 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFairness and Bias in Truth Discovery Algorithms: An Experimental Analysis
Apr 25, 2023



Machine learning (ML) based approaches are increasingly being used in a number of applications with societal impact. Training ML models often require vast amounts of labeled data, and crowdsourcing is a dominant paradigm for obtaining labels from multiple workers. Crowd workers may sometimes provide unreliable labels, and to address this, truth discovery (TD) algorithms such as majority voting are applied to determine the consensus labels from conflicting worker responses. However, it is important to note that these consensus labels may still be biased based on sensitive attributes such as gender, race, or political affiliation. Even when sensitive attributes are not involved, the labels can be biased due to different perspectives of subjective aspects such as toxicity. In this paper, we conduct a systematic study of the bias and fairness of TD algorithms. Our findings using two existing crowd-labeled datasets, reveal that a non-trivial proportion of workers provide biased results, and using simple approaches for TD is sub-optimal. Our study also demonstrates that popular TD algorithms are not a panacea. Additionally, we quantify the impact of these unfair workers on downstream ML tasks and show that conventional methods for achieving fairness and correcting label biases are ineffective in this setting. We end the paper with a plea for the design of novel bias-aware truth discovery algorithms that can ameliorate these issues.
Fair Active Learning
Jul 01, 2020
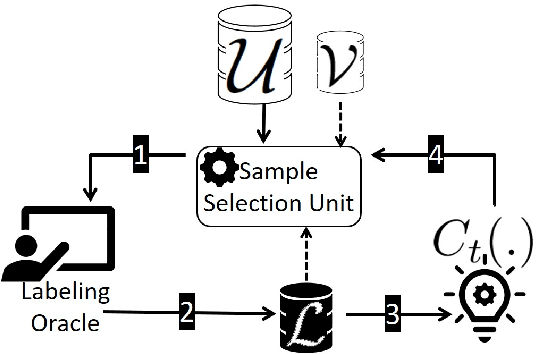
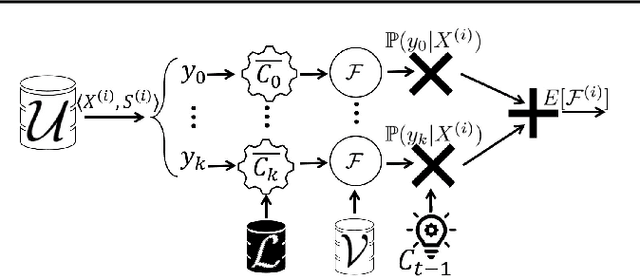
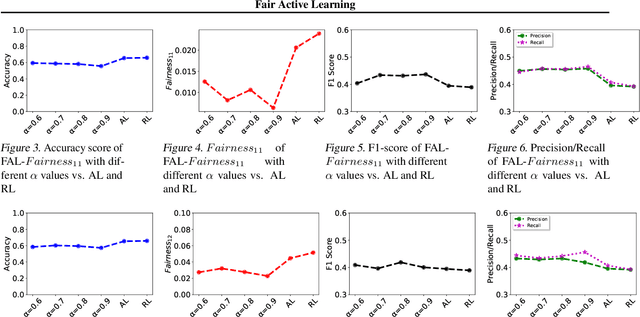
Machine learning (ML) is increasingly being used in high-stakes applications impacting society. Therefore, it is of critical importance that ML models do not propagate discrimination. Collecting accurate labeled data in societal applications is challenging and costly. Active learning is a promising approach to build an accurate classifier by interactively querying an oracle within a labeling budget. We design algorithms for fair active learning that carefully selects data points to be labeled so as to balance model accuracy and fairness. Specifically, we focus on demographic parity - a widely used measure of fairness. Extensive experiments over benchmark datasets demonstrate the effectiveness of our proposed approach.
