 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Empirical Analysis of Static Analysis Methods for Detection and Mitigation of Code Library Hallucinations
Apr 09, 2026Despite extensive research, Large Language Models continue to hallucinate when generating code, particularly when using libraries. On NL-to-code benchmarks that require library use, we find that LLMs generate code that uses non-existent library features in 8.1-40% of responses.One intuitive approach for detection and mitigation of hallucinations is static analysis. In this paper, we analyse the potential of static analysis tools, both in terms of what they can solve and what they cannot. We find that static analysis tools can detect 16-70% of all errors, and 14-85% of library hallucinations, with performance varying by LLM and dataset. Through manual analysis, we identify cases a static method could not plausibly catch, which gives an upper bound on their potential from 48.5% to 77%. Overall, we show that static analysis methods are cheap method for addressing some forms of hallucination, and we quantify how far short of solving the problem they will always be.
MMCOMET: A Large-Scale Multimodal Commonsense Knowledge Graph for Contextual Reasoning
Mar 01, 2026We present MMCOMET, the first multimodal commonsense knowledge graph (MMKG) that integrates physical, social, and eventive knowledge. MMCOMET extends the ATOMIC2020 knowledge graph to include a visual dimension, through an efficient image retrieval process, resulting in over 900K multimodal triples. This new resource addresses a major limitation of existing MMKGs in supporting complex reasoning tasks like image captioning and storytelling. Through a standard visual storytelling experiment, we show that our holistic approach enables the generation of richer, coherent, and contextually grounded stories than those produced using text-only knowledge. This resource establishes a new foundation for multimodal commonsense reasoning and narrative generation.
TriG-NER: Triplet-Grid Framework for Discontinuous Named Entity Recognition
Nov 04, 2024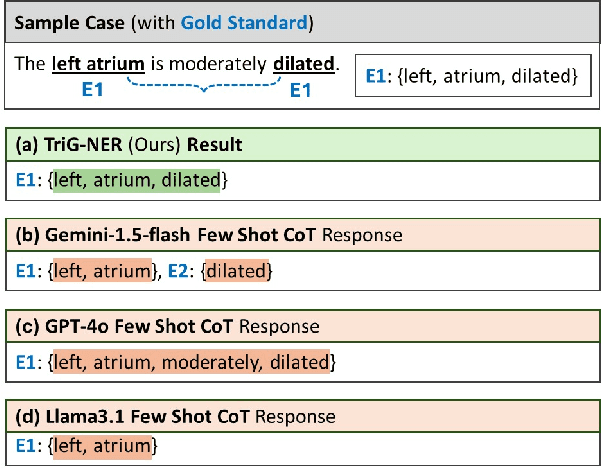
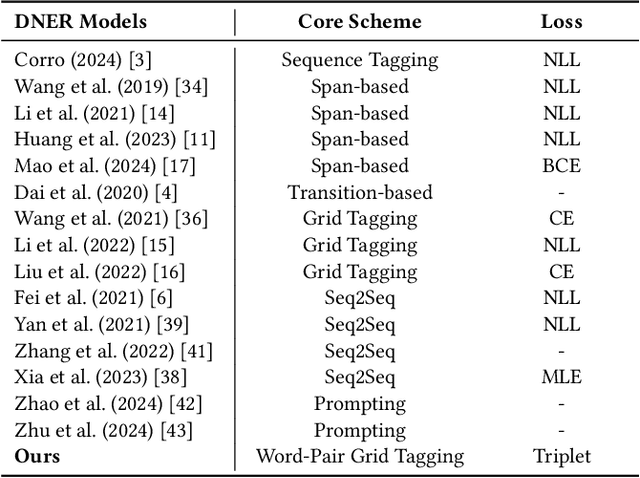
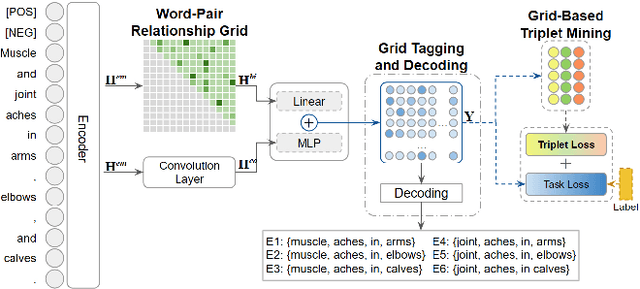
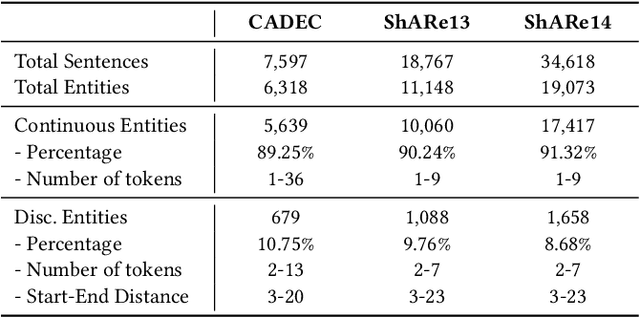
Discontinuous Named Entity Recognition (DNER) presents a challenging problem where entities may be scattered across multiple non-adjacent tokens, making traditional sequence labelling approaches inadequate. Existing methods predominantly rely on custom tagging schemes to handle these discontinuous entities, resulting in models tightly coupled to specific tagging strategies and lacking generalisability across diverse datasets. To address these challenges, we propose TriG-NER, a novel Triplet-Grid Framework that introduces a generalisable approach to learning robust token-level representations for discontinuous entity extraction. Our framework applies triplet loss at the token level, where similarity is defined by word pairs existing within the same entity, effectively pulling together similar and pushing apart dissimilar ones. This approach enhances entity boundary detection and reduces the dependency on specific tagging schemes by focusing on word-pair relationships within a flexible grid structure. We evaluate TriG-NER on three benchmark DNER datasets and demonstrate significant improvements over existing grid-based architectures. These results underscore our framework's effectiveness in capturing complex entity structures and its adaptability to various tagging schemes, setting a new benchmark for discontinuous entity extraction.
