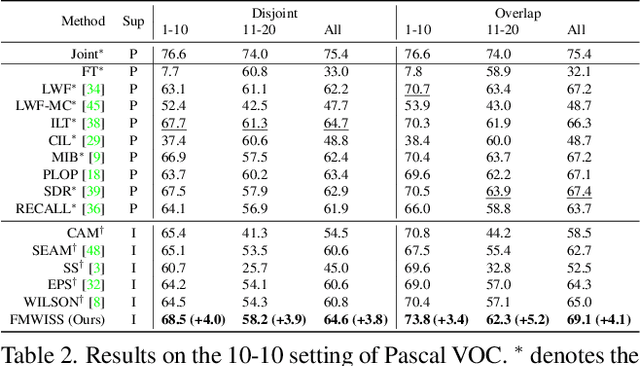
Modern incremental learning for semantic segmentation methods usually learn new categories based on dense annotations. Although achieve promising results, pixel-by-pixel labeling is costly and time-consuming. Weakly incremental learning for semantic segmentation (WILSS) is a novel and attractive task, which aims at learning to segment new classes from cheap and widely available image-level labels. Despite the comparable results, the image-level labels can not provide details to locate each segment, which limits the performance of WILSS. This inspires us to think how to improve and effectively utilize the supervision of new classes given image-level labels while avoiding forgetting old ones. In this work, we propose a novel and data-efficient framework for WILSS, named FMWISS. Specifically, we propose pre-training based co-segmentation to distill the knowledge of complementary foundation models for generating dense pseudo labels. We further optimize the noisy pseudo masks with a teacher-student architecture, where a plug-in teacher is optimized with a proposed dense contrastive loss. Moreover, we introduce memory-based copy-paste augmentation to improve the catastrophic forgetting problem of old classes. Extensive experiments on Pascal VOC and COCO datasets demonstrate the superior performance of our framework, e.g., FMWISS achieves 70.7% and 73.3% in the 15-5 VOC setting, outperforming the state-of-the-art method by 3.4% and 6.1%, respectively.