Local Embeddings for Relational Data Integration
Sep 03, 2019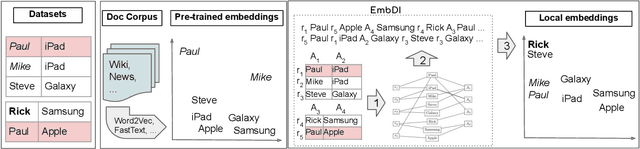
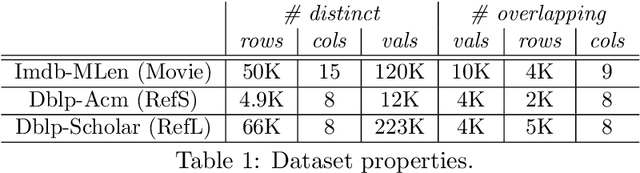
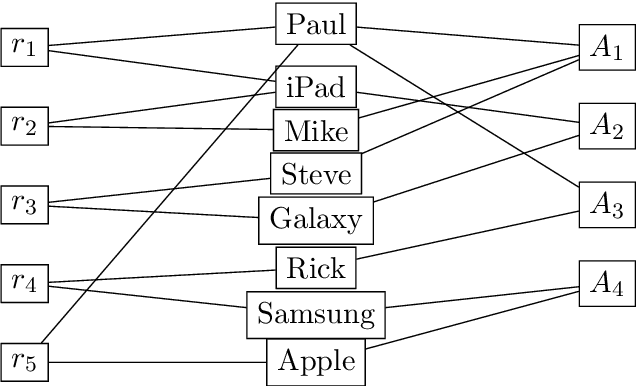
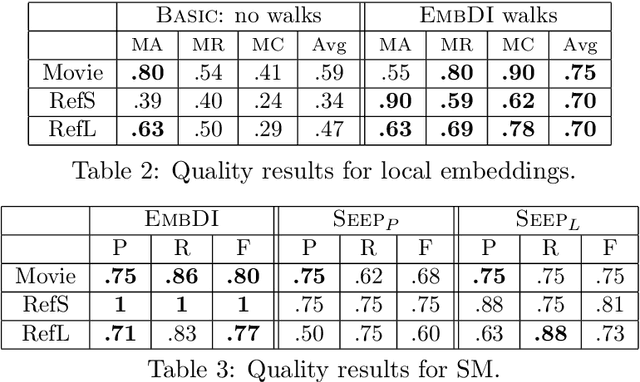
Integrating information from heterogeneous data sources is one of the fundamental problems facing any enterprise. Recently, it has been shown that deep learning based techniques such as embeddings are a promising approach for data integration problems. Prior efforts directly use pre-trained embeddings or simplistically adapt techniques from natural language processing to obtain relational embeddings. In this work, we propose algorithms for obtaining local embeddings that are effective for data integration tasks on relational data. We make three major contributions. First, we describe a compact graph-based representation that allows the specification of a rich set of relationships inherent in relational world. Second, we propose how to derive sentences from such graph that effectively describe the similarity across elements (tokens, attributes, rows) across the two datasets. The embeddings are learned based on such sentences. Finally, we propose a diverse collection of criteria to evaluate relational embeddings and perform extensive set of experiments validating them. Our experiments show that our system, EmbDI, produces meaningful results for data integration tasks and our embeddings improve the result quality for existing state of the art methods.