GEM-VPC: A dual Graph-Enhanced Multimodal integration for Video Paragraph Captioning
Oct 12, 2024



Video Paragraph Captioning (VPC) aims to generate paragraph captions that summarises key events within a video. Despite recent advancements, challenges persist, notably in effectively utilising multimodal signals inherent in videos and addressing the long-tail distribution of words. The paper introduces a novel multimodal integrated caption generation framework for VPC that leverages information from various modalities and external knowledge bases. Our framework constructs two graphs: a 'video-specific' temporal graph capturing major events and interactions between multimodal information and commonsense knowledge, and a 'theme graph' representing correlations between words of a specific theme. These graphs serve as input for a transformer network with a shared encoder-decoder architecture. We also introduce a node selection module to enhance decoding efficiency by selecting the most relevant nodes from the graphs. Our results demonstrate superior performance across benchmark datasets.
Multimodal Large Language Models and Tunings: Vision, Language, Sensors, Audio, and Beyond
Oct 08, 2024This tutorial explores recent advancements in multimodal pretrained and large models, capable of integrating and processing diverse data forms such as text, images, audio, and video. Participants will gain an understanding of the foundational concepts of multimodality, the evolution of multimodal research, and the key technical challenges addressed by these models. We will cover the latest multimodal datasets and pretrained models, including those beyond vision and language. Additionally, the tutorial will delve into the intricacies of multimodal large models and instruction tuning strategies to optimise performance for specific tasks. Hands-on laboratories will offer practical experience with state-of-the-art multimodal models, demonstrating real-world applications like visual storytelling and visual question answering. This tutorial aims to equip researchers, practitioners, and newcomers with the knowledge and skills to leverage multimodal AI. ACM Multimedia 2024 is the ideal venue for this tutorial, aligning perfectly with our goal of understanding multimodal pretrained and large language models, and their tuning mechanisms.
Do Text-to-Vis Benchmarks Test Real Use of Visualisations?
Jul 29, 2024



Large language models are able to generate code for visualisations in response to user requests. This is a useful application, and an appealing one for NLP research because plots of data provide grounding for language. However, there are relatively few benchmarks, and it is unknown whether those that exist are representative of what people do in practice. This paper aims to answer that question through an empirical study comparing benchmark datasets and code from public repositories. Our findings reveal a substantial gap in datasets, with evaluations not testing the same distribution of chart types, attributes, and the number of actions. The only representative dataset requires modification to become an end-to-end and practical benchmark. This shows that new, more benchmarks are needed to support the development of systems that truly address users' visualisation needs. These observations will guide future data creation, highlighting which features hold genuine significance for users.
