 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenchmarking Visual LLMs Resilience to Unanswerable Questions on Visually Rich Documents
Nov 14, 2025The evolution of Visual Large Language Models (VLLMs) has revolutionized the automatic understanding of Visually Rich Documents (VRDs), which contain both textual and visual elements. Although VLLMs excel in Visual Question Answering (VQA) on multi-page VRDs, their ability to detect unanswerable questions is still an open research question. Our research delves into the robustness of the VLLMs to plausible yet unanswerable questions, i.e., questions that appear valid but cannot be answered due to subtle corruptions caused by swaps between related concepts or plausible question formulations. Corruptions are generated by replacing the original natural language entities with other ones of the same type, belonging to different document elements, and in different layout positions or pages of the related document. To this end, we present VRD-UQA (VISUALLY RICH DOCUMENT UNANSWERABLE QUESTION ANSWERING), a benchmark for evaluating VLLMs' resilience to plausible yet unanswerable questions across multiple dimensions. It automatically alters the questions of existing VQA datasets consisting of multi-page VRDs, verifies their unanswerability using a VLLM-as-a-judge approach, and then thoroughly evaluates VLLMs' performance. Experiments, run on 12 models, analyze: (1) The VLLMs' accuracy in detecting unanswerable questions at both page and document levels; (2) The effect of different types of corruption (NLP entity, document element, layout); (3) The effectiveness of different knowledge injection strategies based on in-context learning (OCR, multi-page selection, or the possibility of unanswerability). Our findings reveal VLLMs' limitations and demonstrate that VRD-UQA can serve as an evaluation framework for developing resilient document VQA systems.
Think2SQL: Reinforce LLM Reasoning Capabilities for Text2SQL
Apr 21, 2025



Large Language Models (LLMs) have shown impressive capabilities in transforming natural language questions about relational databases into SQL queries. Despite recent improvements, small LLMs struggle to handle questions involving multiple tables and complex SQL patterns under a Zero-Shot Learning (ZSL) setting. Supervised Fine-Tuning (SFT) partially compensate the knowledge deficits in pretrained models but falls short while dealing with queries involving multi-hop reasoning. To bridge this gap, different LLM training strategies to reinforce reasoning capabilities have been proposed, ranging from leveraging a thinking process within ZSL, including reasoning traces in SFT, or adopt Reinforcement Learning (RL) strategies. However, the influence of reasoning on Text2SQL performance is still largely unexplored. This paper investigates to what extent LLM reasoning capabilities influence their Text2SQL performance on four benchmark datasets. To this end, it considers the following LLM settings: (1) ZSL, including general-purpose reasoning or not; (2) SFT, with and without task-specific reasoning traces; (3) RL, leveraging execution accuracy as primary reward function; (4) SFT+RL, i.e, a two-stage approach that combines SFT and RL. The results show that general-purpose reasoning under ZSL proves to be ineffective in tackling complex Text2SQL cases. Small LLMs benefit from SFT with reasoning much more than larger ones, bridging the gap of their (weaker) model pretraining. RL is generally beneficial across all tested models and datasets, particularly when SQL queries involve multi-hop reasoning and multiple tables. Small LLMs with SFT+RL excel on most complex datasets thanks to a strategic balance between generality of the reasoning process and optimization of the execution accuracy. Thanks to RL, the7B Qwen-Coder-2.5 model performs on par with 100+ Billion ones on the Bird dataset.
BONES: a Benchmark fOr Neural Estimation of Shapley values
Jul 23, 2024Shapley Values are concepts established for eXplainable AI. They are used to explain black-box predictive models by quantifying the features' contributions to the model's outcomes. Since computing the exact Shapley Values is known to be computationally intractable on real-world datasets, neural estimators have emerged as alternative, more scalable approaches to get approximated Shapley Values estimates. However, experiments with neural estimators are currently hard to replicate as algorithm implementations, explainer evaluators, and results visualizations are neither standardized nor promptly usable. To bridge this gap, we present BONES, a new benchmark focused on neural estimation of Shapley Value. It provides researchers with a suite of state-of-the-art neural and traditional estimators, a set of commonly used benchmark datasets, ad hoc modules for training black-box models, as well as specific functions to easily compute the most popular evaluation metrics and visualize results. The purpose is to simplify XAI model usage, evaluation, and comparison. In this paper, we showcase BONES results and visualizations for XAI model benchmarking on both tabular and image data. The open-source library is available at the following link: https://github.com/DavideNapolitano/BONES.