AutoER: Automated Entity Resolution using Generative Modelling
Aug 16, 2019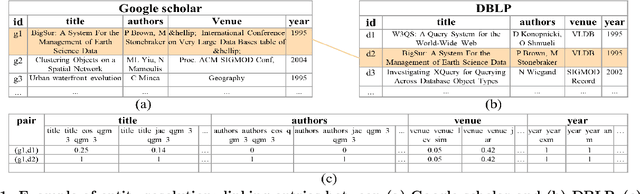
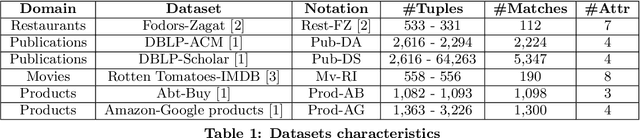
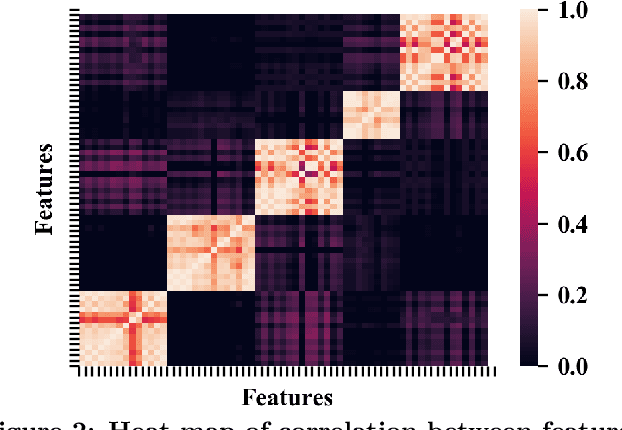
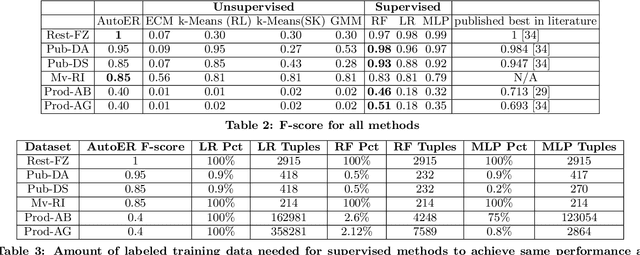
Entity resolution (ER) refers to the problem of identifying records in one or more relations that refer to the same real-world entity. ER has been extensively studied by the database community with supervised machine learning approaches achieving the state-of-the-art results. However, supervised ML requires many labeled examples, both matches and unmatches, which are expensive to obtain. In this paper, we investigate an important problem: how can we design an unsupervised algorithm for ER that can achieve performance comparable to supervised approaches? We propose an automated ER solution, AutoER, that requires zero labeled examples. Our central insight is that the similarity vectors for matches should look different from that of unmatches. A number of innovations are needed to translate the intuition into an actual algorithm for ER. We advocate for the use of generative models to capture the two similarity vector distributions (the match distribution and the unmatch distribution). We propose an expectation maximization based algorithm to learn the model parameters. Our algorithm addresses many practical challenges including feature correlations, model overfitting, class imbalance, and transitivity between matches. On six datasets from four different domains, we show that the performance of AutoER is comparable and sometimes even better than supervised ML approaches.
Are Outlier Detection Methods Resilient to Sampling?
Jul 31, 2019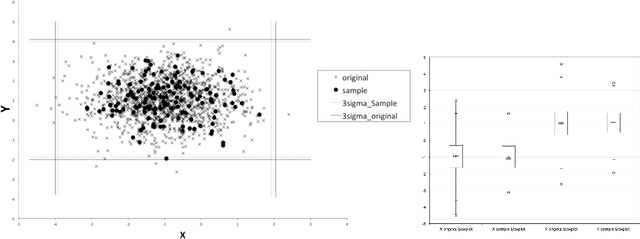
