 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConstraint Decay: The Fragility of LLM Agents in Backend Code Generation
May 07, 2026Large Language Model (LLM) agents demonstrate strong performance in autonomous code generation under loose specifications. However, production-grade software requires strict adherence to structural constraints, such as architectural patterns, databases, and object-relational mappings. Existing benchmarks often overlook these non-functional requirements, rewarding functionally correct but structurally arbitrary solutions. We present a systematic study evaluating how well agents handle structural constraints in multi-file backend generation. By fixing a unified API contract across 80 greenfield generation tasks and 20 feature-implementation tasks spanning eight web frameworks, we isolate the effect of structural complexity using a dual evaluation with end-to-end behavioral tests and static verifiers. Our findings reveal a phenomenon of constraint decay: as structural requirements accumulate, agent performance exhibits a substantial decline. Capable configurations lose 30 points on average in assertion pass rates from baseline to fully specified tasks, while some weaker configurations approach zero. Framework sensitivity analysis exposes significant performance disparities: agents succeed in minimal, explicit frameworks (e.g., Flask) but perform substantially worse on average in convention-heavy environments (e.g., FastAPI, Django). Finally, error analysis identifies data-layer defects (e.g., incorrect query composition and ORM runtime violations) as the leading root causes. This work highlights that jointly satisfying functional and structural requirements remains a key open challenge for coding agents.
MedScribe: Clinically Grounded CT Reporting through Agentic Workflows
May 03, 2026Vision-language models (VLMs) have shown potential for automated radiology report generation, yet existing approaches rely on global embedding compression of volumetric data, often leading to hallucinated findings and limited anatomical grounding in 3D CT imaging. We introduce MedScribe, a hypothesis-driven framework that reformulates report generation as an iterative evidence acquisition process rather than a single-pass encoding task. MedScribe models reporting as a sequential decision process in which a large language model dynamically invokes pathology-specific diagnostic tools to extract localized volumetric features. These structured features are used to query a multidimensional retrieval space aligned with pathology-specific textual evidence. By explicitly accumulating quantitative evidence prior to synthesis, the framework enforces fine-grained grounding and reduces unsupported claims. Without task-specific fine-tuning, MedScribe improves clinical accuracy, factual consistency, and interpretability on CT-RATE and RadChestCT compared to state-of-the-art 2D and 3D VLMs, demonstrating the value of hypothesis-driven reasoning for reliable medical image reporting.
Parallel Context-of-Experts Decoding for Retrieval Augmented Generation
Jan 13, 2026Retrieval Augmented Generation faces a trade-off: concatenating documents in a long prompt enables multi-document reasoning but creates prefill bottlenecks, while encoding document KV caches separately offers speed but breaks cross-document interaction. We propose Parallel Context-of-Experts Decoding (Pced), a training-free framework that shifts evidence aggregation from the attention mechanism to the decoding. Pced treats retrieved documents as isolated "experts", synchronizing their predictions via a novel retrieval-aware contrastive decoding rule that weighs expert logits against the model prior. This approach recovers cross-document reasoning capabilities without constructing a shared attention across documents.
Combating Misinformation in the Arab World: Challenges & Opportunities
Jun 05, 2025Misinformation and disinformation pose significant risks globally, with the Arab region facing unique vulnerabilities due to geopolitical instabilities, linguistic diversity, and cultural nuances. We explore these challenges through the key facets of combating misinformation: detection, tracking, mitigation and community-engagement. We shed light on how connecting with grass-roots fact-checking organizations, understanding cultural norms, promoting social correction, and creating strong collaborative information networks can create opportunities for a more resilient information ecosystem in the Arab world.
RelationalFactQA: A Benchmark for Evaluating Tabular Fact Retrieval from Large Language Models
May 27, 2025



Factuality in Large Language Models (LLMs) is a persistent challenge. Current benchmarks often assess short factual answers, overlooking the critical ability to generate structured, multi-record tabular outputs from parametric knowledge. We demonstrate that this relational fact retrieval is substantially more difficult than isolated point-wise queries, even when individual facts are known to the model, exposing distinct failure modes sensitive to output dimensionality (e.g., number of attributes or records). To systematically evaluate this under-explored capability, we introduce RelationalFactQA, a new benchmark featuring diverse natural language questions (paired with SQL) and gold-standard tabular answers, specifically designed to assess knowledge retrieval in a structured format. RelationalFactQA enables analysis across varying query complexities, output sizes, and data characteristics. Our experiments reveal that even state-of-the-art LLMs struggle significantly, not exceeding 25% factual accuracy in generating relational outputs, with performance notably degrading as output dimensionality increases. These findings underscore critical limitations in current LLMs' ability to synthesize structured factual knowledge and establish RelationalFactQA as a crucial resource for measuring future progress in LLM factuality.
Community Moderation and the New Epistemology of Fact Checking on Social Media
May 26, 2025Social media platforms have traditionally relied on internal moderation teams and partnerships with independent fact-checking organizations to identify and flag misleading content. Recently, however, platforms including X (formerly Twitter) and Meta have shifted towards community-driven content moderation by launching their own versions of crowd-sourced fact-checking -- Community Notes. If effectively scaled and governed, such crowd-checking initiatives have the potential to combat misinformation with increased scale and speed as successfully as community-driven efforts once did with spam. Nevertheless, general content moderation, especially for misinformation, is inherently more complex. Public perceptions of truth are often shaped by personal biases, political leanings, and cultural contexts, complicating consensus on what constitutes misleading content. This suggests that community efforts, while valuable, cannot replace the indispensable role of professional fact-checkers. Here we systemically examine the current approaches to misinformation detection across major platforms, explore the emerging role of community-driven moderation, and critically evaluate both the promises and challenges of crowd-checking at scale.
Think2SQL: Reinforce LLM Reasoning Capabilities for Text2SQL
Apr 21, 2025