Benchmarking Representations for Speech, Music, and Acoustic Events
May 02, 2024

Limited diversity in standardized benchmarks for evaluating audio representation learning (ARL) methods may hinder systematic comparison of current methods' capabilities. We present ARCH, a comprehensive benchmark for evaluating ARL methods on diverse audio classification domains, covering acoustic events, music, and speech. ARCH comprises 12 datasets, that allow us to thoroughly assess pre-trained SSL models of different sizes. ARCH streamlines benchmarking of ARL techniques through its unified access to a wide range of domains and its ability to readily incorporate new datasets and models. To address the current lack of open-source, pre-trained models for non-speech audio, we also release new pre-trained models that demonstrate strong performance on non-speech datasets. We argue that the presented wide-ranging evaluation provides valuable insights into state-of-the-art ARL methods, and is useful to pinpoint promising research directions.
M3-VRD: Multimodal Multi-task Multi-teacher Visually-Rich Form Document Understanding
Feb 28, 2024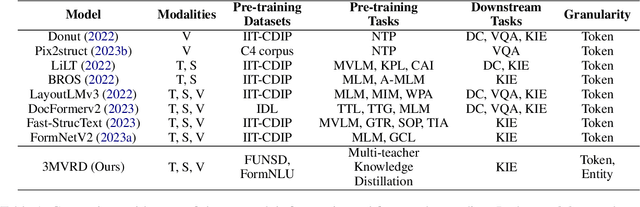
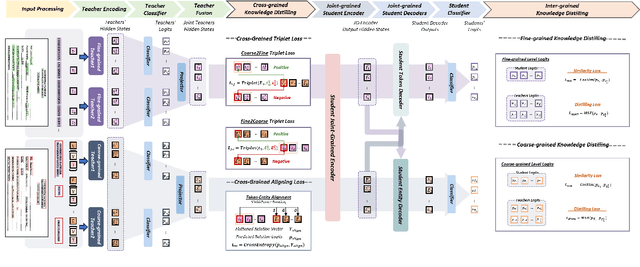
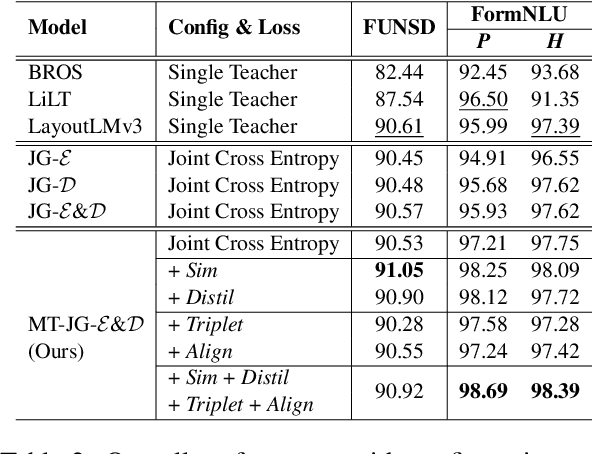
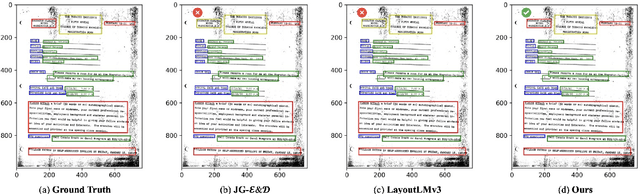
This paper presents a groundbreaking multimodal, multi-task, multi-teacher joint-grained knowledge distillation model for visually-rich form document understanding. The model is designed to leverage insights from both fine-grained and coarse-grained levels by facilitating a nuanced correlation between token and entity representations, addressing the complexities inherent in form documents. Additionally, we introduce new inter-grained and cross-grained loss functions to further refine diverse multi-teacher knowledge distillation transfer process, presenting distribution gaps and a harmonised understanding of form documents. Through a comprehensive evaluation across publicly available form document understanding datasets, our proposed model consistently outperforms existing baselines, showcasing its efficacy in handling the intricate structures and content of visually complex form documents.
DQNC2S: DQN-based Cross-stream Crisis event Summarizer
Jan 12, 2024Summarizing multiple disaster-relevant data streams simultaneously is particularly challenging as existing Retrieve&Re-ranking strategies suffer from the inherent redundancy of multi-stream data and limited scalability in a multi-query setting. This work proposes an online approach to crisis timeline generation based on weak annotation with Deep Q-Networks. It selects on-the-fly the relevant pieces of text without requiring neither human annotations nor content re-ranking. This makes the inference time independent of the number of input queries. The proposed approach also incorporates a redundancy filter into the reward function to effectively handle cross-stream content overlaps. The achieved ROUGE and BERTScore results are superior to those of best-performing models on the CrisisFACTS 2022 benchmark.