3M-Health: Multimodal Multi-Teacher Knowledge Distillation for Mental Health Detection
Jul 12, 2024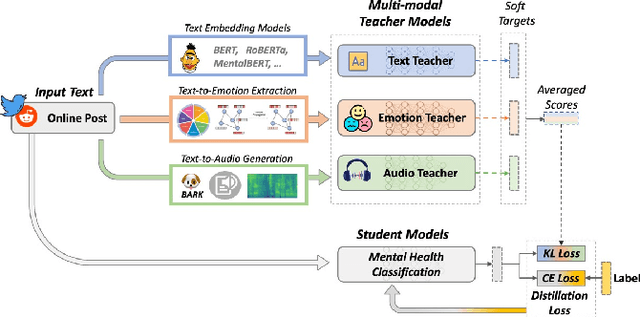
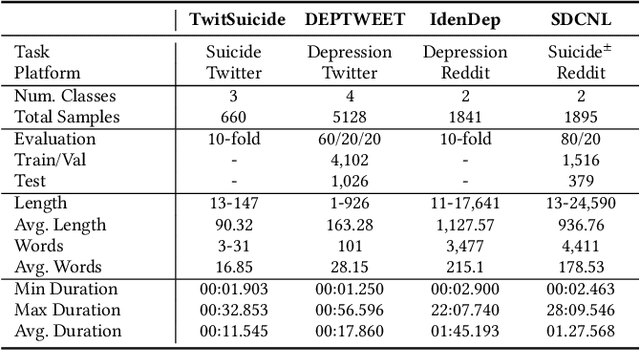
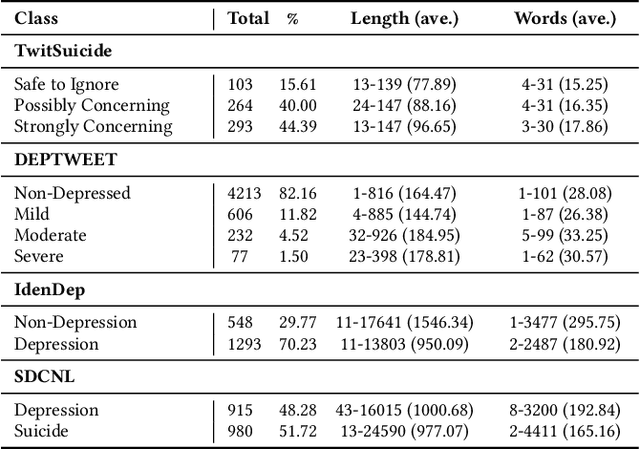
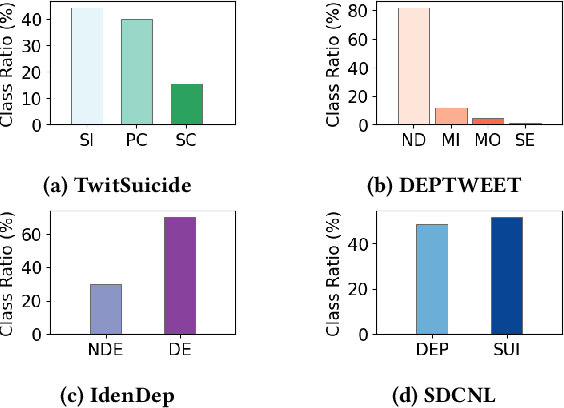
The significance of mental health classification is paramount in contemporary society, where digital platforms serve as crucial sources for monitoring individuals' well-being. However, existing social media mental health datasets primarily consist of text-only samples, potentially limiting the efficacy of models trained on such data. Recognising that humans utilise cross-modal information to comprehend complex situations or issues, we present a novel approach to address the limitations of current methodologies. In this work, we introduce a Multimodal and Multi-Teacher Knowledge Distillation model for Mental Health Classification, leveraging insights from cross-modal human understanding. Unlike conventional approaches that often rely on simple concatenation to integrate diverse features, our model addresses the challenge of appropriately representing inputs of varying natures (e.g., texts and sounds). To mitigate the computational complexity associated with integrating all features into a single model, we employ a multimodal and multi-teacher architecture. By distributing the learning process across multiple teachers, each specialising in a particular feature extraction aspect, we enhance the overall mental health classification performance. Through experimental validation, we demonstrate the efficacy of our model in achieving improved performance. All relevant codes will be made available upon publication.