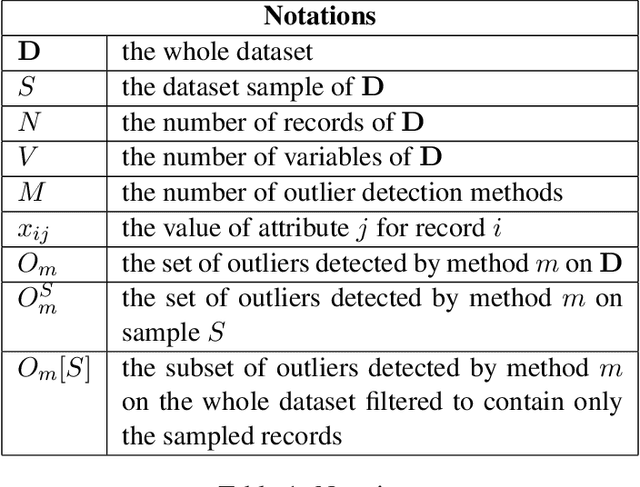
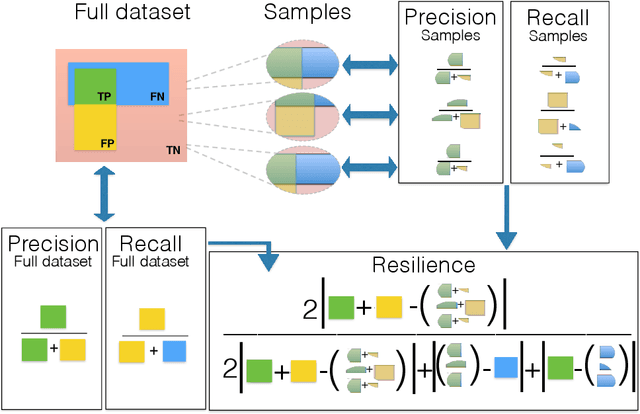
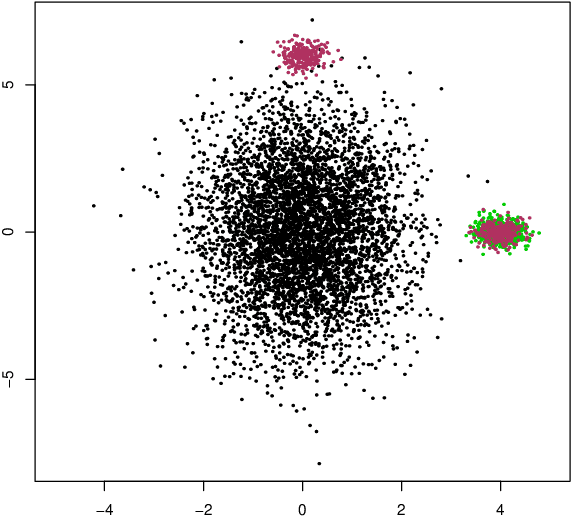
Outlier detection is a fundamental task in data mining and has many applications including detecting errors in databases. While there has been extensive prior work on methods for outlier detection, modern datasets often have sizes that are beyond the ability of commonly used methods to process the data within a reasonable time. To overcome this issue, outlier detection methods can be trained over samples of the full-sized dataset. However, it is not clear how a model trained on a sample compares with one trained on the entire dataset. In this paper, we introduce the notion of resilience to sampling for outlier detection methods. Orthogonal to traditional performance metrics such as precision/recall, resilience represents the extent to which the outliers detected by a method applied to samples from a sampling scheme matches those when applied to the whole dataset. We propose a novel approach for estimating the resilience to sampling of both individual outlier methods and their ensembles. We performed an extensive experimental study on synthetic and real-world datasets where we study seven diverse and representative outlier detection methods, compare results obtained from samples versus those obtained from the whole datasets and evaluate the accuracy of our resilience estimates. We observed that the methods are not equally resilient to a given sampling scheme and it is often the case that careful joint selection of both the sampling scheme and the outlier detection method is necessary. It is our hope that the paper initiates research on designing outlier detection algorithms that are resilient to sampling.
