 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNavigating the Shift: A Comparative Analysis of Web Search and Generative AI Response Generation
Jan 23, 2026The rise of generative AI as a primary information source presents a paradigm shift from traditional web search. This paper presents a large-scale empirical study quantifying the fundamental differences between the results returned by Google Search and leading generative AI services. We analyze multiple dimensions, demonstrating that AI-generated answers and web search results diverge significantly in their consulted source domains, the typology of these domains (e.g., earned media vs. owned, social), query intent and the freshness of the information provided. We then investigate the role of LLM pre-training as a key factor shaping these differences, analyzing how this intrinsic knowledge base interacts with and influences real-time web search when enabled. Our findings reveal the distinct mechanics of these two information ecosystems, leading to critical observations on the emergent field of Answer Engine Optimization (AEO) and its contrast with traditional Search Engine Optimization (SEO).
Generative Engine Optimization: How to Dominate AI Search
Sep 10, 2025The rapid adoption of generative AI-powered search engines like ChatGPT, Perplexity, and Gemini is fundamentally reshaping information retrieval, moving from traditional ranked lists to synthesized, citation-backed answers. This shift challenges established Search Engine Optimization (SEO) practices and necessitates a new paradigm, which we term Generative Engine Optimization (GEO). This paper presents a comprehensive comparative analysis of AI Search and traditional web search (Google). Through a series of large-scale, controlled experiments across multiple verticals, languages, and query paraphrases, we quantify critical differences in how these systems source information. Our key findings reveal that AI Search exhibit a systematic and overwhelming bias towards Earned media (third-party, authoritative sources) over Brand-owned and Social content, a stark contrast to Google's more balanced mix. We further demonstrate that AI Search services differ significantly from each other in their domain diversity, freshness, cross-language stability, and sensitivity to phrasing. Based on these empirical results, we formulate a strategic GEO agenda. We provide actionable guidance for practitioners, emphasizing the critical need to: (1) engineer content for machine scannability and justification, (2) dominate earned media to build AI-perceived authority, (3) adopt engine-specific and language-aware strategies, and (4) overcome the inherent "big brand bias" for niche players. Our work provides the foundational empirical analysis and a strategic framework for achieving visibility in the new generative search landscape.
Towards Dynamic 3D Reconstruction of Hand-Instrument Interaction in Ophthalmic Surgery
May 23, 2025

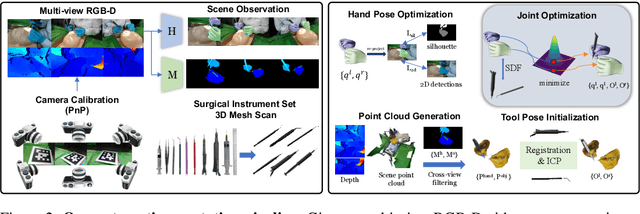
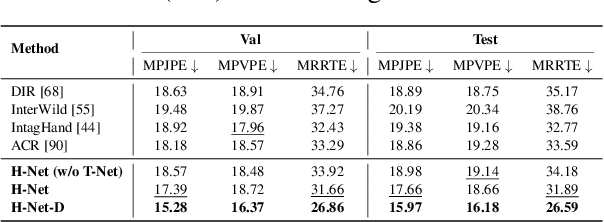
Accurate 3D reconstruction of hands and instruments is critical for vision-based analysis of ophthalmic microsurgery, yet progress has been hampered by the lack of realistic, large-scale datasets and reliable annotation tools. In this work, we introduce OphNet-3D, the first extensive RGB-D dynamic 3D reconstruction dataset for ophthalmic surgery, comprising 41 sequences from 40 surgeons and totaling 7.1 million frames, with fine-grained annotations of 12 surgical phases, 10 instrument categories, dense MANO hand meshes, and full 6-DoF instrument poses. To scalably produce high-fidelity labels, we design a multi-stage automatic annotation pipeline that integrates multi-view data observation, data-driven motion prior with cross-view geometric consistency and biomechanical constraints, along with a combination of collision-aware interaction constraints for instrument interactions. Building upon OphNet-3D, we establish two challenging benchmarks-bimanual hand pose estimation and hand-instrument interaction reconstruction-and propose two dedicated architectures: H-Net for dual-hand mesh recovery and OH-Net for joint reconstruction of two-hand-two-instrument interactions. These models leverage a novel spatial reasoning module with weak-perspective camera modeling and collision-aware center-based representation. Both architectures outperform existing methods by substantial margins, achieving improvements of over 2mm in Mean Per Joint Position Error (MPJPE) and up to 23% in ADD-S metrics for hand and instrument reconstruction, respectively.
Reliable Text-to-SQL with Adaptive Abstention
Jan 18, 2025



