 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMagnifier: A Multi-grained Neural Network-based Architecture for Burned Area Delineation
Apr 28, 2025In crisis management and remote sensing, image segmentation plays a crucial role, enabling tasks like disaster response and emergency planning by analyzing visual data. Neural networks are able to analyze satellite acquisitions and determine which areas were affected by a catastrophic event. The problem in their development in this context is the data scarcity and the lack of extensive benchmark datasets, limiting the capabilities of training large neural network models. In this paper, we propose a novel methodology, namely Magnifier, to improve segmentation performance with limited data availability. The Magnifier methodology is applicable to any existing encoder-decoder architecture, as it extends a model by merging information at different contextual levels through a dual-encoder approach: a local and global encoder. Magnifier analyzes the input data twice using the dual-encoder approach. In particular, the local and global encoders extract information from the same input at different granularities. This allows Magnifier to extract more information than the other approaches given the same set of input images. Magnifier improves the quality of the results of +2.65% on average IoU while leading to a restrained increase in terms of the number of trainable parameters compared to the original model. We evaluated our proposed approach with state-of-the-art burned area segmentation models, demonstrating, on average, comparable or better performances in less than half of the GFLOPs.
Level Up Your Tutorials: VLMs for Game Tutorials Quality Assessment
Aug 15, 2024



Designing effective game tutorials is crucial for a smooth learning curve for new players, especially in games with many rules and complex core mechanics. Evaluating the effectiveness of these tutorials usually requires multiple iterations with testers who have no prior knowledge of the game. Recent Vision-Language Models (VLMs) have demonstrated significant capabilities in understanding and interpreting visual content. VLMs can analyze images, provide detailed insights, and answer questions about their content. They can recognize objects, actions, and contexts in visual data, making them valuable tools for various applications, including automated game testing. In this work, we propose an automated game-testing solution to evaluate the quality of game tutorials. Our approach leverages VLMs to analyze frames from video game tutorials, answer relevant questions to simulate human perception, and provide feedback. This feedback is compared with expected results to identify confusing or problematic scenes and highlight potential errors for developers. In addition, we publish complete tutorial videos and annotated frames from different game versions used in our tests. This solution reduces the need for extensive manual testing, especially by speeding up and simplifying the initial development stages of the tutorial to improve the final game experience.
ViGEO: an Assessment of Vision GNNs in Earth Observation
Feb 15, 2024Satellite missions and Earth Observation (EO) systems represent fundamental assets for environmental monitoring and the timely identification of catastrophic events, long-term monitoring of both natural resources and human-made assets, such as vegetation, water bodies, forests as well as buildings. Different EO missions enables the collection of information on several spectral bandwidths, such as MODIS, Sentinel-1 and Sentinel-2. Thus, given the recent advances of machine learning, computer vision and the availability of labeled data, researchers demonstrated the feasibility and the precision of land-use monitoring systems and remote sensing image classification through the use of deep neural networks. Such systems may help domain experts and governments in constant environmental monitoring, enabling timely intervention in case of catastrophic events (e.g., forest wildfire in a remote area). Despite the recent advances in the field of computer vision, many works limit their analysis on Convolutional Neural Networks (CNNs) and, more recently, to vision transformers (ViTs). Given the recent successes of Graph Neural Networks (GNNs) on non-graph data, such as time-series and images, we investigate the performances of a recent Vision GNN architecture (ViG) applied to the task of land cover classification. The experimental results show that ViG achieves state-of-the-art performances in multiclass and multilabel classification contexts, surpassing both ViT and ResNet on large-scale benchmarks.
CaBuAr: California Burned Areas dataset for delineation
Jan 21, 2024



Forest wildfires represent one of the catastrophic events that, over the last decades, caused huge environmental and humanitarian damages. In addition to a significant amount of carbon dioxide emission, they are a source of risk to society in both short-term (e.g., temporary city evacuation due to fire) and long-term (e.g., higher risks of landslides) cases. Consequently, the availability of tools to support local authorities in automatically identifying burned areas plays an important role in the continuous monitoring requirement to alleviate the aftereffects of such catastrophic events. The great availability of satellite acquisitions coupled with computer vision techniques represents an important step in developing such tools. This paper introduces a novel open dataset that tackles the burned area delineation problem, a binary segmentation problem applied to satellite imagery. The presented resource consists of pre- and post-fire Sentinel-2 L2A acquisitions of California forest fires that took place starting in 2015. Raster annotations were generated from the data released by California's Department of Forestry and Fire Protection. Moreover, in conjunction with the dataset, we release three different baselines based on spectral indexes analyses, SegFormer, and U-Net models.
ITALIC: An Italian Intent Classification Dataset
Jun 14, 2023
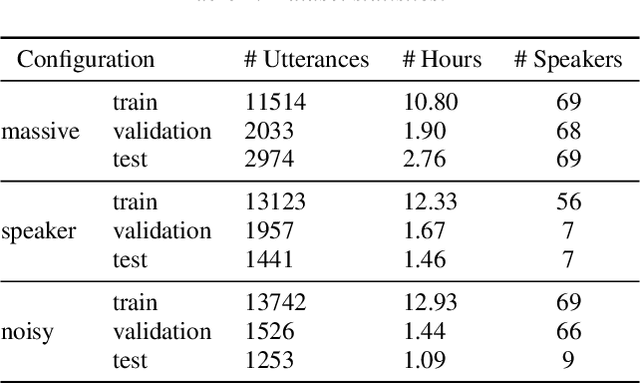
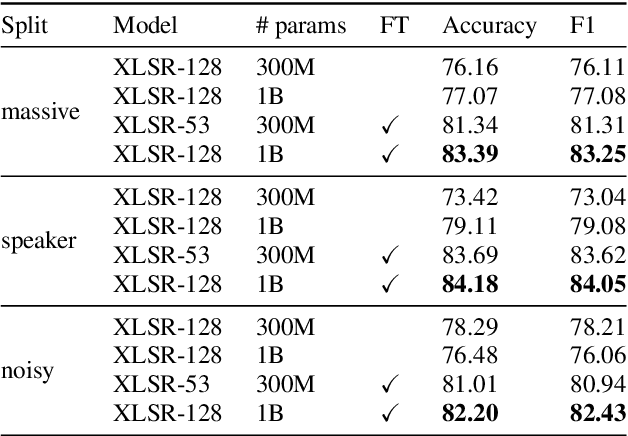
Recent large-scale Spoken Language Understanding datasets focus predominantly on English and do not account for language-specific phenomena such as particular phonemes or words in different lects. We introduce ITALIC, the first large-scale speech dataset designed for intent classification in Italian. The dataset comprises 16,521 crowdsourced audio samples recorded by 70 speakers from various Italian regions and annotated with intent labels and additional metadata. We explore the versatility of ITALIC by evaluating current state-of-the-art speech and text models. Results on intent classification suggest that increasing scale and running language adaptation yield better speech models, monolingual text models outscore multilingual ones, and that speech recognition on ITALIC is more challenging than on existing Italian benchmarks. We release both the dataset and the annotation scheme to streamline the development of new Italian SLU models and language-specific datasets.