Game-MUG: Multimodal Oriented Game Situation Understanding and Commentary Generation Dataset
Apr 30, 2024
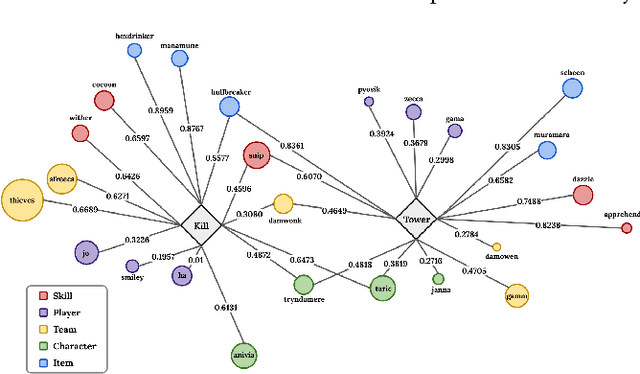
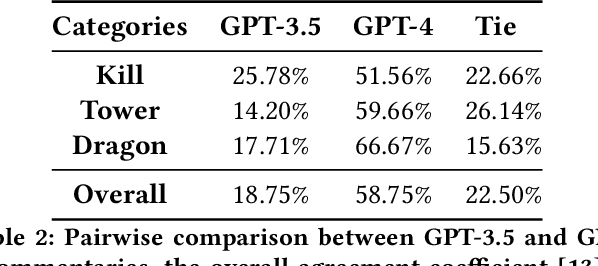
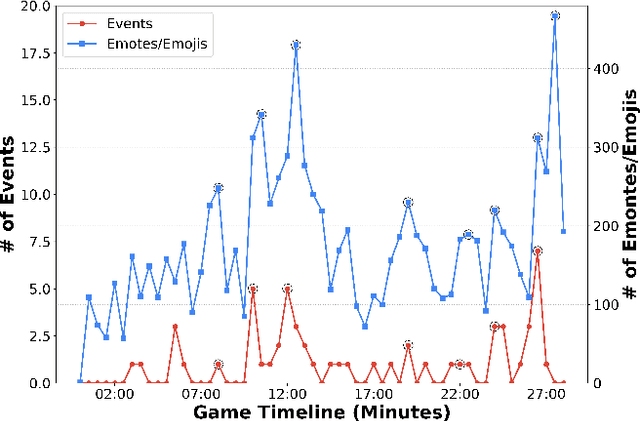
The dynamic nature of esports makes the situation relatively complicated for average viewers. Esports broadcasting involves game expert casters, but the caster-dependent game commentary is not enough to fully understand the game situation. It will be richer by including diverse multimodal esports information, including audiences' talks/emotions, game audio, and game match event information. This paper introduces GAME-MUG, a new multimodal game situation understanding and audience-engaged commentary generation dataset and its strong baseline. Our dataset is collected from 2020-2022 LOL game live streams from YouTube and Twitch, and includes multimodal esports game information, including text, audio, and time-series event logs, for detecting the game situation. In addition, we also propose a new audience conversation augmented commentary dataset by covering the game situation and audience conversation understanding, and introducing a robust joint multimodal dual learning model as a baseline. We examine the model's game situation/event understanding ability and commentary generation capability to show the effectiveness of the multimodal aspects coverage and the joint integration learning approach.
M3-VRD: Multimodal Multi-task Multi-teacher Visually-Rich Form Document Understanding
Feb 28, 2024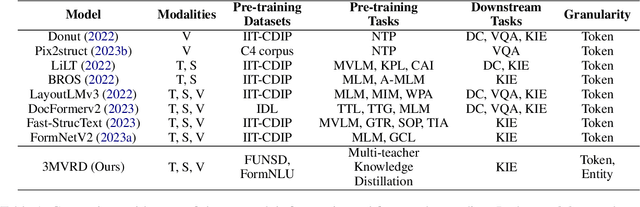
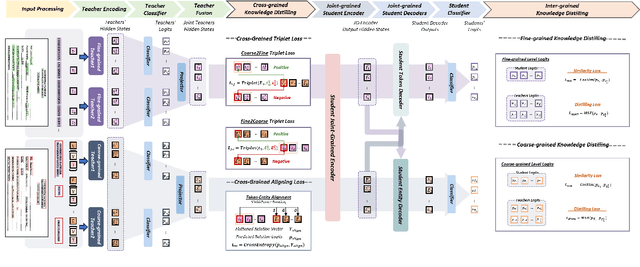
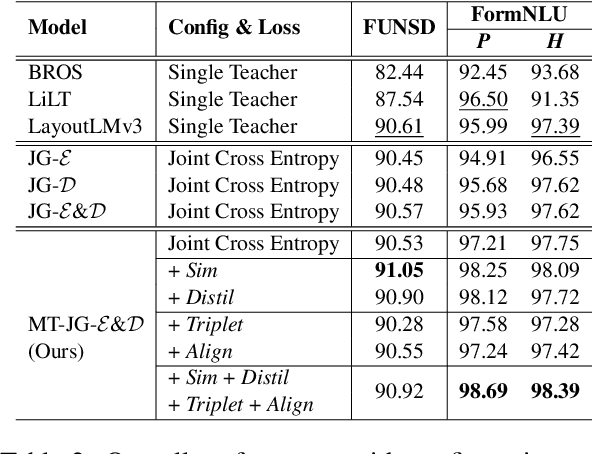
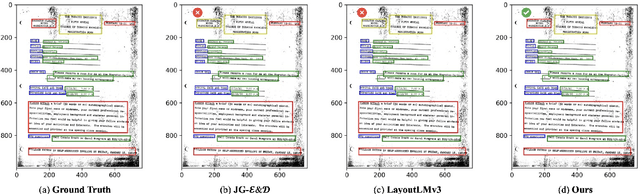