Large language models (LLMs) have revolutionized natural language interfaces for databases, particularly in text-to-SQL conversion. However, current approaches often generate unreliable outputs when faced with ambiguity or insufficient context. We present Reliable Text-to-SQL (RTS), a novel framework that enhances query generation reliability by incorporating abstention and human-in-the-loop mechanisms. RTS focuses on the critical schema linking phase, which aims to identify the key database elements needed for generating SQL queries. It autonomously detects potential errors during the answer generation process and responds by either abstaining or engaging in user interaction. A vital component of RTS is the Branching Point Prediction (BPP) which utilizes statistical conformal techniques on the hidden layers of the LLM model for schema linking, providing probabilistic guarantees on schema linking accuracy. We validate our approach through comprehensive experiments on the BIRD benchmark, demonstrating significant improvements in robustness and reliability. Our findings highlight the potential of combining transparent-box LLMs with human-in-the-loop processes to create more robust natural language interfaces for databases. For the BIRD benchmark, our approach achieves near-perfect schema linking accuracy, autonomously involving a human when needed. Combined with query generation, we demonstrate that near-perfect schema linking and a small query generation model can almost match SOTA accuracy achieved with a model orders of magnitude larger than the one we use.
Echo: Simulating Distributed Training At Scale
Dec 17, 2024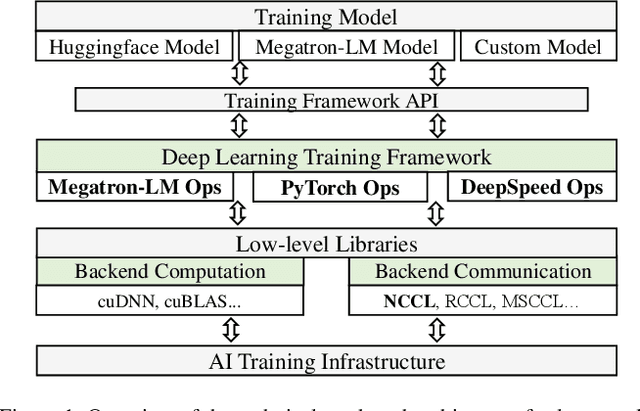


