 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSetPO: Set-Level Policy Optimization for Diversity-Preserving LLM Reasoning
Feb 01, 2026Reinforcement learning with verifiable rewards has shown notable effectiveness in enhancing large language models (LLMs) reasoning performance, especially in mathematics tasks. However, such improvements often come with reduced outcome diversity, where the model concentrates probability mass on a narrow set of solutions. Motivated by diminishing-returns principles, we introduce a set level diversity objective defined over sampled trajectories using kernelized similarity. Our approach derives a leave-one-out marginal contribution for each sampled trajectory and integrates this objective as a plug-in advantage shaping term for policy optimization. We further investigate the contribution of a single trajectory to language model diversity within a distribution perturbation framework. This analysis theoretically confirms a monotonicity property, proving that rarer trajectories yield consistently higher marginal contributions to the global diversity. Extensive experiments across a range of model scales demonstrate the effectiveness of our proposed algorithm, consistently outperforming strong baselines in both Pass@1 and Pass@K across various benchmarks.
Frame-Level Captions for Long Video Generation with Complex Multi Scenes
May 27, 2025Generating long videos that can show complex stories, like movie scenes from scripts, has great promise and offers much more than short clips. However, current methods that use autoregression with diffusion models often struggle because their step-by-step process naturally leads to a serious error accumulation (drift). Also, many existing ways to make long videos focus on single, continuous scenes, making them less useful for stories with many events and changes. This paper introduces a new approach to solve these problems. First, we propose a novel way to annotate datasets at the frame-level, providing detailed text guidance needed for making complex, multi-scene long videos. This detailed guidance works with a Frame-Level Attention Mechanism to make sure text and video match precisely. A key feature is that each part (frame) within these windows can be guided by its own distinct text prompt. Our training uses Diffusion Forcing to provide the model with the ability to handle time flexibly. We tested our approach on difficult VBench 2.0 benchmarks ("Complex Plots" and "Complex Landscapes") based on the WanX2.1-T2V-1.3B model. The results show our method is better at following instructions in complex, changing scenes and creates high-quality long videos. We plan to share our dataset annotation methods and trained models with the research community. Project page: https://zgctroy.github.io/frame-level-captions .
Generative Pre-trained Autoregressive Diffusion Transformer
May 15, 2025In this work, we present GPDiT, a Generative Pre-trained Autoregressive Diffusion Transformer that unifies the strengths of diffusion and autoregressive modeling for long-range video synthesis, within a continuous latent space. Instead of predicting discrete tokens, GPDiT autoregressively predicts future latent frames using a diffusion loss, enabling natural modeling of motion dynamics and semantic consistency across frames. This continuous autoregressive framework not only enhances generation quality but also endows the model with representation capabilities. Additionally, we introduce a lightweight causal attention variant and a parameter-free rotation-based time-conditioning mechanism, improving both the training and inference efficiency. Extensive experiments demonstrate that GPDiT achieves strong performance in video generation quality, video representation ability, and few-shot learning tasks, highlighting its potential as an effective framework for video modeling in continuous space.
STORYANCHORS: Generating Consistent Multi-Scene Story Frames for Long-Form Narratives
May 13, 2025This paper introduces StoryAnchors, a unified framework for generating high-quality, multi-scene story frames with strong temporal consistency. The framework employs a bidirectional story generator that integrates both past and future contexts to ensure temporal consistency, character continuity, and smooth scene transitions throughout the narrative. Specific conditions are introduced to distinguish story frame generation from standard video synthesis, facilitating greater scene diversity and enhancing narrative richness. To further improve generation quality, StoryAnchors integrates Multi-Event Story Frame Labeling and Progressive Story Frame Training, enabling the model to capture both overarching narrative flow and event-level dynamics. This approach supports the creation of editable and expandable story frames, allowing for manual modifications and the generation of longer, more complex sequences. Extensive experiments show that StoryAnchors outperforms existing open-source models in key areas such as consistency, narrative coherence, and scene diversity. Its performance in narrative consistency and story richness is also on par with GPT-4o. Ultimately, StoryAnchors pushes the boundaries of story-driven frame generation, offering a scalable, flexible, and highly editable foundation for future research.
Step-Video-TI2V Technical Report: A State-of-the-Art Text-Driven Image-to-Video Generation Model
Mar 14, 2025We present Step-Video-TI2V, a state-of-the-art text-driven image-to-video generation model with 30B parameters, capable of generating videos up to 102 frames based on both text and image inputs. We build Step-Video-TI2V-Eval as a new benchmark for the text-driven image-to-video task and compare Step-Video-TI2V with open-source and commercial TI2V engines using this dataset. Experimental results demonstrate the state-of-the-art performance of Step-Video-TI2V in the image-to-video generation task. Both Step-Video-TI2V and Step-Video-TI2V-Eval are available at https://github.com/stepfun-ai/Step-Video-TI2V.
DSV: Exploiting Dynamic Sparsity to Accelerate Large-Scale Video DiT Training
Feb 11, 2025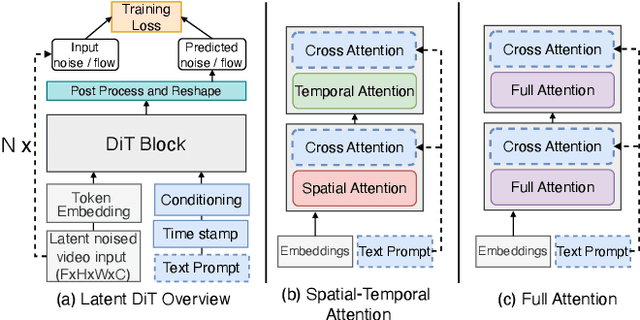

