 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNavigating the Shift: A Comparative Analysis of Web Search and Generative AI Response Generation
Jan 23, 2026The rise of generative AI as a primary information source presents a paradigm shift from traditional web search. This paper presents a large-scale empirical study quantifying the fundamental differences between the results returned by Google Search and leading generative AI services. We analyze multiple dimensions, demonstrating that AI-generated answers and web search results diverge significantly in their consulted source domains, the typology of these domains (e.g., earned media vs. owned, social), query intent and the freshness of the information provided. We then investigate the role of LLM pre-training as a key factor shaping these differences, analyzing how this intrinsic knowledge base interacts with and influences real-time web search when enabled. Our findings reveal the distinct mechanics of these two information ecosystems, leading to critical observations on the emergent field of Answer Engine Optimization (AEO) and its contrast with traditional Search Engine Optimization (SEO).
Generative Engine Optimization: How to Dominate AI Search
Sep 10, 2025The rapid adoption of generative AI-powered search engines like ChatGPT, Perplexity, and Gemini is fundamentally reshaping information retrieval, moving from traditional ranked lists to synthesized, citation-backed answers. This shift challenges established Search Engine Optimization (SEO) practices and necessitates a new paradigm, which we term Generative Engine Optimization (GEO). This paper presents a comprehensive comparative analysis of AI Search and traditional web search (Google). Through a series of large-scale, controlled experiments across multiple verticals, languages, and query paraphrases, we quantify critical differences in how these systems source information. Our key findings reveal that AI Search exhibit a systematic and overwhelming bias towards Earned media (third-party, authoritative sources) over Brand-owned and Social content, a stark contrast to Google's more balanced mix. We further demonstrate that AI Search services differ significantly from each other in their domain diversity, freshness, cross-language stability, and sensitivity to phrasing. Based on these empirical results, we formulate a strategic GEO agenda. We provide actionable guidance for practitioners, emphasizing the critical need to: (1) engineer content for machine scannability and justification, (2) dominate earned media to build AI-perceived authority, (3) adopt engine-specific and language-aware strategies, and (4) overcome the inherent "big brand bias" for niche players. Our work provides the foundational empirical analysis and a strategic framework for achieving visibility in the new generative search landscape.
Reliable Text-to-SQL with Adaptive Abstention
Jan 18, 2025



Large language models (LLMs) have revolutionized natural language interfaces for databases, particularly in text-to-SQL conversion. However, current approaches often generate unreliable outputs when faced with ambiguity or insufficient context. We present Reliable Text-to-SQL (RTS), a novel framework that enhances query generation reliability by incorporating abstention and human-in-the-loop mechanisms. RTS focuses on the critical schema linking phase, which aims to identify the key database elements needed for generating SQL queries. It autonomously detects potential errors during the answer generation process and responds by either abstaining or engaging in user interaction. A vital component of RTS is the Branching Point Prediction (BPP) which utilizes statistical conformal techniques on the hidden layers of the LLM model for schema linking, providing probabilistic guarantees on schema linking accuracy. We validate our approach through comprehensive experiments on the BIRD benchmark, demonstrating significant improvements in robustness and reliability. Our findings highlight the potential of combining transparent-box LLMs with human-in-the-loop processes to create more robust natural language interfaces for databases. For the BIRD benchmark, our approach achieves near-perfect schema linking accuracy, autonomously involving a human when needed. Combined with query generation, we demonstrate that near-perfect schema linking and a small query generation model can almost match SOTA accuracy achieved with a model orders of magnitude larger than the one we use.
WeShap: Weak Supervision Source Evaluation with Shapley Values
Jun 16, 2024



