 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenchmarking Representations for Speech, Music, and Acoustic Events
May 02, 2024

Limited diversity in standardized benchmarks for evaluating audio representation learning (ARL) methods may hinder systematic comparison of current methods' capabilities. We present ARCH, a comprehensive benchmark for evaluating ARL methods on diverse audio classification domains, covering acoustic events, music, and speech. ARCH comprises 12 datasets, that allow us to thoroughly assess pre-trained SSL models of different sizes. ARCH streamlines benchmarking of ARL techniques through its unified access to a wide range of domains and its ability to readily incorporate new datasets and models. To address the current lack of open-source, pre-trained models for non-speech audio, we also release new pre-trained models that demonstrate strong performance on non-speech datasets. We argue that the presented wide-ranging evaluation provides valuable insights into state-of-the-art ARL methods, and is useful to pinpoint promising research directions.
M3-VRD: Multimodal Multi-task Multi-teacher Visually-Rich Form Document Understanding
Feb 28, 2024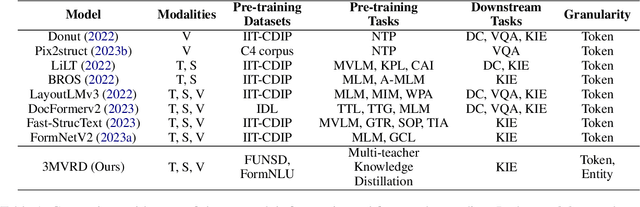
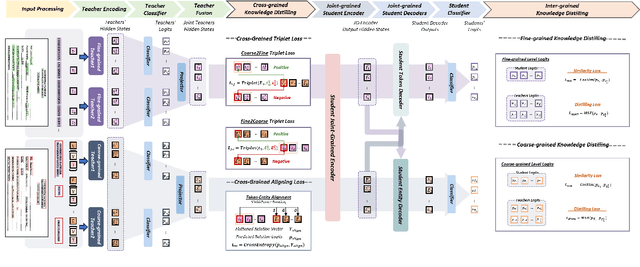
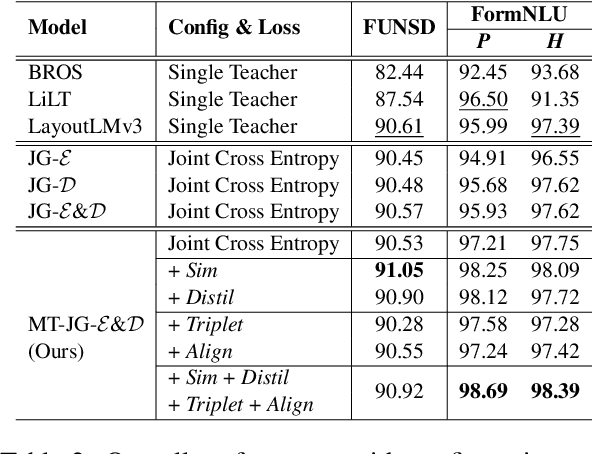
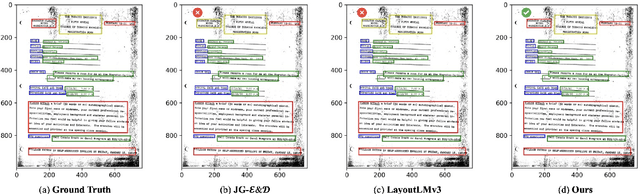
This paper presents a groundbreaking multimodal, multi-task, multi-teacher joint-grained knowledge distillation model for visually-rich form document understanding. The model is designed to leverage insights from both fine-grained and coarse-grained levels by facilitating a nuanced correlation between token and entity representations, addressing the complexities inherent in form documents. Additionally, we introduce new inter-grained and cross-grained loss functions to further refine diverse multi-teacher knowledge distillation transfer process, presenting distribution gaps and a harmonised understanding of form documents. Through a comprehensive evaluation across publicly available form document understanding datasets, our proposed model consistently outperforms existing baselines, showcasing its efficacy in handling the intricate structures and content of visually complex form documents.