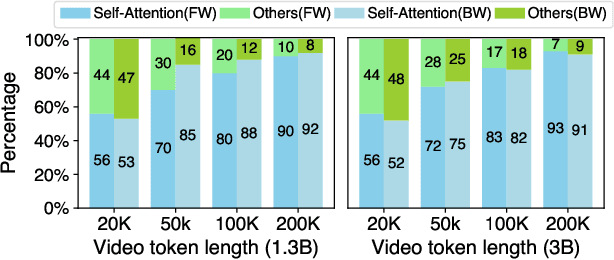
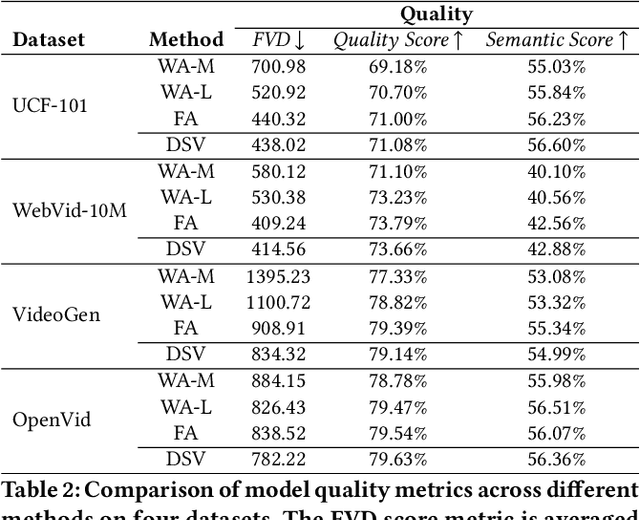
Diffusion Transformers (DiTs) have shown remarkable performance in modeling and generating high-quality videos. However, the quadratic computational complexity of 3D full attention mechanism presents significant challenges in scaling video DiT training, especially for high-definition and lengthy videos, where attention can dominate up to 95% of the end-to-end time and necessitate specialized communication paradigms to handle large input sizes. This paper introduces DSV, a novel framework designed to accelerate and scale the training of video DiTs by leveraging the inherent dynamic attention sparsity throughout the training process. DSV employs a two-stage training algorithm that exploits sparsity patterns, focusing on critical elements supported by efficient, tailored kernels. To accommodate the new sparsity dimension, we develop a hybrid sparsity-aware context parallelism that effectively scales to large inputs by addressing the heterogeneity of sparsity across attention heads and blocks, resulting in optimized sparse computation and communication. Extensive evaluations demonstrate that DSV achieves up to 3.02x gain in training throughput with nearly no quality degradation.
Taming Teacher Forcing for Masked Autoregressive Video Generation
Jan 21, 2025



We introduce MAGI, a hybrid video generation framework that combines masked modeling for intra-frame generation with causal modeling for next-frame generation. Our key innovation, Complete Teacher Forcing (CTF), conditions masked frames on complete observation frames rather than masked ones (namely Masked Teacher Forcing, MTF), enabling a smooth transition from token-level (patch-level) to frame-level autoregressive generation. CTF significantly outperforms MTF, achieving a +23% improvement in FVD scores on first-frame conditioned video prediction. To address issues like exposure bias, we employ targeted training strategies, setting a new benchmark in autoregressive video generation. Experiments show that MAGI can generate long, coherent video sequences exceeding 100 frames, even when trained on as few as 16 frames, highlighting its potential for scalable, high-quality video generation.
Automated Proof Generation for Rust Code via Self-Evolution
Oct 21, 2024