Approximate Query Processing using Deep Generative Models
Mar 24, 2019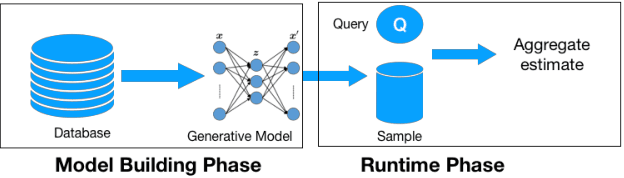

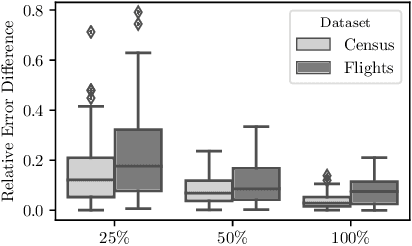

Data is generated at an unprecedented rate surpassing our ability to analyze them. One viable solution that was pioneered by the database community is Approximate Query Processing (AQP). AQP seeks to provide approximate answers to queries in a fraction of time needed for computing exact answers. This is often achieved by running the query on a pre-computed or on-demand derived sample and generating estimates for the entire dataset based on the result. In this work, we explore a novel approach for AQP utilizing deep learning (DL). We use deep generative models, an unsupervised learning based approach, to learn the data distribution faithfully in a compact manner (typically few hundred KBs). Queries could be answered approximately by generating samples from the learned model. This approach eliminates the dependency of AQP to a sample of fixed size and allows us to satisfy arbitrary accuracy requirements by generating as many samples as needed very fast. While we specifically focus on variational autoencoders (VAE), we demonstrate how our approach could also be used for other popular DL models such as generative adversarial networks (GAN) and deep Bayesian networks (DBN). Our other contributions include (a) identifying model bias and minimizing it through a rejection sampling based approach (b) An algorithm to build model ensembles for AQP for improved accuracy and (c) an analysis of VAE latent space to understand its suitability to AQP. Our extensive experiments show that deep learning is a very promising approach for AQP.
Multi-Attribute Selectivity Estimation Using Deep Learning
Mar 24, 2019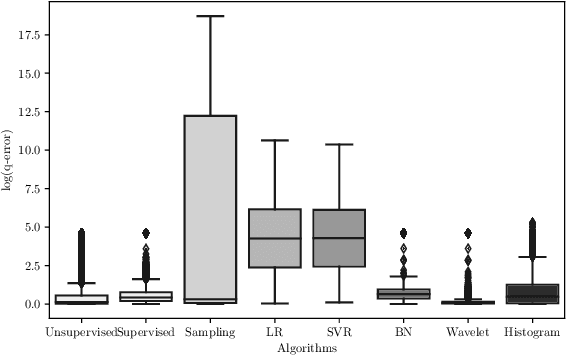
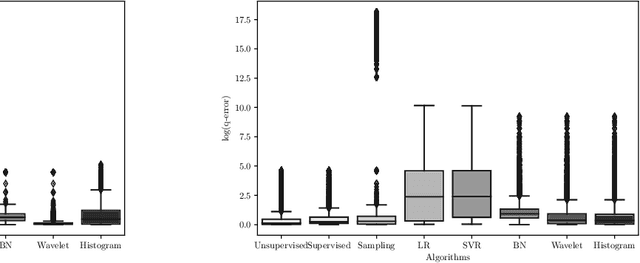
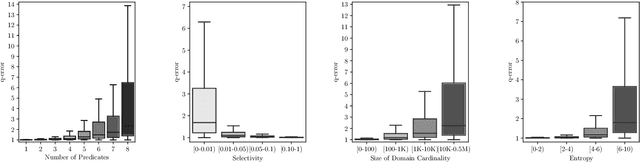
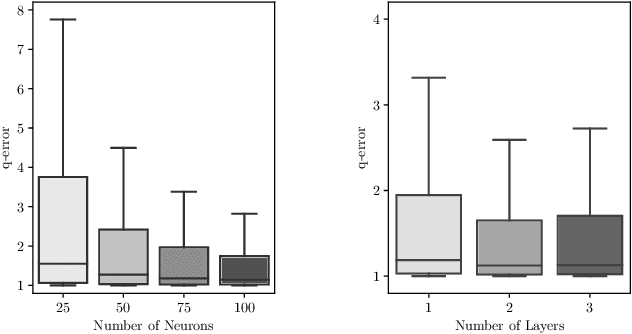
Selectivity estimation - the problem of estimating the result size of queries - is a fundamental yet challenging problem in databases. Accurate estimation of query selectivity involving multiple correlated attributes is especially challenging. Poor cardinality estimates could result in the selection of bad plans by the query optimizer. In this paper, we investigate the feasibility of using deep learning based approaches for challenging scenarios such as queries involving multiple predicates