Efficient data annotation stands as a significant bottleneck in training contemporary machine learning models. The Programmatic Weak Supervision (PWS) pipeline presents a solution by utilizing multiple weak supervision sources to automatically label data, thereby expediting the annotation process. Given the varied contributions of these weak supervision sources to the accuracy of PWS, it is imperative to employ a robust and efficient metric for their evaluation. This is crucial not only for understanding the behavior and performance of the PWS pipeline but also for facilitating corrective measures. In our study, we introduce WeShap values as an evaluation metric, which quantifies the average contribution of weak supervision sources within a proxy PWS pipeline, leveraging the theoretical underpinnings of Shapley values. We demonstrate efficient computation of WeShap values using dynamic programming, achieving quadratic computational complexity relative to the number of weak supervision sources. Our experiments demonstrate the versatility of WeShap values across various applications, including the identification of beneficial or detrimental labeling functions, refinement of the PWS pipeline, and rectification of mislabeled data. Furthermore, WeShap values aid in comprehending the behavior of the PWS pipeline and scrutinizing specific instances of mislabeled data. Although initially derived from a specific proxy PWS pipeline, we empirically demonstrate the generalizability of WeShap values to other PWS pipeline configurations. Our findings indicate a noteworthy average improvement of 4.8 points in downstream model accuracy through the revision of the PWS pipeline compared to previous state-of-the-art methods, underscoring the efficacy of WeShap values in enhancing data quality for training machine learning models.
AXOLOTL: Fairness through Assisted Self-Debiasing of Large Language Model Outputs
Mar 01, 2024



Pre-trained Large Language Models (LLMs) have significantly advanced natural language processing capabilities but are susceptible to biases present in their training data, leading to unfair outcomes in various applications. While numerous strategies have been proposed to mitigate bias, they often require extensive computational resources and may compromise model performance. In this work, we introduce AXOLOTL, a novel post-processing framework, which operates agnostically across tasks and models, leveraging public APIs to interact with LLMs without direct access to internal parameters. Through a three-step process resembling zero-shot learning, AXOLOTL identifies biases, proposes resolutions, and guides the model to self-debias its outputs. This approach minimizes computational costs and preserves model performance, making AXOLOTL a promising tool for debiasing LLM outputs with broad applicability and ease of use.
ActiveDP: Bridging Active Learning and Data Programming
Feb 08, 2024



Modern machine learning models require large labelled datasets to achieve good performance, but manually labelling large datasets is expensive and time-consuming. The data programming paradigm enables users to label large datasets efficiently but produces noisy labels, which deteriorates the downstream model's performance. The active learning paradigm, on the other hand, can acquire accurate labels but only for a small fraction of instances. In this paper, we propose ActiveDP, an interactive framework bridging active learning and data programming together to generate labels with both high accuracy and coverage, combining the strengths of both paradigms. Experiments show that ActiveDP outperforms previous weak supervision and active learning approaches and consistently performs well under different labelling budgets.
Can Large Language Models Design Accurate Label Functions?
Nov 01, 2023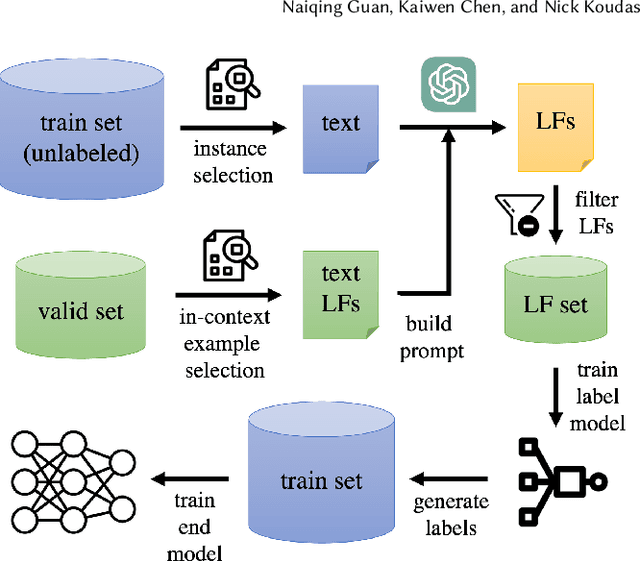



Programmatic weak supervision methodologies facilitate the expedited labeling of extensive datasets through the use of label functions (LFs) that encapsulate heuristic data sources. Nonetheless, the creation of precise LFs necessitates domain expertise and substantial endeavors. Recent advances in pre-trained language models (PLMs) have exhibited substantial potential across diverse tasks. However, the capacity of PLMs to autonomously formulate accurate LFs remains an underexplored domain. In this research, we address this gap by introducing DataSculpt, an interactive framework that harnesses PLMs for the automated generation of LFs. Within DataSculpt, we incorporate an array of prompting techniques, instance selection strategies, and LF filtration methods to explore the expansive design landscape. Ultimately, we conduct a thorough assessment of DataSculpt's performance on 12 real-world datasets, encompassing a range of tasks. This evaluation unveils both the strengths and limitations of contemporary PLMs in LF design.
Effective Explanations for Entity Resolution Models
Apr 01, 2022