Enhancing BERT-Based Visual Question Answering through Keyword-Driven Sentence Selection
Oct 13, 2023The Document-based Visual Question Answering competition addresses the automatic detection of parent-child relationships between elements in multi-page documents. The goal is to identify the document elements that answer a specific question posed in natural language. This paper describes the PoliTo's approach to addressing this task, in particular, our best solution explores a text-only approach, leveraging an ad hoc sampling strategy. Specifically, our approach leverages the Masked Language Modeling technique to fine-tune a BERT model, focusing on sentences containing sensitive keywords that also occur in the questions, such as references to tables or images. Thanks to the effectiveness of this approach, we are able to achieve high performance compared to baselines, demonstrating how our solution contributes positively to this task.
ITALIC: An Italian Intent Classification Dataset
Jun 14, 2023
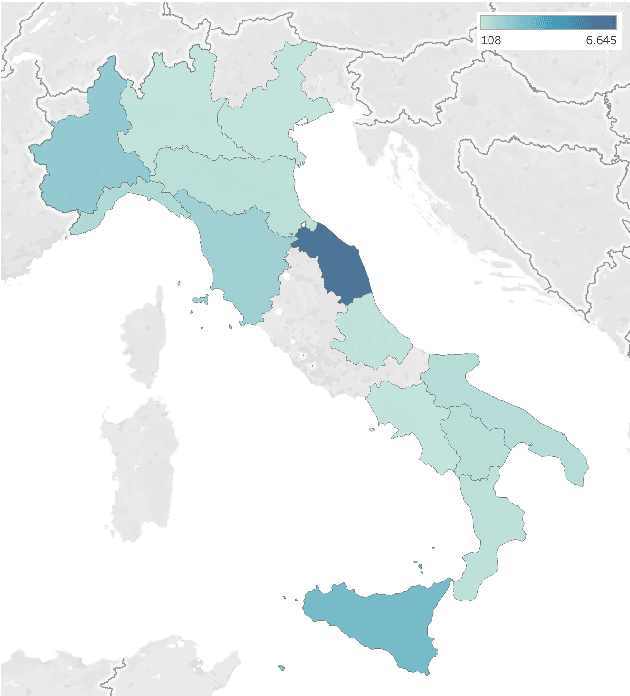
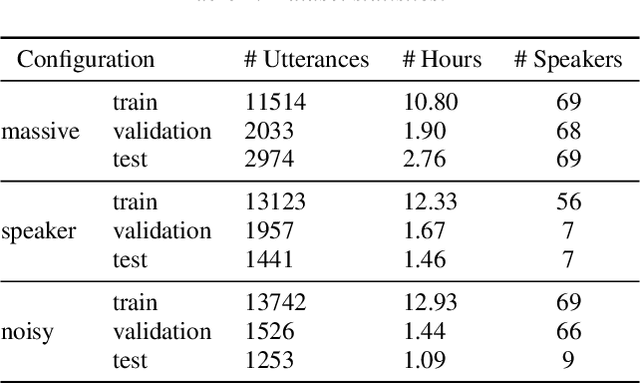
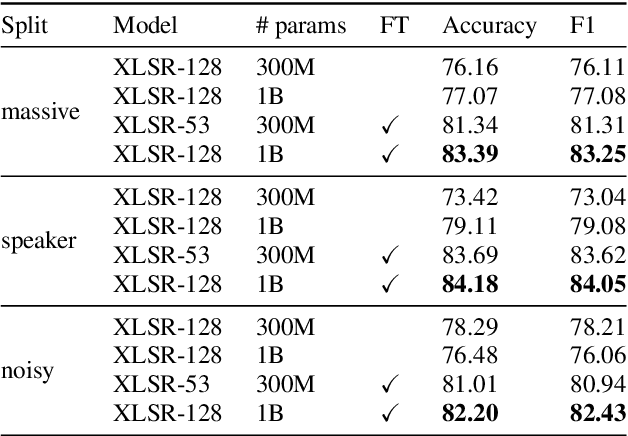
Recent large-scale Spoken Language Understanding datasets focus predominantly on English and do not account for language-specific phenomena such as particular phonemes or words in different lects. We introduce ITALIC, the first large-scale speech dataset designed for intent classification in Italian. The dataset comprises 16,521 crowdsourced audio samples recorded by 70 speakers from various Italian regions and annotated with intent labels and additional metadata. We explore the versatility of ITALIC by evaluating current state-of-the-art speech and text models. Results on intent classification suggest that increasing scale and running language adaptation yield better speech models, monolingual text models outscore multilingual ones, and that speech recognition on ITALIC is more challenging than on existing Italian benchmarks. We release both the dataset and the annotation scheme to streamline the development of new Italian SLU models and language-specific datasets.