Large Language Models (LLMs) have shown impressive capabilities in transforming natural language questions about relational databases into SQL queries. Despite recent improvements, small LLMs struggle to handle questions involving multiple tables and complex SQL patterns under a Zero-Shot Learning (ZSL) setting. Supervised Fine-Tuning (SFT) partially compensate the knowledge deficits in pretrained models but falls short while dealing with queries involving multi-hop reasoning. To bridge this gap, different LLM training strategies to reinforce reasoning capabilities have been proposed, ranging from leveraging a thinking process within ZSL, including reasoning traces in SFT, or adopt Reinforcement Learning (RL) strategies. However, the influence of reasoning on Text2SQL performance is still largely unexplored. This paper investigates to what extent LLM reasoning capabilities influence their Text2SQL performance on four benchmark datasets. To this end, it considers the following LLM settings: (1) ZSL, including general-purpose reasoning or not; (2) SFT, with and without task-specific reasoning traces; (3) RL, leveraging execution accuracy as primary reward function; (4) SFT+RL, i.e, a two-stage approach that combines SFT and RL. The results show that general-purpose reasoning under ZSL proves to be ineffective in tackling complex Text2SQL cases. Small LLMs benefit from SFT with reasoning much more than larger ones, bridging the gap of their (weaker) model pretraining. RL is generally beneficial across all tested models and datasets, particularly when SQL queries involve multi-hop reasoning and multiple tables. Small LLMs with SFT+RL excel on most complex datasets thanks to a strategic balance between generality of the reasoning process and optimization of the execution accuracy. Thanks to RL, the7B Qwen-Coder-2.5 model performs on par with 100+ Billion ones on the Bird dataset.
Beyond RAG: Task-Aware KV Cache Compression for Comprehensive Knowledge Reasoning
Mar 06, 2025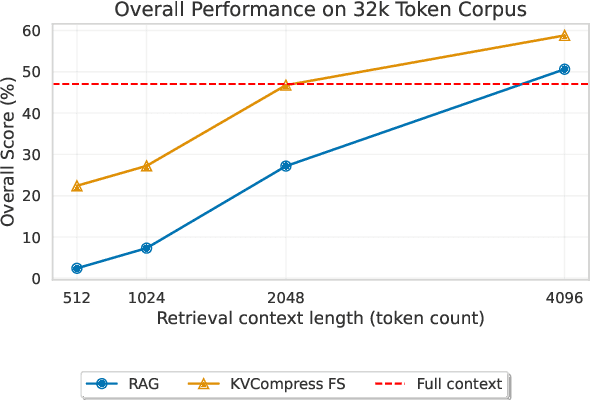

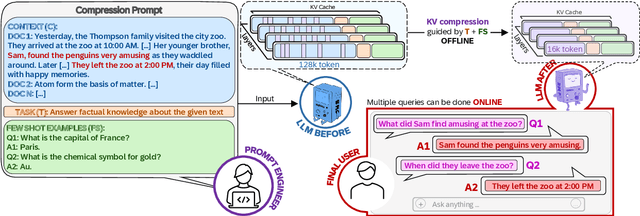

Incorporating external knowledge in large language models (LLMs) enhances their utility across diverse applications, but existing methods have trade-offs. Retrieval-Augmented Generation (RAG) fetches evidence via similarity search, but key information may fall outside top ranked results. Long-context models can process multiple documents but are computationally expensive and limited by context window size. Inspired by students condensing study material for open-book exams, we propose task-aware key-value (KV) cache compression, which compresses external knowledge in a zero- or few-shot setup. This enables LLMs to reason efficiently over a compacted representation of all relevant information. Experiments show our approach outperforms both RAG and task-agnostic compression methods. On LongBench v2, it improves accuracy by up to 7 absolute points over RAG with a 30x compression rate, while reducing inference latency from 0.43s to 0.16s. A synthetic dataset highlights that RAG performs well when sparse evidence suffices, whereas task-aware compression is superior for broad knowledge tasks.
Latent Abstractions in Generative Diffusion Models
Oct 04, 2024



In this work we study how diffusion-based generative models produce high-dimensional data, such as an image, by implicitly relying on a manifestation of a low-dimensional set of latent abstractions, that guide the generative process. We present a novel theoretical framework that extends NLF, and that offers a unique perspective on SDE-based generative models. The development of our theory relies on a novel formulation of the joint (state and measurement) dynamics, and an information-theoretic measure of the influence of the system state on the measurement process. According to our theory, diffusion models can be cast as a system of SDE, describing a non-linear filter in which the evolution of unobservable latent abstractions steers the dynamics of an observable measurement process (corresponding to the generative pathways). In addition, we present an empirical study to validate our theory and previous empirical results on the emergence of latent abstractions at different stages of the generative process.
Finch: Prompt-guided Key-Value Cache Compression
Jul 31, 2024Recent large language model applications, such as Retrieval-Augmented Generation and chatbots, have led to an increased need to process longer input contexts. However, this requirement is hampered by inherent limitations. Architecturally, models are constrained by a context window defined during training. Additionally, processing extensive texts requires substantial GPU memory. We propose a novel approach, Finch, to compress the input context by leveraging the pre-trained model weights of the self-attention. Given a prompt and a long text, Finch iteratively identifies the most relevant Key (K) and Value (V) pairs over chunks of the text conditioned on the prompt. Only such pairs are stored in the KV cache, which, within the space constrained by the context window, ultimately contains a compressed version of the long text. Our proposal enables models to consume large inputs even with high compression (up to 93x) while preserving semantic integrity without the need for fine-tuning.