 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePRISM: Parametrically Refactoring Inference for Speculative Sampling Draft Models
Feb 02, 2026Large Language Models (LLMs), constrained by their auto-regressive nature, suffer from slow decoding. Speculative decoding methods have emerged as a promising solution to accelerate LLM decoding, attracting attention from both systems and AI research communities. Recently, the pursuit of better draft quality has driven a trend toward parametrically larger draft models, which inevitably introduces substantial computational overhead. While existing work attempts to balance the trade-off between prediction accuracy and compute latency, we address this fundamental dilemma through architectural innovation. We propose PRISM, which disaggregates the computation of each predictive step across different parameter sets, refactoring the computational pathways of draft models to successfully decouple model capacity from inference cost. Through extensive experiments, we demonstrate that PRISM outperforms all existing draft architectures, achieving exceptional acceptance lengths while maintaining minimal draft latency for superior end-to-end speedup. We also re-examine scaling laws with PRISM, revealing that PRISM scales more effectively with expanding data volumes than other draft architectures. Through rigorous and fair comparison, we show that PRISM boosts the decoding throughput of an already highly optimized inference engine by more than 2.6x.
DSV: Exploiting Dynamic Sparsity to Accelerate Large-Scale Video DiT Training
Feb 11, 2025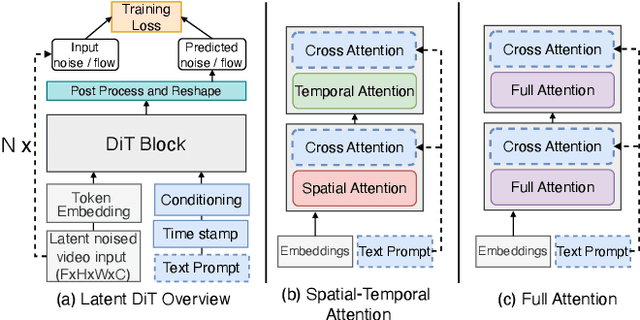

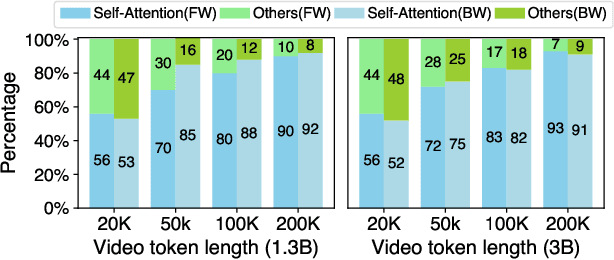
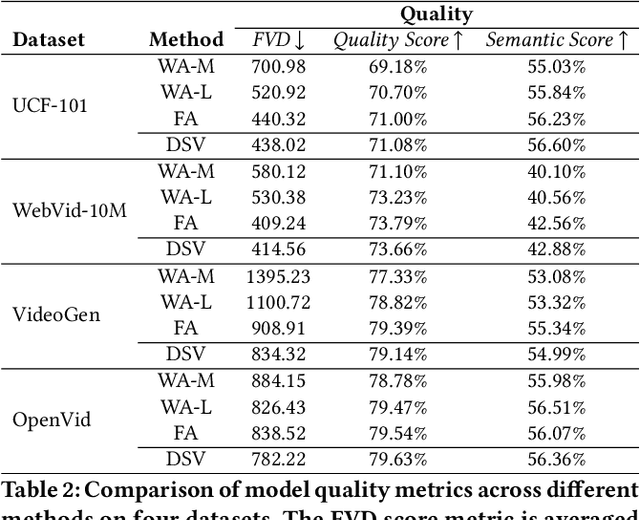
Diffusion Transformers (DiTs) have shown remarkable performance in modeling and generating high-quality videos. However, the quadratic computational complexity of 3D full attention mechanism presents significant challenges in scaling video DiT training, especially for high-definition and lengthy videos, where attention can dominate up to 95% of the end-to-end time and necessitate specialized communication paradigms to handle large input sizes. This paper introduces DSV, a novel framework designed to accelerate and scale the training of video DiTs by leveraging the inherent dynamic attention sparsity throughout the training process. DSV employs a two-stage training algorithm that exploits sparsity patterns, focusing on critical elements supported by efficient, tailored kernels. To accommodate the new sparsity dimension, we develop a hybrid sparsity-aware context parallelism that effectively scales to large inputs by addressing the heterogeneity of sparsity across attention heads and blocks, resulting in optimized sparse computation and communication. Extensive evaluations demonstrate that DSV achieves up to 3.02x gain in training throughput with nearly no quality degradation.
Echo: Simulating Distributed Training At Scale
Dec 17, 2024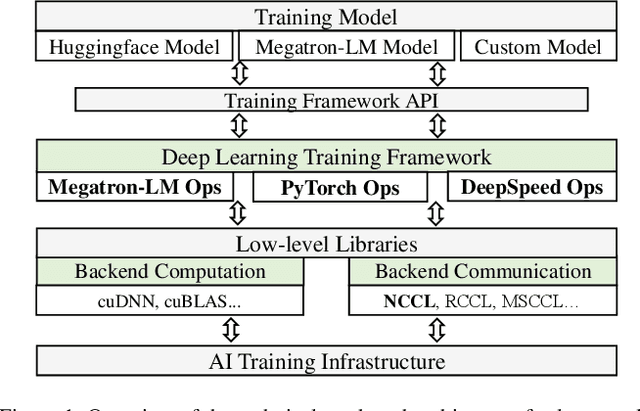


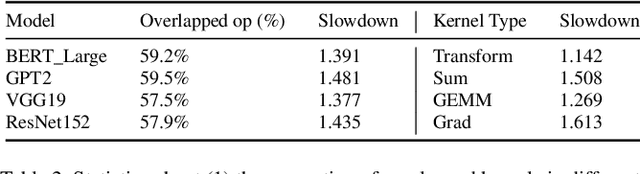
Simulation offers unique values for both enumeration and extrapolation purposes, and is becoming increasingly important for managing the massive machine learning (ML) clusters and large-scale distributed training jobs. In this paper, we build Echo to tackle three key challenges in large-scale training simulation: (1) tracing the runtime training workloads at each device in an ex-situ fashion so we can use a single device to obtain the actual execution graphs of 1K-GPU training, (2) accurately estimating the collective communication without high overheads of discrete-event based network simulation, and (3) accounting for the interference-induced computation slowdown from overlapping communication and computation kernels on the same device. Echo delivers on average 8% error in training step -- roughly 3x lower than state-of-the-art simulators -- for GPT-175B on a 96-GPU H800 cluster with 3D parallelism on Megatron-LM under 2 minutes.