and/or low selectivity. Specifically, we propose two complementary approaches. Our first approach considers selectivity as an unsupervised deep density estimation problem. We successfully introduce techniques from neural density estimation for this purpose. The key idea is to decompose the joint distribution into a set of tractable conditional probability distributions such that they satisfy the autoregressive property. Our second approach formulates selectivity estimation as a supervised deep learning problem that predicts the selectivity of a given query. We also introduce and address a number of practical challenges arising when adapting deep learning for relational data. These include query/data featurization, incorporating query workload information in a deep learning framework and the dynamic scenario where both data and workload queries could be updated. Our extensive experiments with a special emphasis on queries with a large number of predicates and/or small result sizes demonstrates that deep learning based techniques are a promising research avenue for selectivity estimation worthy of further investigation.
Reuse and Adaptation for Entity Resolution through Transfer Learning
Sep 28, 2018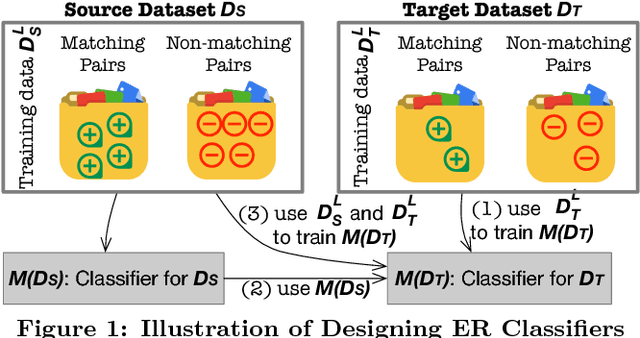
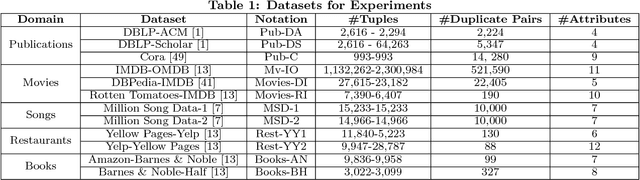
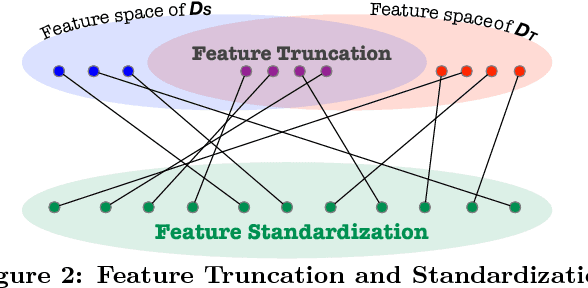

Entity resolution (ER) is one of the fundamental problems in data integration, where machine learning (ML) based classifiers often provide the state-of-the-art results. Considerable human effort goes into feature engineering and training data creation. In this paper, we investigate a new problem: Given a dataset D_T for ER with limited or no training data, is it possible to train a good ML classifier on D_T by reusing and adapting the training data of dataset D_S from same or related domain? Our major contributions include (1) a distributed representation based approach to encode each tuple from diverse datasets into a standard feature space; (2) identification of common scenarios where the reuse of training data can be beneficial; and (3) five algorithms for handling each of the aforementioned scenarios. We have performed comprehensive experiments on 12 datasets from 5 different domains (publications, movies, songs, restaurants, and books). Our experiments show that our algorithms provide significant benefits such as providing superior performance for a fixed training data size.