Enhancing BERT-Based Visual Question Answering through Keyword-Driven Sentence Selection
Oct 13, 2023The Document-based Visual Question Answering competition addresses the automatic detection of parent-child relationships between elements in multi-page documents. The goal is to identify the document elements that answer a specific question posed in natural language. This paper describes the PoliTo's approach to addressing this task, in particular, our best solution explores a text-only approach, leveraging an ad hoc sampling strategy. Specifically, our approach leverages the Masked Language Modeling technique to fine-tune a BERT model, focusing on sentences containing sensitive keywords that also occur in the questions, such as references to tables or images. Thanks to the effectiveness of this approach, we are able to achieve high performance compared to baselines, demonstrating how our solution contributes positively to this task.
ITALIC: An Italian Intent Classification Dataset
Jun 14, 2023
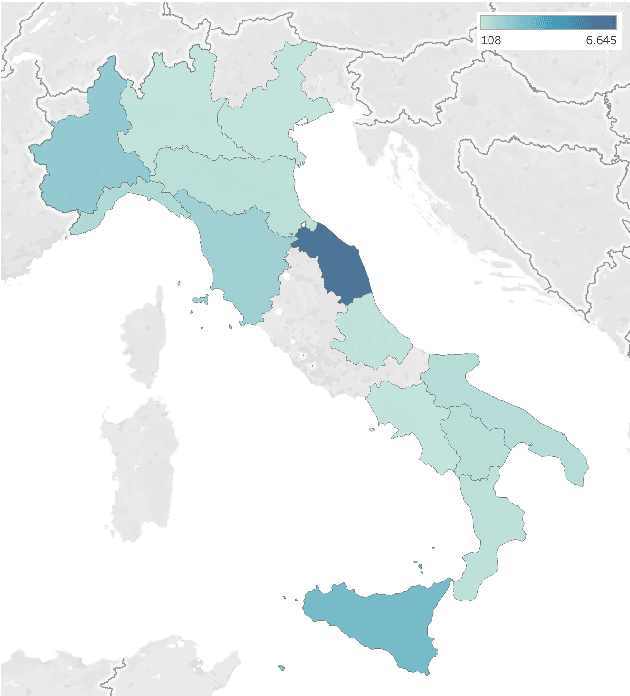
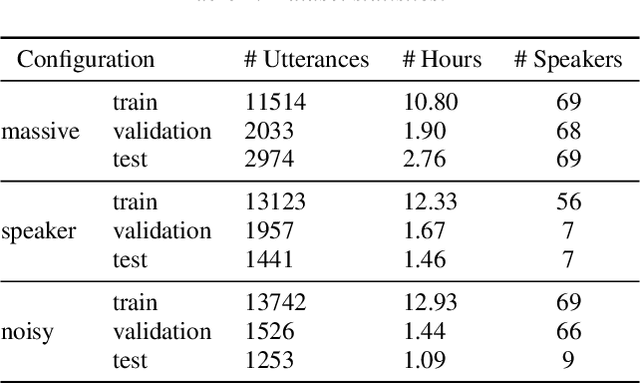
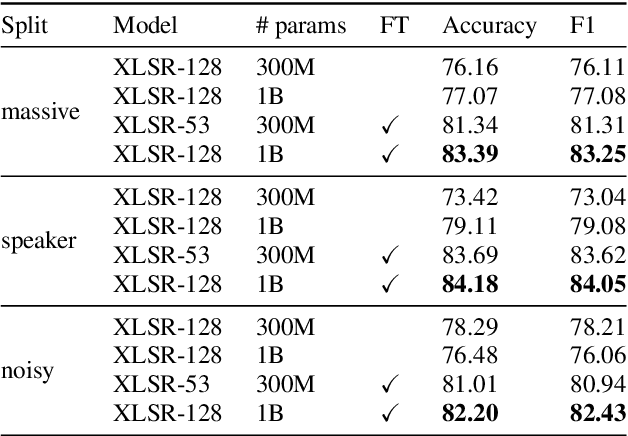
Recent large-scale Spoken Language Understanding datasets focus predominantly on English and do not account for language-specific phenomena such as particular phonemes or words in different lects. We introduce ITALIC, the first large-scale speech dataset designed for intent classification in Italian. The dataset comprises 16,521 crowdsourced audio samples recorded by 70 speakers from various Italian regions and annotated with intent labels and additional metadata. We explore the versatility of ITALIC by evaluating current state-of-the-art speech and text models. Results on intent classification suggest that increasing scale and running language adaptation yield better speech models, monolingual text models outscore multilingual ones, and that speech recognition on ITALIC is more challenging than on existing Italian benchmarks. We release both the dataset and the annotation scheme to streamline the development of new Italian SLU models and language-specific datasets.