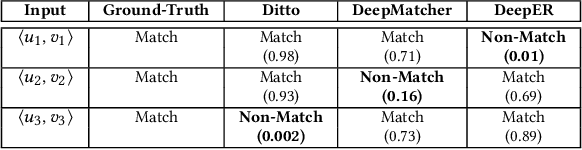
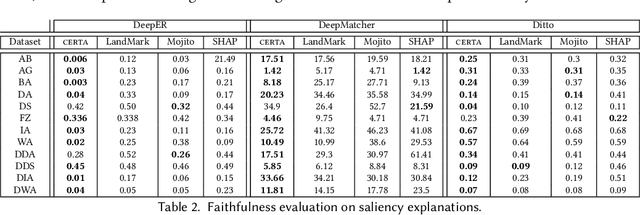
Entity resolution (ER) aims at matching records that refer to the same real-world entity. Although widely studied for the last 50 years, ER still represents a challenging data management problem, and several recent works have started to investigate the opportunity of applying deep learning (DL) techniques to solve this problem. In this paper, we study the fundamental problem of explainability of the DL solution for ER. Understanding the matching predictions of an ER solution is indeed crucial to assess the trustworthiness of the DL model and to discover its biases. We treat the DL model as a black box classifier and - while previous approaches to provide explanations for DL predictions are agnostic to the classification task. we propose the CERTA approach that is aware of the semantics of the ER problem. Our approach produces both saliency explanations, which associate each attribute with a saliency score, and counterfactual explanations, which provide examples of values that can flip the prediction. CERTA builds on a probabilistic framework that aims at computing the explanations evaluating the outcomes produced by using perturbed copies of the input records. We experimentally evaluate CERTA's explanations of state-of-the-art ER solutions based on DL models using publicly available datasets, and demonstrate the effectiveness of CERTA over recently proposed methods for this problem.
Efficient Construction of Nonlinear Models overNormalized Data
Nov 23, 2020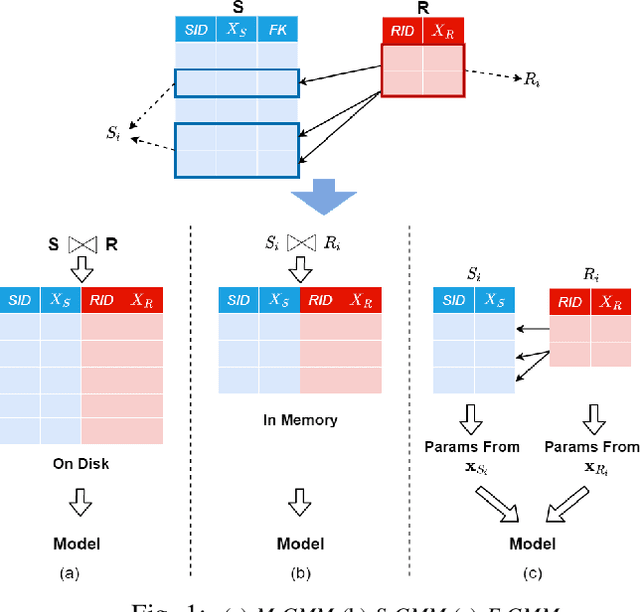