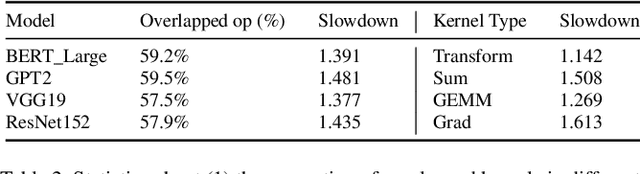
Simulation offers unique values for both enumeration and extrapolation purposes, and is becoming increasingly important for managing the massive machine learning (ML) clusters and large-scale distributed training jobs. In this paper, we build Echo to tackle three key challenges in large-scale training simulation: (1) tracing the runtime training workloads at each device in an ex-situ fashion so we can use a single device to obtain the actual execution graphs of 1K-GPU training, (2) accurately estimating the collective communication without high overheads of discrete-event based network simulation, and (3) accounting for the interference-induced computation slowdown from overlapping communication and computation kernels on the same device. Echo delivers on average 8% error in training step -- roughly 3x lower than state-of-the-art simulators -- for GPT-175B on a 96-GPU H800 cluster with 3D parallelism on Megatron-LM under 2 minutes.
Symmetry From Scratch: Group Equivariance as a Supervised Learning Task
Oct 05, 2024In machine learning datasets with symmetries, the paradigm for backward compatibility with symmetry-breaking has been to relax equivariant architectural constraints, engineering extra weights to differentiate symmetries of interest. However, this process becomes increasingly over-engineered as models are geared towards specific symmetries/asymmetries hardwired of a particular set of equivariant basis functions. In this work, we introduce symmetry-cloning, a method for inducing equivariance in machine learning models. We show that general machine learning architectures (i.e., MLPs) can learn symmetries directly as a supervised learning task from group equivariant architectures and retain/break the learned symmetry for downstream tasks. This simple formulation enables machine learning models with group-agnostic architectures to capture the inductive bias of group-equivariant architectures.
AXOLOTL: Fairness through Assisted Self-Debiasing of Large Language Model Outputs
Mar 01, 2024



Pre-trained Large Language Models (LLMs) have significantly advanced natural language processing capabilities but are susceptible to biases present in their training data, leading to unfair outcomes in various applications. While numerous strategies have been proposed to mitigate bias, they often require extensive computational resources and may compromise model performance. In this work, we introduce AXOLOTL, a novel post-processing framework, which operates agnostically across tasks and models, leveraging public APIs to interact with LLMs without direct access to internal parameters. Through a three-step process resembling zero-shot learning, AXOLOTL identifies biases, proposes resolutions, and guides the model to self-debias its outputs. This approach minimizes computational costs and preserves model performance, making AXOLOTL a promising tool for debiasing LLM outputs with broad applicability and ease of use.
Can Large Language Models Design Accurate Label Functions?
Nov 01, 2023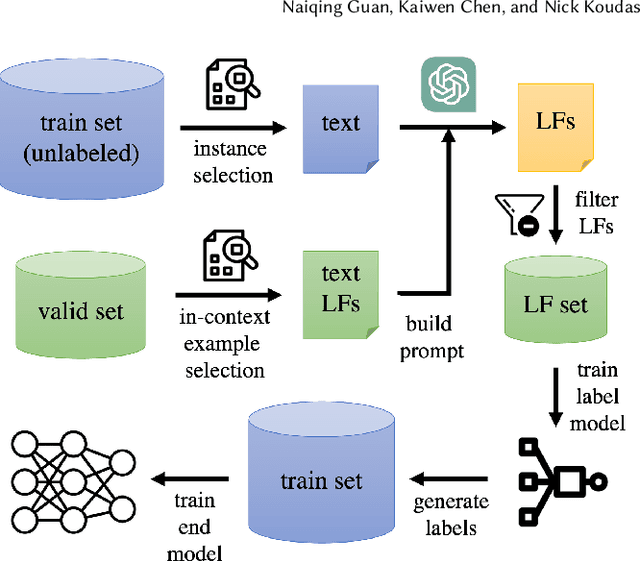



Programmatic weak supervision methodologies facilitate the expedited labeling of extensive datasets through the use of label functions (LFs) that encapsulate heuristic data sources. Nonetheless, the creation of precise LFs necessitates domain expertise and substantial endeavors. Recent advances in pre-trained language models (PLMs) have exhibited substantial potential across diverse tasks. However, the capacity of PLMs to autonomously formulate accurate LFs remains an underexplored domain. In this research, we address this gap by introducing DataSculpt, an interactive framework that harnesses PLMs for the automated generation of LFs. Within DataSculpt, we incorporate an array of prompting techniques, instance selection strategies, and LF filtration methods to explore the expansive design landscape. Ultimately, we conduct a thorough assessment of DataSculpt's performance on 12 real-world datasets, encompassing a range of tasks. This evaluation unveils both the strengths and limitations of contemporary PLMs in LF design.