 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge3M-Health: Multimodal Multi-Teacher Knowledge Distillation for Mental Health Detection
Paper and Code
Jul 12, 2024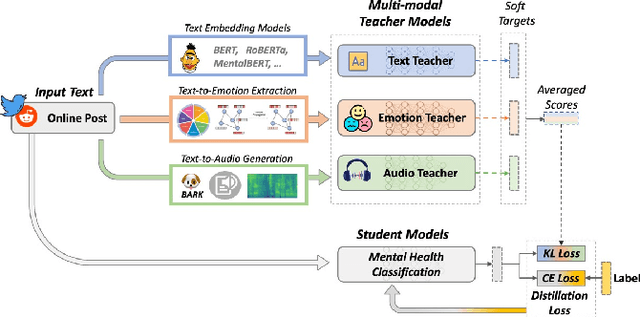
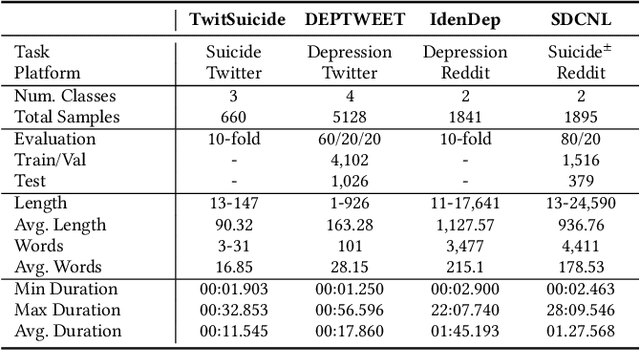
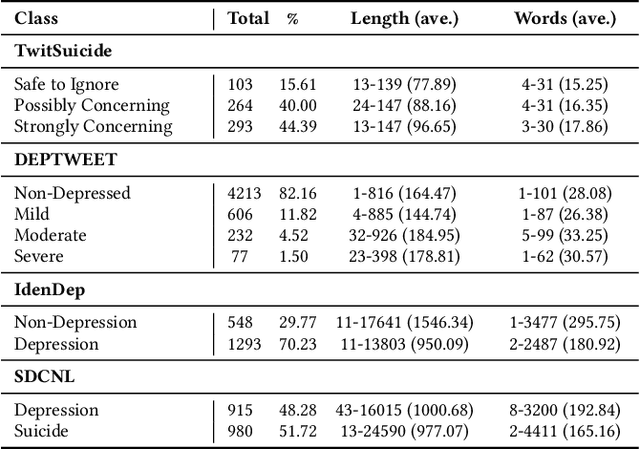
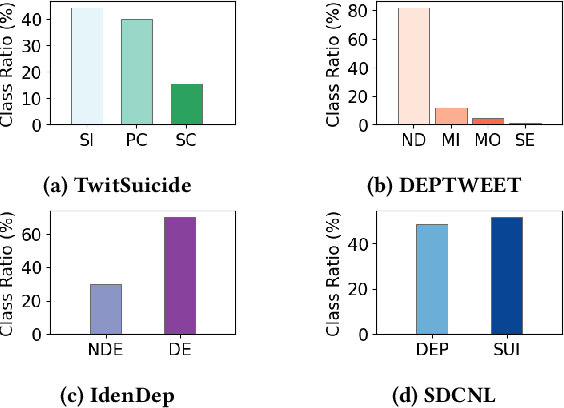
The significance of mental health classification is paramount in contemporary society, where digital platforms serve as crucial sources for monitoring individuals' well-being. However, existing social media mental health datasets primarily consist of text-only samples, potentially limiting the efficacy of models trained on such data. Recognising that humans utilise cross-modal information to comprehend complex situations or issues, we present a novel approach to address the limitations of current methodologies. In this work, we introduce a Multimodal and Multi-Teacher Knowledge Distillation model for Mental Health Classification, leveraging insights from cross-modal human understanding. Unlike conventional approaches that often rely on simple concatenation to integrate diverse features, our model addresses the challenge of appropriately representing inputs of varying natures (e.g., texts and sounds). To mitigate the computational complexity associated with integrating all features into a single model, we employ a multimodal and multi-teacher architecture. By distributing the learning process across multiple teachers, each specialising in a particular feature extraction aspect, we enhance the overall mental health classification performance. Through experimental validation, we demonstrate the efficacy of our model in achieving improved performance. All relevant codes will be made available upon publication.