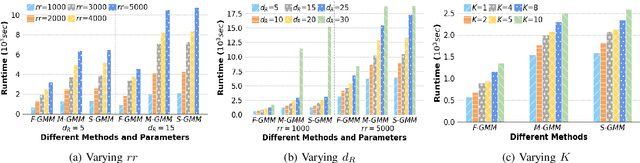
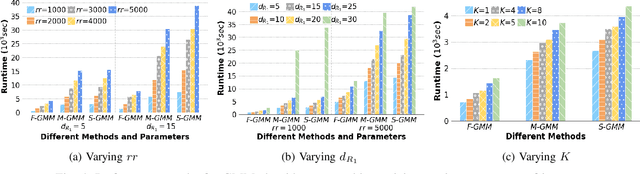
Machine Learning (ML) applications are proliferating in the enterprise. Relational data which are prevalent in enterprise applications are typically normalized; as a result, data has to be denormalized via primary/foreign-key joins to be provided as input to ML algorithms. In this paper, we study the implementation of popular nonlinear ML models, Gaussian Mixture Models (GMM) and Neural Networks (NN), over normalized data addressing both cases of binary and multi-way joins over normalized relations. For the case of GMM, we show how it is possible to decompose computation in a systematic way both for binary joins and for multi-way joins to construct mixture models. We demonstrate that by factoring the computation, one can conduct the training of the models much faster compared to other applicable approaches, without any loss in accuracy. For the case of NN, we propose algorithms to train the network taking normalized data as the input. Similarly, we present algorithms that can conduct the training of the network in a factorized way and offer performance advantages. The redundancy introduced by denormalization can be exploited for certain types of activation functions. However, we demonstrate that attempting to explore this redundancy is helpful up to a certain point; exploring redundancy at higher layers of the network will always result in increased costs and is not recommended. We present the results of a thorough experimental evaluation, varying several parameters of the input relations involved and demonstrate that our proposals for the training of GMM and NN yield drastic performance improvements typically starting at 100%, which become increasingly higher as parameters of the underlying data vary, without any loss in accuracy.
Evaluating Temporal Queries Over Video Feeds
Mar 05, 2020
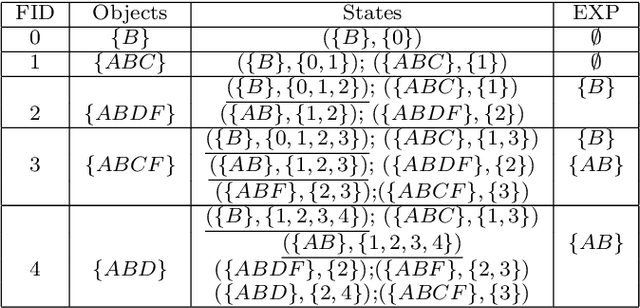
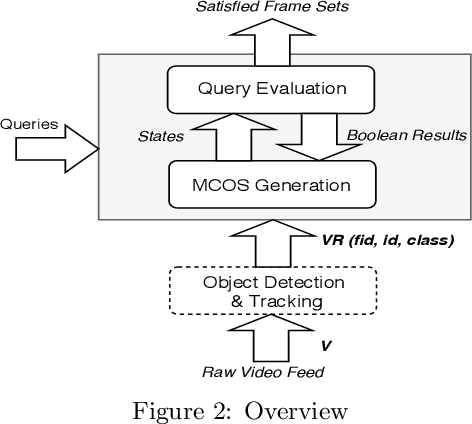
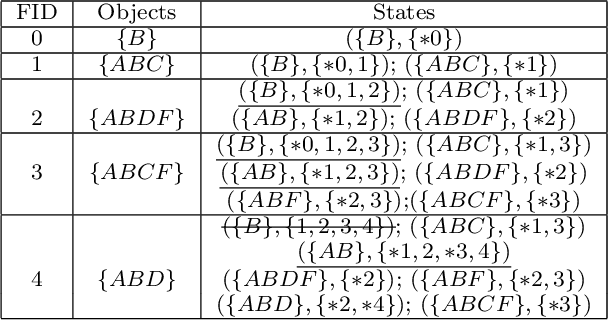
Recent advances in Computer Vision and Deep Learning made possible the efficient extraction of a schema from frames of streaming video. As such, a stream of objects and their associated classes along with unique object identifiers derived via object tracking can be generated, providing unique objects as they are captured across frames. In this paper we initiate a study of temporal queries involving objects and their co-occurrences in video feeds. For example, queries that identify video segments during which the same two red cars and the same two humans appear jointly for five minutes are of interest to many applications ranging from law enforcement to security and safety. We take the first step and define such queries in a way that they incorporate certain physical aspects of video capture such as object occlusion. We present an architecture consisting of three layers, namely object detection/tracking, intermediate data generation and query evaluation. We propose two techniques,MFS and SSG, to organize all detected objects in the intermediate data generation layer, which effectively, given the queries, minimizes the number of objects and frames that have to be considered during query evaluation. We also introduce an algorithm called State Traversal (ST) that processes incoming frames against the SSG and efficiently prunes objects and frames unrelated to query evaluation, while maintaining all states required for succinct query evaluation. We present the results of a thorough experimental evaluation utilizing both real and synthetic data establishing the trade-offs between MFS and SSG. We stress various parameters of interest in our evaluation and demonstrate that the proposed query evaluation methodology coupled with the proposed algorithms is capable to evaluate temporal queries over video feeds efficiently, achieving orders of magnitude performance benefits.