This paper presents a groundbreaking multimodal, multi-task, multi-teacher joint-grained knowledge distillation model for visually-rich form document understanding. The model is designed to leverage insights from both fine-grained and coarse-grained levels by facilitating a nuanced correlation between token and entity representations, addressing the complexities inherent in form documents. Additionally, we introduce new inter-grained and cross-grained loss functions to further refine diverse multi-teacher knowledge distillation transfer process, presenting distribution gaps and a harmonised understanding of form documents. Through a comprehensive evaluation across publicly available form document understanding datasets, our proposed model consistently outperforms existing baselines, showcasing its efficacy in handling the intricate structures and content of visually complex form documents.
SCO-VIST: Social Interaction Commonsense Knowledge-based Visual Storytelling
Feb 01, 2024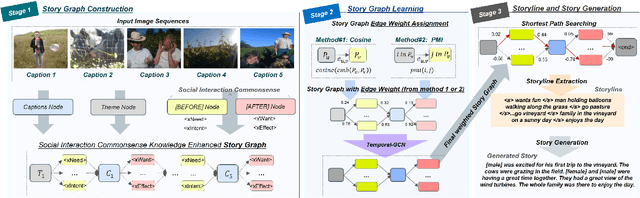

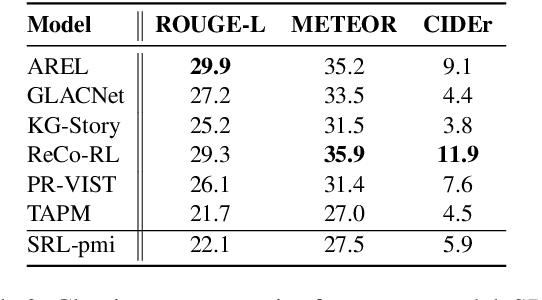
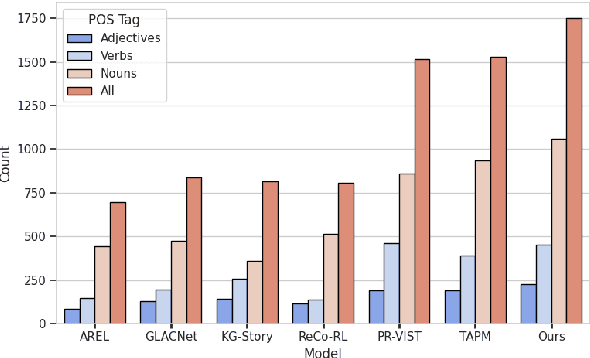
Visual storytelling aims to automatically generate a coherent story based on a given image sequence. Unlike tasks like image captioning, visual stories should contain factual descriptions, worldviews, and human social commonsense to put disjointed elements together to form a coherent and engaging human-writeable story. However, most models mainly focus on applying factual information and using taxonomic/lexical external knowledge when attempting to create stories. This paper introduces SCO-VIST, a framework representing the image sequence as a graph with objects and relations that includes human action motivation and its social interaction commonsense knowledge. SCO-VIST then takes this graph representing plot points and creates bridges between plot points with semantic and occurrence-based edge weights. This weighted story graph produces the storyline in a sequence of events using Floyd-Warshall's algorithm. Our proposed framework produces stories superior across multiple metrics in terms of visual grounding, coherence, diversity, and humanness, per both automatic and human evaluations.