Ensuring correctness is crucial for code generation. Formal verification offers a definitive assurance of correctness, but demands substantial human effort in proof construction and hence raises a pressing need for automation. The primary obstacle lies in the severe lack of data - there is much less proof than code for LLMs to train upon. In this paper, we introduce SAFE, a novel framework that overcomes the lack of human-written proof to enable automated proof generation of Rust code. SAFE establishes a self-evolving cycle where data synthesis and fine-tuning collaborate to enhance the model capability, leveraging the definitive power of a symbolic verifier in telling correct proof from incorrect ones. SAFE also re-purposes the large number of synthesized incorrect proofs to train the self-debugging capability of the fine-tuned models, empowering them to fix incorrect proofs based on the verifier's feedback. SAFE demonstrates superior efficiency and precision compared to GPT-4o. Through tens of thousands of synthesized proofs and the self-debugging mechanism, we improve the capability of open-source models, initially unacquainted with formal verification, to automatically write proof for Rust code. This advancement leads to a significant improvement in performance, achieving a 70.50% accuracy rate in a benchmark crafted by human experts, a significant leap over GPT-4o's performance of 24.46%.
Alchemy: Amplifying Theorem-Proving Capability through Symbolic Mutation
Oct 21, 2024



Formal proofs are challenging to write even for experienced experts. Recent progress in Neural Theorem Proving (NTP) shows promise in expediting this process. However, the formal corpora available on the Internet are limited compared to the general text, posing a significant data scarcity challenge for NTP. To address this issue, this work proposes Alchemy, a general framework for data synthesis that constructs formal theorems through symbolic mutation. Specifically, for each candidate theorem in Mathlib, we identify all invocable theorems that can be used to rewrite or apply to it. Subsequently, we mutate the candidate theorem by replacing the corresponding term in the statement with its equivalent form or antecedent. As a result, our method increases the number of theorems in Mathlib by an order of magnitude, from 110k to 6M. Furthermore, we perform continual pretraining and supervised finetuning on this augmented corpus for large language models. Experimental results demonstrate the effectiveness of our approach, achieving a 5% absolute performance improvement on Leandojo benchmark. Additionally, our synthetic data achieve a 2.5% absolute performance gain on the out-of-distribution miniF2F benchmark. To provide further insights, we conduct a comprehensive analysis of synthetic data composition and the training paradigm, offering valuable guidance for developing a strong theorem prover.
AutoDirector: Online Auto-scheduling Agents for Multi-sensory Composition
Aug 21, 2024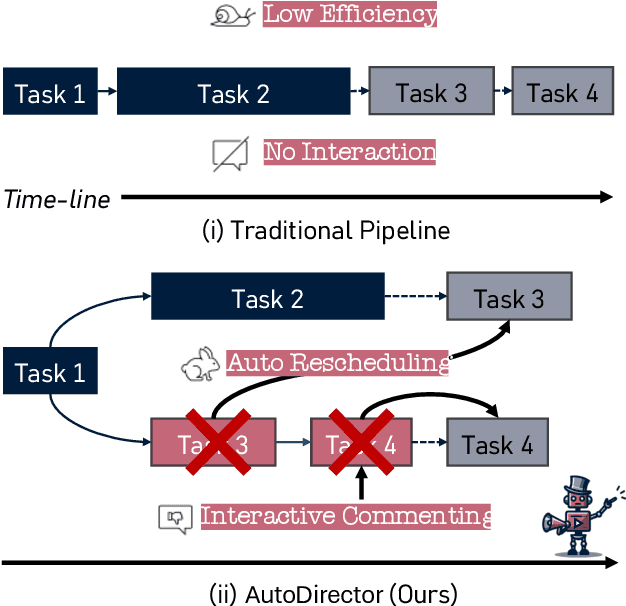

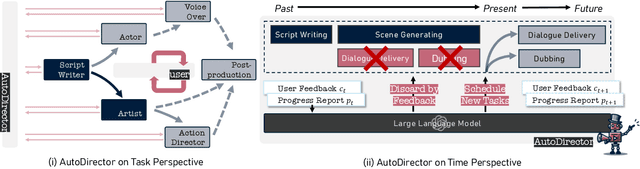

With the advancement of generative models, the synthesis of different sensory elements such as music, visuals, and speech has achieved significant realism. However, the approach to generate multi-sensory outputs has not been fully explored, limiting the application on high-value scenarios such as of directing a film. Developing a movie director agent faces two major challenges: (1) Lack of parallelism and online scheduling with production steps: In the production of multi-sensory films, there are complex dependencies between different sensory elements, and the production time for each element varies. (2) Diverse needs and clear communication demands with users: Users often cannot clearly express their needs until they see a draft, which requires human-computer interaction and iteration to continually adjust and optimize the film content based on user feedback. To address these issues, we introduce AutoDirector, an interactive multi-sensory composition framework that supports long shots, special effects, music scoring, dubbing, and lip-syncing. This framework improves the efficiency of multi-sensory film production through automatic scheduling and supports the modification and improvement of interactive tasks to meet user needs. AutoDirector not only expands the application scope of human-machine collaboration but also demonstrates the potential of AI in collaborating with humans in the role of a film director to complete multi-sensory films.