 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLumosX: Relate Any Identities with Their Attributes for Personalized Video Generation
Mar 20, 2026Recent advances in diffusion models have significantly improved text-to-video generation, enabling personalized content creation with fine-grained control over both foreground and background elements. However, precise face-attribute alignment across subjects remains challenging, as existing methods lack explicit mechanisms to ensure intra-group consistency. Addressing this gap requires both explicit modeling strategies and face-attribute-aware data resources. We therefore propose LumosX, a framework that advances both data and model design. On the data side, a tailored collection pipeline orchestrates captions and visual cues from independent videos, while multimodal large language models (MLLMs) infer and assign subject-specific dependencies. These extracted relational priors impose a finer-grained structure that amplifies the expressive control of personalized video generation and enables the construction of a comprehensive benchmark. On the modeling side, Relational Self-Attention and Relational Cross-Attention intertwine position-aware embeddings with refined attention dynamics to inscribe explicit subject-attribute dependencies, enforcing disciplined intra-group cohesion and amplifying the separation between distinct subject clusters. Comprehensive evaluations on our benchmark demonstrate that LumosX achieves state-of-the-art performance in fine-grained, identity-consistent, and semantically aligned personalized multi-subject video generation. Code and models are available at https://jiazheng-xing.github.io/lumosx-home/.
Viewpoint Integration and Registration with Vision Language Foundation Model for Image Change Understanding
Sep 15, 2023



Recently, the development of pre-trained vision language foundation models (VLFMs) has led to remarkable performance in many tasks. However, these models tend to have strong single-image understanding capability but lack the ability to understand multiple images. Therefore, they cannot be directly applied to cope with image change understanding (ICU), which requires models to capture actual changes between multiple images and describe them in language. In this paper, we discover that existing VLFMs perform poorly when applied directly to ICU because of the following problems: (1) VLFMs generally learn the global representation of a single image, while ICU requires capturing nuances between multiple images. (2) The ICU performance of VLFMs is significantly affected by viewpoint variations, which is caused by the altered relationships between objects when viewpoint changes. To address these problems, we propose a Viewpoint Integration and Registration method. Concretely, we introduce a fused adapter image encoder that fine-tunes pre-trained encoders by inserting designed trainable adapters and fused adapters, to effectively capture nuances between image pairs. Additionally, a viewpoint registration flow and a semantic emphasizing module are designed to reduce the performance degradation caused by viewpoint variations in the visual and semantic space, respectively. Experimental results on CLEVR-Change and Spot-the-Diff demonstrate that our method achieves state-of-the-art performance in all metrics.
HMANet: Hybrid Multiple Attention Network for Semantic Segmentation in Aerial Images
Jan 09, 2020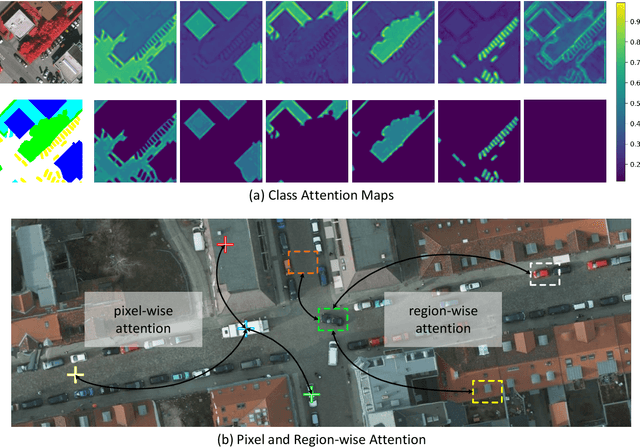
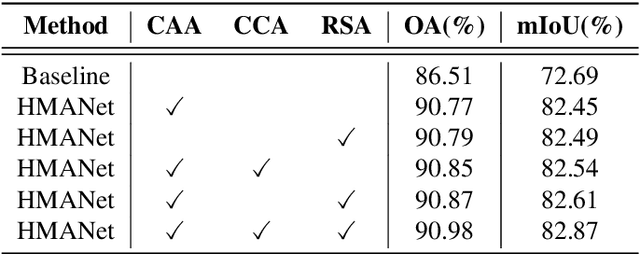
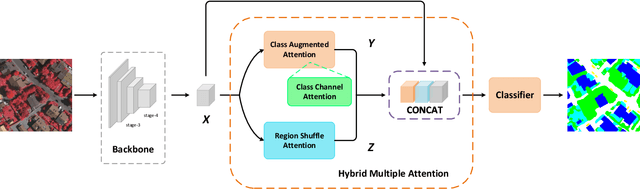
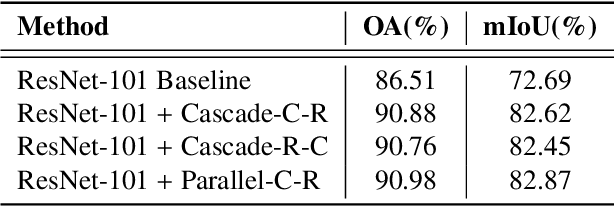
Semantic segmentation in very high resolution (VHR) aerial images is one of the most challenging tasks in remote sensing image understanding. Most of the current approaches are based on deep convolutional neural networks (DCNNs) for its remarkable ability of feature representations. Specifically, attention-based methods can effectively capture long-range dependencies and further reconstruct the feature maps for better representation. However, limited by the mere perspective of spacial and channel attention and huge computation complexity of self-attention mechanism, it's unlikely to model the effective semantic interdependencies between each pixel-pair. In this work, we propose a novel attention-based framework named Hybrid Multiple Attention Network (HMANet) to adaptively capture global correlations from the perspective of space, channel and category in a more effective and efficient manner. Concretely, a class augmented attention (CAA) module embedded with a class channel attention (CCA) module can be used to compute category-based correlation and recalibrate the class-level information. Additionally, we introduce a simple yet region shuffle attention (RSA) module to reduce feature redundant and improve the efficiency of self-attention mechanism via region-wise representations. Extensive experimental results on the ISPRS Vaihingen and Potsdam benchmark demonstrate the effectiveness and efficiency of our HMANet over other state-of-the-art methods.